

cuda学习
1. cuda-runtime-api
1.1 cuda-runtime
- CUDA Runtime是封装了CUDA Driver的高级别更友好的API
- cudaruntime需要引入cudart这个so库文件, 和
cuda_runtime.h头文件 - 上下文管理:
- 3.1. 使用cuDevicePrimaryCtxRetain为每个设备设置context,不再手工管理context,并且不提供直接管理context的API
- 3.2. 任何依赖CUcontext的API被调用时,会触发CUcontext的创建和对设备的绑定
- 此后任何API调用时,会以设备id为基准,调取绑定好的CUcontext
- 因此被称为懒加载模式,避免了手动维护CUcontext的麻烦
- cuda的状态返回值,都是cudaError_t类型,通过check宏捕获状态并处理是一种通用方式
下面是一段简单的示例代码:
// CUDA运行时头文件
#include <cuda_runtime.h>
// CUDA驱动头文件
#include <cuda.h>
#include <stdio.h>
#include <string.h>
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
int main(){
CUcontext context = nullptr;
cuCtxGetCurrent(&context);
printf("Current context = %p,当前无context\n", context);
// cuda runtime是以cuda为基准开发的运行时库
// cuda runtime所使用的CUcontext是基于cuDevicePrimaryCtxRetain函数获取的
// 即,cuDevicePrimaryCtxRetain会为每个设备关联一个context,通过cuDevicePrimaryCtxRetain函数可以获取到
// 而context初始化的时机是懒加载模式,即当你调用一个runtime api时,会触发创建动作
// 也因此,避免了cu驱动级别的init和destroy操作。使得api的调用更加容易
int device_count = 0;
checkRuntime(cudaGetDeviceCount(&device_count));
printf("device_count = %d\n", device_count);
// 取而代之,是使用setdevice来控制当前上下文,当你要使用不同设备时
// 使用不同的device id
// 注意,context是线程内作用的,其他线程不相关的, 一个线程一个context stack
int device_id = 0;
printf("set current device to : %d,这个API依赖CUcontext,触发创建并设置\n", device_id);
checkRuntime(cudaSetDevice(device_id));
// 注意,是由于set device函数是“第一个执行的需要context的函数”,所以他会执行cuDevicePrimaryCtxRetain
// 并设置当前context,这一切都是默认执行的。注意:cudaGetDeviceCount是一个不需要context的函数
// 你可以认为绝大部分runtime api都是需要context的,所以第一个执行的cuda runtime函数,会创建context并设置上下文
cuCtxGetCurrent(&context);
printf("SetDevice after, Current context = %p,获取当前context\n", context);
int current_device = 0;
checkRuntime(cudaGetDevice(¤t_device));
printf("current_device = %d\n", current_device);
return 0;
}
1.2 memory
1.2.1 cpu和gpu内存模型理解
关于内存模型,内存大局上分为. (请参照 https://www.bilibili.com/video/BV1jX4y1w7Um)
-
主机内存:Host Memory,也就是CPU内存(内存条)。对于内存条,操作系统区分为两个大类(逻辑区分,物理上是同一个东西):
-
Pageable memory,可分页内存
-
Page locked memory,页锁定内存
-
-
设备内存:Device Memory,也就是GPU内存,显存
- 设备内存又分为:
- 全局内存(3):Global Memory
- 寄存器内存(1):Register Memory
- 纹理内存(2):Texture Memory
- 共享内存(2):Shared Memory
- 常量内存(2):Constant Memory
- 本地内存(3):Local Memory
- 只需要知道,谁距离计算芯片近,谁速度就越快,空间越小,价格越贵
- 清单的括号数字表示到计算芯片的距离
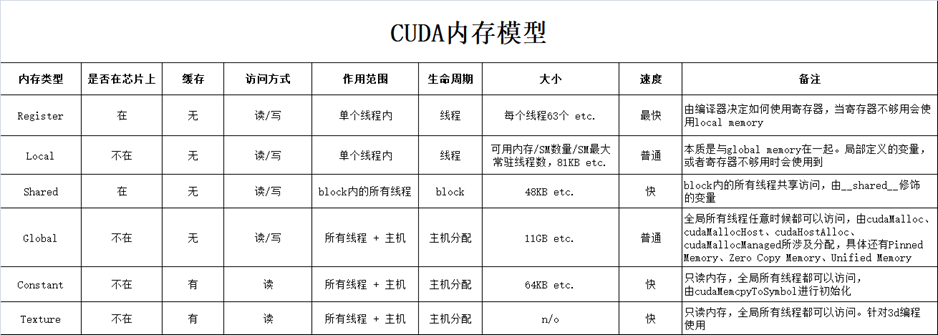
- 清单的括号数字表示到计算芯片的距离
- 设备内存又分为:
上述cpu和gpu内存中,主要理解pinned memory、global memory、shared memory即可,其他不常用。关于pinned memory可以总结如下:
(可以理解为Page locked memory是vip房间,锁定给你一个人用。而Pageable memory是普通房间,在酒店房间不够的时候,选择性的把你的房间腾出来给其他人交换用,这就可以容纳更多人了。造成房间很多的假象,代价是性能降低)
-
1.pinned memory具有锁定特性,是稳定不会被交换的(这很重要,相当于每次去这个房间都一定能找到你)
-
2.pageable memory没有锁定特性,对于第三方设备(比如GPU),去访问时,因为无法感知内存是否被交换,可能得不到正确的数据(每次去房间找,说不准你的房间被人交换了)
-
3.pageable memory的性能比pinned memory差,很可能降低你程序的优先级然后把内存交换给别人用
-
4.pageable memory策略能使用内存假象,实际8GB但是可以使用15GB,提高程序运行数量(不是速度)
-
5.pinned memory太多,会导致操作系统整体性能降低(程序运行数量减少),8GB就只能用8GB。注意不是你的应用程序性能降低,这一点一般都是废话,不用当回事
-
6.GPU可以直接访问pinned memory而不能访问pageable memory因为第二条)
1.2.1 cpu和gpu内存模型使用
-
通过
cudaMalloc()函数分配GPU内存,分配到setDevice指定的当前设备上 -
通过
cudaMallocHost()函数分配page locked memory,即pinned memory,页锁定内存- 页锁定内存是主机内存,CPU可以直接访问
- 页锁定内存也可以被GPU直接访问,使用DMA(Direct Memory Access)技术
- 注意这么做的性能会比较差,因为主机内存距离GPU太远,隔着PCIE等,不适合大量数据传输
- 页锁定内存是物理内存,过度使用会导致系统性能低下(导致虚拟内存等一系列技术变慢)
