

机器学习 F1-Score 精确率 - P 准确率 -Acc 召回率 - R
准确率 召回率 精确率 :
准确率->accuracy, 精确率->precision. 召回率-> recall. 三者很像,但是并不同,简单来说三者的目的对象并不相同。
大多时候我们需要将三者放到特定的任务环境中才会更加明显的感觉到三者的差异。
在介绍这些之前,我们先回顾一下我们的混淆矩阵。
- True Positive(真正, TP):将正类预测为正类数.
- True Negative(真负 , TN):将负类预测为负类数.
- False Positive(假正, FP):将负类预测为正类数 →→ 误报 (Type I error).
- False Negative(假负 , FN):将正类预测为负类数 →→ 漏报 (Type II error)
1)精确率:
实际上非常简单,精确率是对我们的预测结果而言的指标。其作用的主要范围主要是在我们的预测结果中。对于实际结果集的大小,并不在精确率的考虑中。
2)召回率
召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。
3)准确率(accuracy)
准确率(accuracy) =(TP+TN)/(TP+FN+FP+TN)
由上面三个公式可以看出来,我们三个指标所面向的目标集是不同的。其中很明显看出来P是面向我们所选中的XP样本,也就是说是面向我们的预测结果,而召回率面向的是之前中应该本选中的样本,也就是本身的应该被选中的样本集而言。而准确率则是面向的所有不该选中和应该被选中的样本。
4)F1-Score:
从上面的P和R的公式中,很容易发现,两者的存在可能会有一定的矛盾,很难实现双高的情况,为了兼顾这两个指标,我们提出了F1-Score:
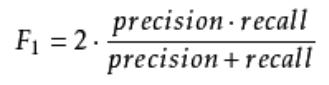
其中还出现了其他的F系参数,如F贝塔等等。