-
**
cudaMemcpy()函数的理解: **需要区分host是否是页锁定内存,区别如下:- 如果host不是页锁定内存,则:
- Device To Host的过程,等价于
- pinned = cudaMallocHost
- copy Device to pinned
- copy pinned to Host
- free pinned
- Host To Device的过程,等价于
- pinned = cudaMallocHost
- copy Host to pinned
- copy pinned to Device
- free pinned
- Device To Host的过程,等价于
- 如果host是页锁定内存,则:
- Device To Host的过程,等价于
- copy Device to Host
- Host To Device的过程,等价于
- copy Host to Device
- Device To Host的过程,等价于
两个过程的区别就是下面这张图:
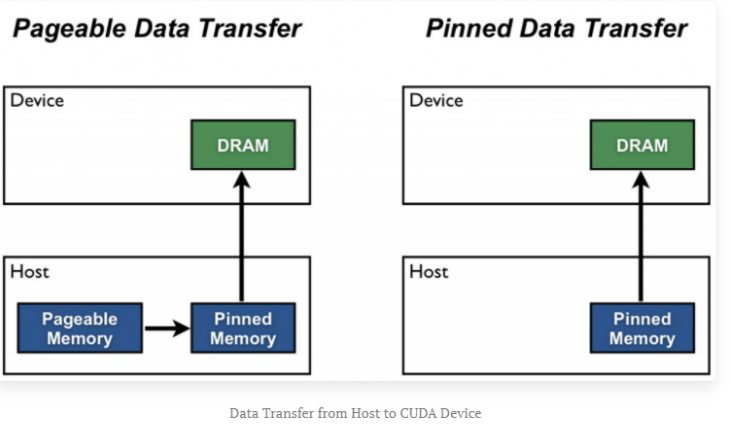
- 如果host不是页锁定内存,则:
下面是一段内存分配和使用的代码, 主要做了如下的流程:
- 在gpu上开辟一块空间,并把地址记录在mem_device上
- 在cpu上开辟一块空间,并把地址记录在mem_host上,并修改了该地址所指区域的第二个值
- 把mem_host所指区域的数据都复制到mem_device的所指区域
- 在cpu上开辟一块空间,并把地址记录在mem_page_locked上
- 最后把mem_device所指区域的数据又复制回cpu上的mem_page_locked区域
// CUDA运行时头文件
#include <cuda_runtime.h>
#include <stdio.h>
#include <string.h>
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
int main(){
int device_id = 0;
checkRuntime(cudaSetDevice(device_id));
float* memory_device = nullptr;
checkRuntime(cudaMalloc(&memory_device, 100 * sizeof(float))); // pointer to device
float* memory_host = new float[100];
memory_host[2] = 520.25;
checkRuntime(cudaMemcpy(memory_device, memory_host, sizeof(float) * 100, cudaMemcpyHostToDevice)); // 返回的地址是开辟的device地址,存放在memory_device
float* memory_page_locked = nullptr;
checkRuntime(cudaMallocHost(&memory_page_locked, 100 * sizeof(float))); // 返回的地址是被开辟的pin memory的地址,存放在memory_page_locked
checkRuntime(cudaMemcpy(memory_page_locked, memory_device, sizeof(float) * 100, cudaMemcpyDeviceToHost)); //
printf("%f\n", memory_page_locked[2]);
checkRuntime(cudaFreeHost(memory_page_locked));
delete [] memory_host;
checkRuntime(cudaFree(memory_device));
return 0;
}
1.2.3 内存释放
- 建议先分配先释放:
checkRuntime(cudaFreeHost(memory_page_locked));
delete [] memory_host;
checkRuntime(cudaFree(memory_device));
使用cuda API来分配内存的一般都有自己对应的释放内存方法;而使用new来分配的使用delete来释放
1.2.4 总结
1.GPU可以直接访问pinned memory,称之为(DMA Direct Memory Access)
2.对于GPU访问而言,距离计算单元越近,效率越高,所以PinnedMemory<GlobalMemory<SharedMemory
3.代码中,由new、malloc分配的,是pageable memory,由cudaMallocHost分配的是PinnedMemory,由cudaMalloc分配的是GlobalMemory
4.尽量多用PinnedMemory储存host数据,或者显式处理Host到Device时,用PinnedMemory做缓存,都是提高性能的关键
1.3 stream
1.3.1 stream 定义理解
stream是一个流句柄,可以当做是一个任务队列,是进行异步控制的主要方式:
- 主函数调用异步函数,就相当于往流中添加任务,cuda执行器会从流队列中顺序取任务进行执行,主函数无需等待任务完成,从而实现异步执行
- 流是一种基于context之上的任务管道抽象,一个context可以创建n个流;nullptr表示默认流,每个线程都有自己的默认流。
一个方便理解的示例图如下:
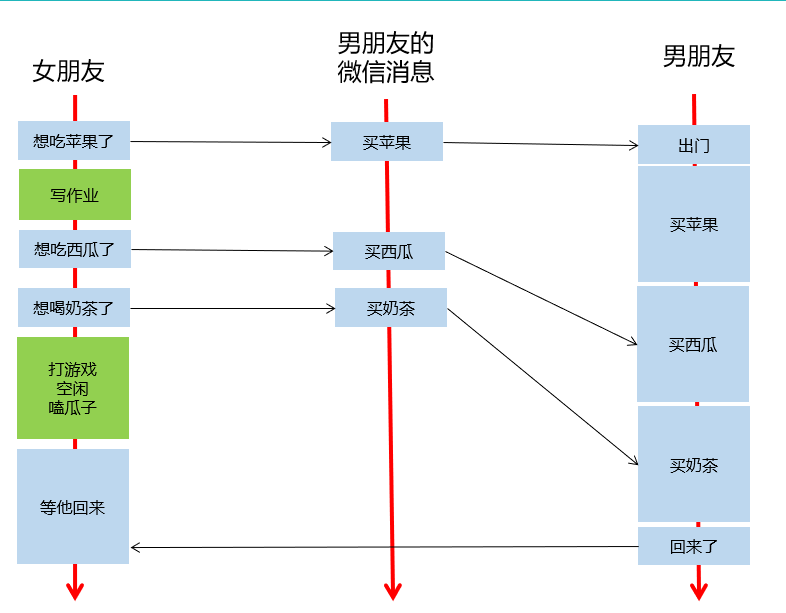
1.上图中,男朋友的微信消息,就是任务队列,流的一种抽象
2.女朋友发出指令后,他可以做任何事情,无需等待指令执行完毕,(指令发出的耗时也是极短的),即异步操作:加入流的队列后,立即返回,不耽误时间
3.女朋友发的指令被送到流中排队,男朋友根据流的队列,顺序执行
4.女朋友选择性,在需要的时候等待所有的执行结果
5.新建一个流,就是新建一个男朋友,给他发指令就是给他发微信,你可以新建很多个男朋友
6.通过cudaEvent可以选择性等待任务队列中的部分任务是否就绪
1.3.2 stream 特性
-
stream是一个流句柄,可以当做是一个任务队列,有如下特性
- 异步添加:使用到了stream的函数,向stream中加入指令后立即返回,并不会等待指令执行结束,例如
cudaMemcpyAsync()函数等同于向stream这个队列中加入一个cudaMemcpy指令并排队 - 顺序执行:cuda执行器会从stream队列中一条条的读取并执行指令
- 选择性等待:当需要等待流中任务执行完成时,可以调用
cudaStreamSynchronize(stream)函数,等待stream中所有指令执行完毕,也就是队列为空
- 异步添加:使用到了stream的函数,向stream中加入指令后立即返回,并不会等待指令执行结束,例如
-
使用stream时,要注意
- 由于异步函数会立即返回,因此传递进入的参数要考虑其生命周期,应确认函数调用结束后再做释放。指令发出后,流队列中储存的是指令参数,不能加入队列后立即释放参数指针,这会导致流队列执行该指令时指针失效而出错
-
还可以向stream中加入Event,用以监控是否到达了某个检查点
cudaEventCreate,创建事件cudaEventRecord,记录事件,即在stream中加入某个事件,当队列执行到该事件后,修改其状态cudaEventQuery,查询事件当前状态cudaEventElapsedTime,计算两个事件之间经历的时间间隔,若要统计某些核函数执行时间,请使用这个函数,能够得到最准确的统计cudaEventSynchronize,同步某个事件,等待事件到达cudaStreamWaitEvent,等待流中的某个事件
-
默认流,对于
cudaMemcpy()等同步函数,其等价于执行了- cudaMemcpyAsync(... 默认流) 加入队列
- cudaStreamSynchronize(默认流) 等待执行完成
- 默认流与当前设备上下文类似,是与当前设备进行的关联
- 因此,如果大量使用默认流,会导致性能低下
-
创建和销毁流:
-
cudaStreamDestroy(stream): 销毁创建的流 -
//创建流 cudaStream_t stream = nullptr; checkRuntime(cudaStreamCreate(&stream));
-
下面是一段stream使用的代码
// CUDA运行时头文件
#include <cuda_runtime.h>
#include <stdio.h>
#include <string.h>
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
int main(){
int device_id = 0;
checkRuntime(cudaSetDevice(device_id));
cudaStream_t stream = nullptr;
checkRuntime(cudaStreamCreate(&stream));
// 在GPU上开辟空间
float* memory_device = nullptr;
checkRuntime(cudaMalloc(&memory_device, 100 * sizeof(float)));
// 在CPU上开辟空间并且放数据进去,将数据复制到GPU
float* memory_host = new float[100];
memory_host[2] = 520.25;
checkRuntime(cudaMemcpyAsync(memory_device, memory_host, sizeof(float) * 100, cudaMemcpyHostToDevice, stream)); // 异步复制操作,主线程不需要等待复制结束才继续
// 在CPU上开辟pin memory,并将GPU上的数据复制回来
float* memory_page_locked = nullptr;
checkRuntime(cudaMallocHost(&memory_page_locked, 100 * sizeof(float)));
checkRuntime(cudaMemcpyAsync(memory_page_locked, memory_device, sizeof(float) * 100, cudaMemcpyDeviceToHost, stream)); // 异步复制操作,主线程不需要等待复制结束才继续
checkRuntime(cudaStreamSynchronize(stream));
printf("%f\n", memory_page_locked[2]);
// 释放内存
checkRuntime(cudaFreeHost(memory_page_locked));
checkRuntime(cudaFree(memory_device));
checkRuntime(cudaStreamDestroy(stream));
delete [] memory_host;
return 0;
}
1.4 kernel function核函数
1.4.1 核函数
cuda核函数:指交给gpu运行的代码,一般为.cu文件。.cu文件可以当做正常cpp写即可,他是cpp的超集,兼容支持cpp的所有特性,.cu文件和正常cpp文件区别如下:
- .cu文件需要用nvcc编译。(在.vscode/settings.json中配置*.cu : cuda-cpp,可以使得代码被正确解析)
- cu文件中引入了一些新的符号和语法:
__global__标记,核函数标记- 调用方必须是host
- 返回值必须是void
- 例如:
__global__ void kernel(const float* pdata, int ndata) - 必须以
kernel<<<gridDim, blockDim, bytesSharedMemorySize, stream>>>(pdata, ndata)的方式启动- 其参数类型是:
<<<dim3 gridDim, dim3 blockDim, size_t bytesSharedMemorySize, cudaStream_t stream>>>- dim3有构造函数dim3(int x, int y=1, int z=1)
- 因此当直接赋值为int时,实则定义了dim.x = value, dim.y = 1, dim.z = 1
- dim3有构造函数dim3(int x, int y=1, int z=1)
- 其中gridDim, blockDim, bytesSharedMemory, stream是线程layout参数
- 如果指定了stream,则把核函数加入到stream中异步执行
- pdata和ndata则是核函数的函数调用参数
- 函数调用参数必须传值,不能传引用等。参数可以是类类型等
- 其参数类型是:
- 核函数的执行无论stream是否为nullptr,都将是异步执行
- 因此在核函数中进行printf操作,你必须进行等待,例如cudaDeviceSynchronize、或者cudaStreamSynchronize,否则你将无法看到打印的信息
__device__标记,设备调用的函数- 调用方必须是device
__host__标记,主机调用函数- 调用方必须是主机
- 也可以
__device__ __host__两个标记同时有,表明该函数可以设备也可以主机 __constant__标记,定义常量内存__shared__标记,定义共享内存
下面是一个cuda程序示例:

3.4.2 thread, grid, block 和 threadIdx
核函数中,thread, grid, block这几个概念需要搞清楚。首先,先不严谨地认为,GPU相当于一个立方体,这个立方体有很多小方块,每个小块都是一个thread,如下图
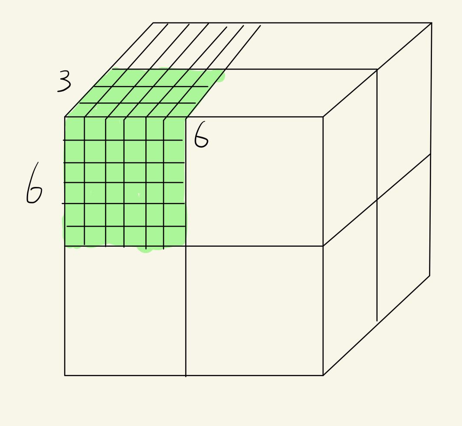
为了讨论方便,我们只考虑2D,如下图:
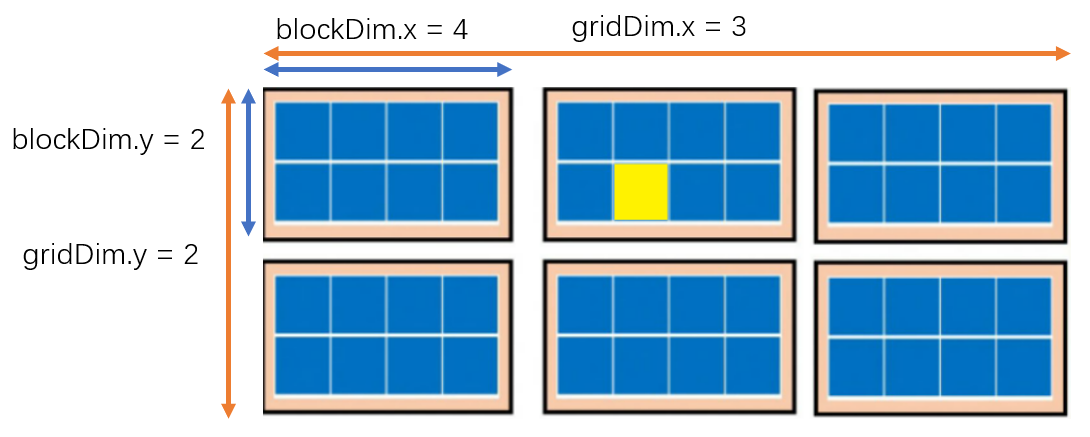
所以总结下,可以认为一个每次执行一个核函数,以用一个grid, 这个grid包含多个block,每个block又包含多个thread(block的一个小方格就是一个thread), 上图中的grid,包含6个block,每个block包含8个thread,相当于有48个thread线程同时执行。
在写核函数时,我们关心的是某一个thread的索引位置,比如说上图中黄色方块对应的thread,如果将这个2D展开成1D,这个黄色thread 的1D位置是 13,即48个线程中的第13个。编程时它的索引位置如何计算呢?
内建变量
写核函数时,有四个内置变量(buildin变量)给我们计算thread的索引,所有核函数都可以访问,其取值由执行器维护和改变, 四个变量如下:
- gridDim[x, y, z]:网格维度,是核函数启动时指定的。(即一个grid中有多少个block,如上图中gridDim.x=3,表示x维度有3个block,gridDim.y=2表示y维度有2个block )
- blockDim[x, y, z]:块维度,是核函数启动时指定的。(即一个block中有多少个thread,如上图中blockDim.x=4表示x维度有4个threadd,blockDim.y=2表示y维度有2个thread )
- blockIdx[x, y, z]:块索引,对应最大值是gridDim,由执行器根据当前执行的线程进行赋值,核函数内访问时已经被配置好。 (即grid中的第几个block)
- threadIdx[x, y, z]:线程索引,对应最大值是blockDim,由执行器根据当前执行的线程进行赋值,核函数内访问时已经被配置好. (即block中的第几个thread)
需要注意的是:Dim是固定的,启动后不会改变,并且是Idx的最大值。每个Dim都具有x、y、z三个维度,默认为1。
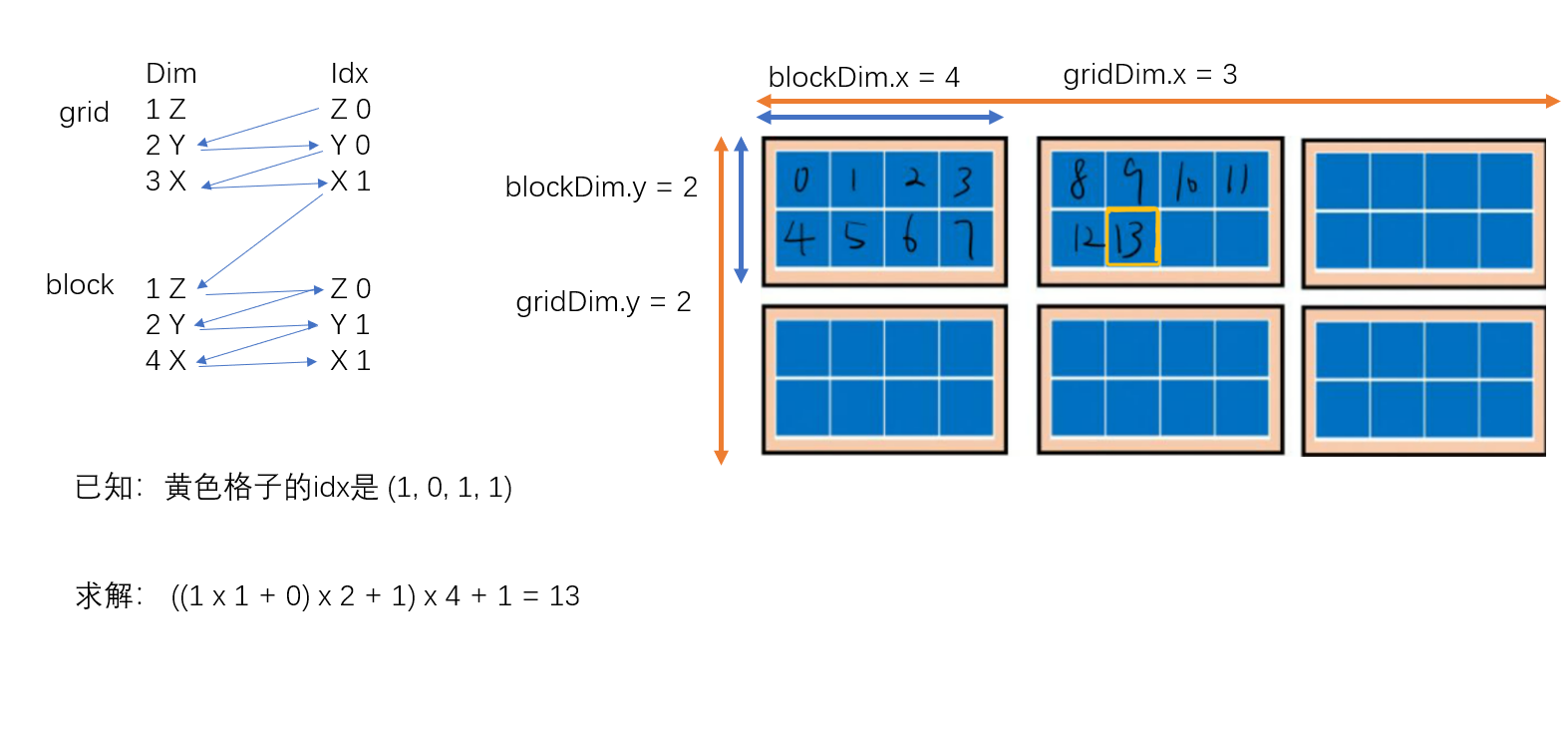
再回到上述计算索引的问题,上图中黄色方块对应的thread,根据四个内建变量,可以知道:
-
它在2D的位置是(blockIdx.x, blockIdx.y, threadIdx.x, threadIdx.y) =(1, 0, 1, 1)
-
则索引计算如下:
-
有一个统一的索引计算公式为:
# 按照下图中箭头的方向,乘左边的dim,加右边的idx int idx = ((((blockIdx.z*gridDim.y+blockIdx.y)*gridkDim.x + blockIdx.x)*blockDim.z+threadIdx.z)*blockDim.y+threadIdx.y)*blockDIm.x+threadIdx.x # 用代码表示如下: dims = [gridDim.z, gridDim.y, gridDim.x, blockDim.z, blockDim.y, blockDim.x] indexs = [blockIdx.z, blockIdx.y, blockIdx.x, threadIdx.z, threadIdx.y, threadIdx.x] position = 0 for i in range(6): position *= dims[i] position += indexs[i] -
上述公式中dims=[1, 2, 3, 1, 2, 4], indexs=[0, 0, 1, 0, 1, 1], 可以简化为:
- int idx = threadIdx.x + (blockIdx.x * blockDim.y+ thredIdx.y)*blockDim.x; 其表示的含义是要求thread的1D idx,先得知道在第几个block里,再知道在这个block里的第几个thread
-
下图是一个详细的计算过程解释:
下图是对上述cuda核函数中thread排布的一个总结:

下面是一段核函数代码
main.cpp
#include <cuda_runtime.h>
#include <stdio.h>
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
void test_print(const float* pdata, int ndata);
int main(){
float* parray_host = nullptr;
float* parray_device = nullptr;
int narray = 10;
int array_bytes = sizeof(float) * narray;
parray_host = new float[narray];
checkRuntime(cudaMalloc(&parray_device, array_bytes));
for(int i = 0; i < narray; ++i)
parray_host[i] = i;
checkRuntime(cudaMemcpy(parray_device, parray_host, array_bytes, cudaMemcpyHostToDevice));
test_print(parray_device, narray);
checkRuntime(cudaDeviceSynchronize());
checkRuntime(cudaFree(parray_device));
delete[] parray_host;
return 0;
}
kernel.cu
#include <stdio.h>
#include <cuda_runtime.h>
__global__ void test_print_kernel(const float* pdata, int ndata){
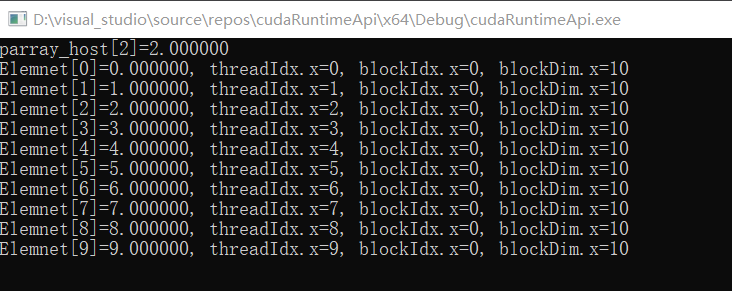
int idx = threadIdx.x + blockIdx.x * blockDim.x;
/* dims indexs
gridDim.z blockIdx.z
gridDim.y blockIdx.y
gridDim.x blockIdx.x
blockDim.z threadIdx.z
blockDim.y threadIdx.y
blockDim.x threadIdx.x
Pseudo code:
position = 0
for i in 6:
position *= dims[i]
position += indexs[i]
*/
printf("Element[%d] = %f, threadIdx.x=%d, blockIdx.x=%d, blockDim.x=%d\n", idx, pdata[idx], threadIdx.x, blockIdx.x, blockDim.x);
}
void test_print(const float* pdata, int ndata){
// <<<gridDim, blockDim, bytes_of_shared_memory, stream>>>
test_print_kernel<<<1, ndata, 0, nullptr>>>(pdata, ndata);
// 在核函数执行结束后,通过cudaPeekAtLastError获取得到的代码,来知道是否出现错误
// cudaPeekAtLastError和cudaGetLastError都可以获取得到错误代码
// cudaGetLastError是获取错误代码并清除掉,也就是再一次执行cudaGetLastError获取的会是success
// 而cudaPeekAtLastError是获取当前错误,但是再一次执行 cudaPeekAtLastError 或者 cudaGetLastError 拿到的还是那个错
// cuda的错误会传递,如果这里出错了,不移除。那么后续的任意api的返回值都会是这个错误,都会失败
cudaError_t code = cudaPeekAtLastError();
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("kernel error %s:%d test_print_kernel failed. \n code = %s, message = %s\n", __FILE__, __LINE__, err_name, err_message);
}
}
程序输出如下:
1.4.3 其他
- 通过cudaPeekAtLastError/cudaGetLastError函数,可以捕获核函数是否出现错误或者异常
- cudaGetLastError是获取错误代码并清除掉,也就是再一次执行cudaGetLastError获取的会是success
- cudaPeekAtLastError是获取当前错误,但是再一次执行cudaPeekAtLastError或者cudaGetLastErro拿到的还是那个错
- 两者的区别就类似于栈的peek和pop操作
1.5 thread layout
上述核函数调用时,尖括号里面需要四个参数, 其中设置gridDim和blockDim,就定义了多少个thread并行执行,以及这些thread的排布(layout)
kernel_function<<<dim3 gridDim, dim3 blockDim, size_t bytesSharedMemorySize, cudaStream_t stream>>>()
- gridDim: 多少个block
- blockDim: 每个block多少个thread
- bytesSharedMemorySize: shared memory的大小
- stream:流队列
关于layout的4个内建变量的关系
- gridDim是layout维度,其对应的索引是blockIdx
- blockIdx的最大值是0到gridDim-1
- blockDim是layout维度,其对应的索引是threadIdx
- threadIdx的最大值是0到blockDim-1
- blockDim维度乘积必须小于等于maxThreadsPerBlock
- gridDim、blockDim为维度,启动核函数后是固定的
- blockIdx、threadIdx为索引,启动核函数后,枚举每一个维度值,不同线程取值不同
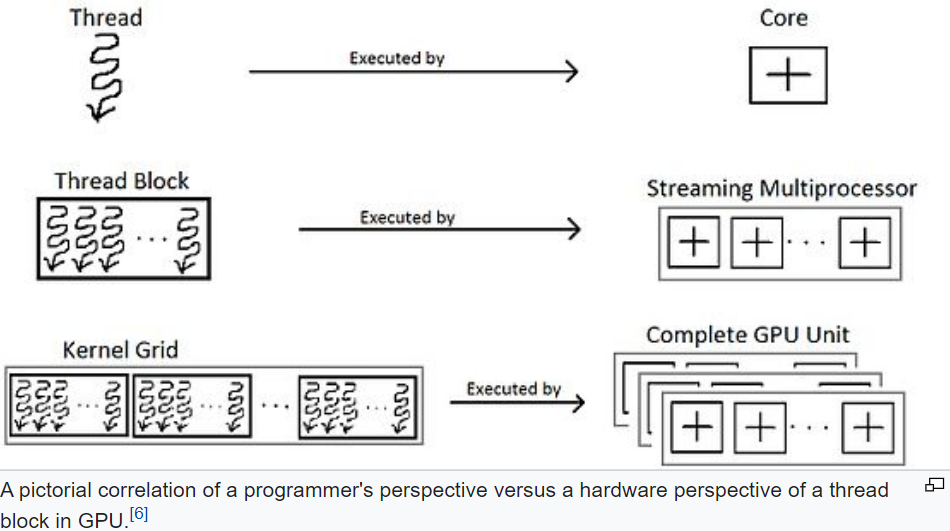
一个kernel函数和对应的gpu硬件单元关系如下:
最大值
layout设置时,不能超过对应的最大值:
- maxGridSize对应gridDim的取值最大值
- maxThreadsDim对应blockDim的取值最大值
- warpSize对应线程束中的线程数量
- maxThreadsPerBlock:对应blockDim元素乘积最大值, 即一个block中能够容纳的最大线程数,也就是说blockDims[0] * blockDims[1] * blockDims[2] <= maxThreadsPerBlock
可以通过下面代码获取:
cudaDeviceProp prop;
checkRuntime(cudaGetDeviceProperties(&prop, 0));
printf("prop.maxGridSize = %d, %d, %d\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf("prop.maxThreadsDim = %d, %d, %d\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf("prop.warpSize = %d\n", prop.warpSize);
printf("prop.maxThreadsPerBlock = %d\n", prop.maxThreadsPerBlock);
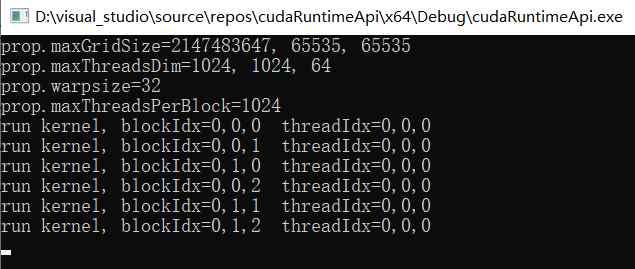
下面是一段kernel 函数示例代码和其输出:
main.cpp
#include <cuda_runtime.h>
#include <stdio.h>
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
void launch(int* grids, int* blocks);
int main(){
cudaDeviceProp prop;
checkRuntime(cudaGetDeviceProperties(&prop, 0));
// 通过查询maxGridSize和maxThreadsDim参数,得知能够设计的gridDims、blockDims的最大值
// warpSize则是线程束的线程数量
// maxThreadsPerBlock则是一个block中能够容纳的最大线程数,也就是说blockDims[0] * blockDims[1] * blockDims[2] <= maxThreadsPerBlock
printf("prop.maxGridSize = %d, %d, %d\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf("prop.maxThreadsDim = %d, %d, %d\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf("prop.warpSize = %d\n", prop.warpSize);
printf("prop.maxThreadsPerBlock = %d\n", prop.maxThreadsPerBlock);
int grids[] = {1, 2, 3}; // gridDim.x gridDim.y gridDim.z
int blocks[] = {1024, 1, 1}; // blockDim.x blockDim.y blockDim.z
launch(grids, blocks); // grids表示的是有几个大格子,blocks表示的是每个大格子里面有多少个小格子
checkRuntime(cudaPeekAtLastError()); // 获取错误 code 但不清楚error
checkRuntime(cudaDeviceSynchronize()); // 进行同步,这句话以上的代码全部可以异步操作
// printf("done\n");
return 0;
}
limits_thread.cu
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void demo_kernel(){
if(blockIdx.x == 0 && threadIdx.x == 0)
printf("Run kernel. blockIdx = %d,%d,%d threadIdx = %d,%d,%d\n",
blockIdx.x, blockIdx.y, blockIdx.z,
threadIdx.x, threadIdx.y, threadIdx.z
);
}
void launch(int* grids, int* blocks){
dim3 grid_dims(grids[0], grids[1], grids[2]);
dim3 block_dims(blocks[0], blocks[1], blocks[2]);
demo_kernel<<<grid_dims, block_dims, 0, nullptr>>>();
}
1.6 vector-add
- 对于一维数组时,采用只定义layout的x维度,若处理的是二维,则可以考虑定义x、y维度,例如处理的是图像
- blockDIm和gridDim的取值
- blockDIm: 一般可以直接给512、256,性能就是比较不错的
- gridDim:根据blockDIm来计算,一般:
gridDim=(input_size + block_size - 1) / block_size;(向上取整)
写一个核函数,实现gpu上的向量加法, 下面是示例代码:
kernel.cu
#include <stdio.h>
#include <cuda_runtime.h>
__global__ void vector_add_kernel(const float* a, const float* b, float* c, int ndata){
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if(idx >= ndata) return;
/* dims indexs
gridDim.z blockIdx.z
gridDim.y blockIdx.y
gridDim.x blockIdx.x
blockDim.z threadIdx.z
blockDim.y threadIdx.y
blockDim.x threadIdx.x
Pseudo code:
position = 0
for i in 6:
position *= dims[i]
position += indexs[i]
*/
c[idx] = a[idx] + b[idx];
}
void vector_add(const float* a, const float* b, float* c, int ndata){
const int nthreads = 512;
int block_size = ndata < nthreads ? ndata : nthreads; // 如果ndata < nthreads 那block_size = ndata就够了
int grid_size = (ndata + block_size - 1) / block_size; // 其含义是我需要多少个blocks可以处理完所有的任务
printf("block_size = %d, grid_size = %d\n", block_size, grid_size);
vector_add_kernel<<<grid_size, block_size, 0, nullptr>>>(a, b, c, ndata);
//
// 在核函数执行结束后,通过cudaPeekAtLastError获取得到的代码,来知道是否出现错误
// cudaPeekAtLastError和cudaGetLastError都可以获取得到错误代码
// cudaGetLastError是获取错误代码并清除掉,也就是再一次执行cudaGetLastError获取的会是success
// 而cudaPeekAtLastError是获取当前错误,但是再一次执行cudaPeekAtLastError或者cudaGetLastErro拿到的还是那个错
cudaError_t code = cudaPeekAtLastError();
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("kernel error %s:%d test_print_kernel failed. \n code = %s, message = %s\n", __FILE__, __LINE__, err_name, err_message);
}
}
main.cpp
#include <cuda_runtime.h>
#include <stdio.h>
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
void vector_add(const float* a, const float* b, float* c, int ndata);
int main(){
const int size = 3;
float vector_a[size] = {2, 3, 2};
float vector_b[size] = {5, 3, 3};
float vector_c[size] = {0};
float* vector_a_device = nullptr;
float* vector_b_device = nullptr;
float* vector_c_device = nullptr;
checkRuntime(cudaMalloc(&vector_a_device, size * sizeof(float)));
checkRuntime(cudaMalloc(&vector_b_device, size * sizeof(float)));
checkRuntime(cudaMalloc(&vector_c_device, size * sizeof(float)));
checkRuntime(cudaMemcpy(vector_a_device, vector_a, size * sizeof(float), cudaMemcpyHostToDevice));
checkRuntime(cudaMemcpy(vector_b_device, vector_b, size * sizeof(float), cudaMemcpyHostToDevice));
vector_add(vector_a_device, vector_b_device, vector_c_device, size);
checkRuntime(cudaMemcpy(vector_c, vector_c_device, size * sizeof(float), cudaMemcpyDeviceToHost));
//
for(int i = 0; i < size; ++i){
printf("vector_c[%d] = %f\n", i, vector_c[i]);
}
checkRuntime(cudaFree(vector_a_device));
checkRuntime(cudaFree(vector_b_device));
checkRuntime(cudaFree(vector_c_device));
return 0;
}
1.7 shared memory 共享内存
核函数调用时,第三项指定了共享内存的大小,共享内存使得 block 内的threads可以相互通信。
-
sharedMemPerBlock 指示了block中最大可用的共享内存, 获取代码如下:
cudaDeviceProp prop; checkRuntime(cudaGetDeviceProperties(&prop, 0)); printf("prop.sharedMemPerBlock = %.2f KB\n", prop.sharedMemPerBlock / 1024.0f); -
共享内存是片上内存,更靠近计算单元,因此比global Memory速度更快,通常可以充当缓存使用
- 数据先读入到sharedMemory,做各类计算时,使用sharedMemory而非globalMemory
两个共享内存使用示例如下:

共享内存类别
共享内存,包括动态共享内存dynamic_shared_memory和核静态共享内存static_shared_memory。
- demo_kernel<<<1, 1, 12, nullptr>>>();其中第三个参数12,是指定动态共享内存dynamic_shared_memory的大小
- dynamic_shared_memory变量必须使用extern __shared__开头
- 并且定义为不确定大小的数组[]
- 12的单位是bytes,也就是可以安全存放3个float
- 变量放在函数外面和里面都一样
- 其指针由cuda调度器执行时赋值
- 动态共享变量,无论定义多少个,地址都一样
- static_shared_memory作为静态分配的共享内存
- 不加extern,以__shared__开头
- 定义时需要明确数组的大小
- 静态分配的地址比动态分配的地址低
- 静态共享变量,定义几个地址随之叠加
如果配置的各类共享内存总和大于sharedMemPerBlock,则核函数执行出错,Invalid argument
- 不同类型的静态共享变量定义,其内存划分并不一定是连续的
- 中间会有内存对齐策略,使得第一个和第二个变量之间可能存在空隙
- 因此你的变量之间如果存在空隙,可能小于全部大小的共享内存就会报错
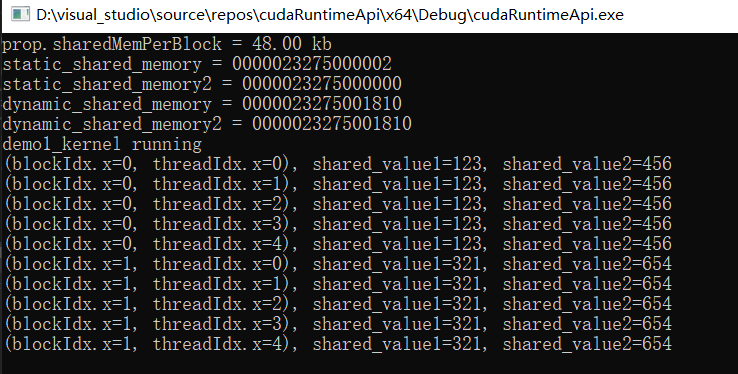
下面是一段使用共享内存的示例和其输出:
kernel.cu
#include <cuda_runtime.h>
#include <stdio.h>
//////////////////////demo1 //////////////////////////
/*
demo1 主要为了展示查看静态和动态共享变量的地址
*/
const size_t static_shared_memory_num_element = 6 * 1024; // 6KB
__shared__ char static_shared_memory[static_shared_memory_num_element];
__shared__ char static_shared_memory2[2];
__global__ void demo1_kernel(){
extern __shared__ char dynamic_shared_memory[]; // 静态共享变量和动态共享变量在kernel函数内/外定义都行,没有限制
extern __shared__ char dynamic_shared_memory2[];
printf("static_shared_memory = %p\n", static_shared_memory); // 静态共享变量,定义几个地址随之叠加
printf("static_shared_memory2 = %p\n", static_shared_memory2);
printf("dynamic_shared_memory = %p\n", dynamic_shared_memory); // 动态共享变量,无论定义多少个,地址都一样
printf("dynamic_shared_memory2 = %p\n", dynamic_shared_memory2);
if(blockIdx.x == 0 && threadIdx.x == 0) // 第一个thread
printf("Run kernel.\n");
}
/////////////////////demo2//////////////////////////////////
/*
demo2 主要是为了演示的是如何给 共享变量进行赋值
*/
// 定义共享变量,但是不能给初始值,必须由线程或者其他方式赋值
__shared__ int shared_value1;
__global__ void demo2_kernel(){
__shared__ int shared_value2;
if(threadIdx.x == 0){
// 在线程索引为0的时候,为shared value赋初始值
if(blockIdx.x == 0){
shared_value1 = 123;
shared_value2 = 55;
}else{
shared_value1 = 331;
shared_value2 = 8;
}
}
// 等待block内的所有线程执行到这一步
__syncthreads();
printf("%d.%d. shared_value1 = %d[%p], shared_value2 = %d[%p]\n",
blockIdx.x, threadIdx.x,
shared_value1, &shared_value1,
shared_value2, &shared_value2
);
}
void launch(){
demo1_kernel<<<1, 1, 12, nullptr>>>();
demo2_kernel<<<2, 5, 0, nullptr>>>();
}
main.cpp
#include <cuda_runtime.h>
#include <stdio.h>
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
void launch();
int main(){
cudaDeviceProp prop;
checkRuntime(cudaGetDeviceProperties(&prop, 0));
printf("prop.sharedMemPerBlock = %.2f KB\n", prop.sharedMemPerBlock / 1024.0f);
launch();
checkRuntime(cudaPeekAtLastError());
checkRuntime(cudaDeviceSynchronize());
printf("done\n");
return 0;
}
1.8 reduce-sum
-
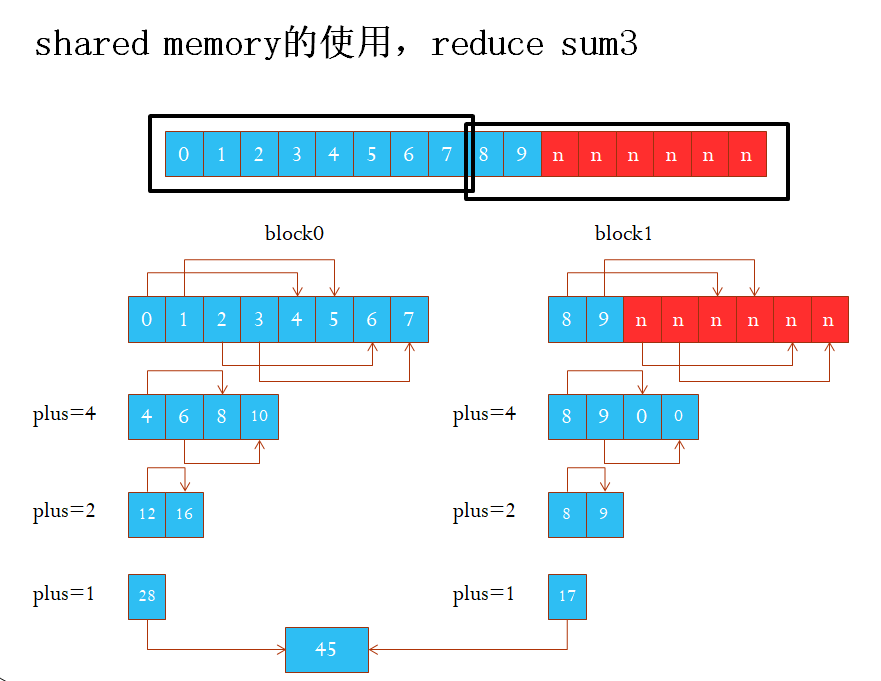
reduce思路,规约求和
- 将数组划分为n个块block。每个块大小为b,b设置为2的幂次方
- 分配b个大小的共享内存,记为float cache[b];
- 对每个块的数据进行规约求和:
- 定义plus = b / 2
- value = array[position], tx = threadIdx.x
- 将当前块内的每一个线程的value载入到cache中,即cache[tx] = value
- 对与tx < plus的线程,计算value += array[tx + plus]
- 定义plus = plus / 2,循环到3步骤
- 将每一个块的求和结果累加到output上(只需要考虑tx=0的线程就是总和的结果了)
编写reduce-sum核函数中用到下面两个函数:
-
__syncthreads(),同步所有block内的线程,即block内的所有线程都执行到这一行后再并行往下执行 -
int atomicAdd(int* address, int val),原子加法,返回的是旧值。 如下面代码执行后,x=11, y=10int *x = 10; y = atomicAdd(x, 1); # x=11, y=10
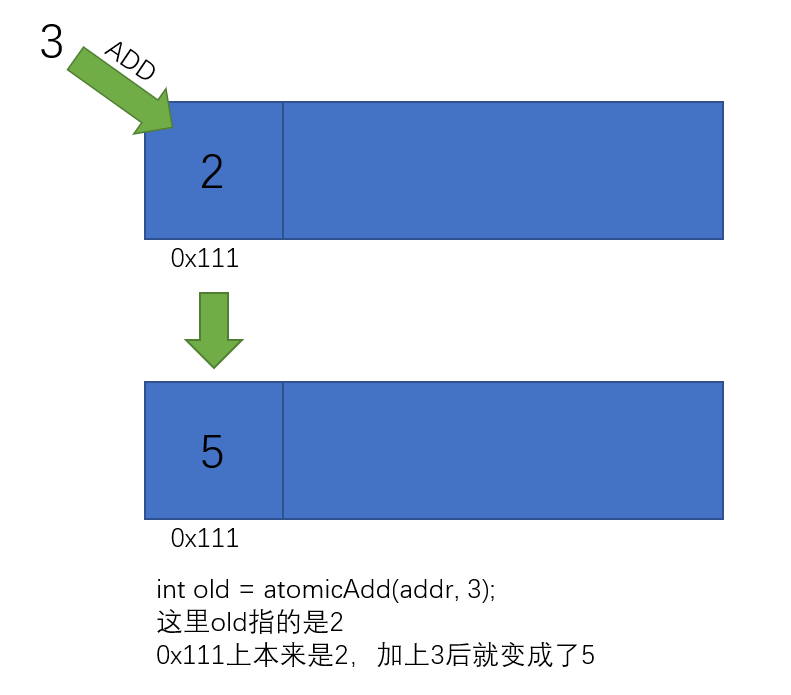
下面是reduce-sum核函数实现:
kernel.cu
#include <cuda_runtime.h>
#include <stdio.h>
#include <math.h>
__global__ void sum_kernel(float* array, int n, float* output){
int position = blockIdx.x * blockDim.x + threadIdx.x;
// 使用 extern声明外部的动态大小共享内存,由启动核函数的第三个参数指定
extern __shared__ float cache[]; // 这个cache 的大小为 block_size * sizeof(float)
int block_size = blockDim.x;
int lane = threadIdx.x;
float value = 0;
if(position < n)
value = array[position];
for(int i = block_size / 2; i > 0; i /= 2){ // 如何理解reduce sum 参考图片:figure/1.reduce_sum.jpg
cache[lane] = value;
__syncthreads(); // 等待block内的所有线程储存完毕
if(lane < i) value += cache[lane + i];
__syncthreads(); // 等待block内的所有线程读取完毕
}
if(lane == 0){
printf("block %d value = %f\n", blockIdx.x, value);
atomicAdd(output, value); // 由于可能动用了多个block,所以汇总结果的时候需要用atomicAdd。(注意这里的value仅仅是一个block的threads reduce sum 后的结果)
}
}
void launch_reduce_sum(float* array, int n, float* output){
const int nthreads = 512;
int block_size = n < nthreads ? n : nthreads;
int grid_size = (n + block_size - 1) / block_size;
// 这里要求block_size必须是2的幂次
float block_sqrt = log2(block_size);
printf("old block_size = %d, block_sqrt = %.2f\n", block_size, block_sqrt);
block_sqrt = ceil(block_sqrt);
block_size = pow(2, block_sqrt);
printf("block_size = %d, grid_size = %d\n", block_size, grid_size);
sum_kernel<<<grid_size, block_size, block_size * sizeof(float), nullptr>>>( // 这里
array, n, output
); // 这里要开辟 block_size * sizeof(float) 这么大的共享内存,
}
main.cpp
#include <cuda_runtime.h>
#include <stdio.h>
#include <math.h>
#define min(a, b) ((a) < (b) ? (a) : (b))
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
void launch_reduce_sum(float* input_array, int input_size, float* output);
int main(){
const int n = 101;
float* input_host = new float[n];
float* input_device = nullptr;
float ground_truth = 0;
for(int i = 0; i < n; ++i){
input_host[i] = i;
ground_truth += i;
}
checkRuntime(cudaMalloc(&input_device, n * sizeof(float)));
checkRuntime(cudaMemcpy(input_device, input_host, n * sizeof(float), cudaMemcpyHostToDevice));
float output_host = 0;
float* output_device = nullptr;
checkRuntime(cudaMalloc(&output_device, sizeof(float)));
checkRuntime(cudaMemset(output_device, 0, sizeof(float)));
launch_reduce_sum(input_device, n, output_device);
checkRuntime(cudaPeekAtLastError());
checkRuntime(cudaMemcpy(&output_host, output_device, sizeof(float), cudaMemcpyDeviceToHost));
checkRuntime(cudaDeviceSynchronize());
printf("output_host = %f, ground_truth = %f\n", output_host, ground_truth);
if(fabs(output_host - ground_truth) <= __FLT_EPSILON__){ // fabs 求绝对值
printf("结果正确.\n");
}else{
printf("结果错误.\n");
}
cudaFree(input_device);
cudaFree(output_device);
delete [] input_host;
printf("done\n");
return 0;
}
1.9 atomic
下面的核函数,实现从数组中找出小于一定阈值的数值及其索引,核函数的功能如下图:
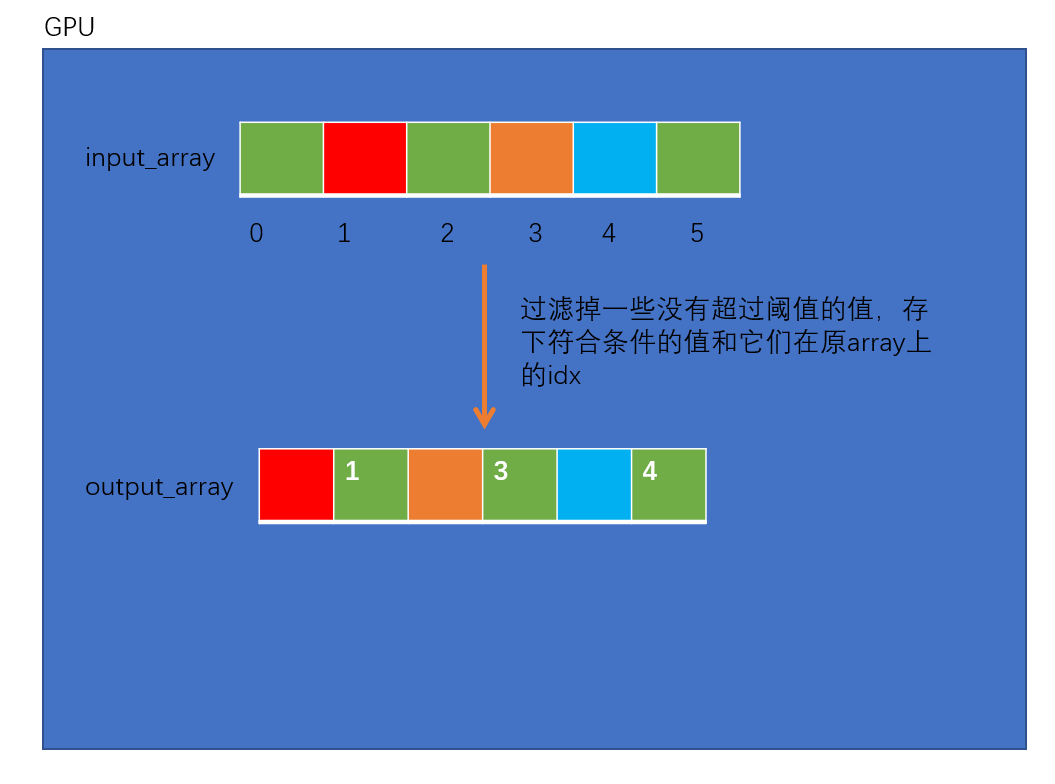
代码:
kernel.cu:
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void launch_keep_item_kernel(float* input_array, int input_size, float threshold, float* output_array, int output_capacity){
/*
该函数做的事情如图:
figure/2.launch_keep_item_kernel.png
*/
int input_index = blockIdx.x * blockDim.x + threadIdx.x;
if(input_array[input_index] < threshold)
return;
int output_index = atomicAdd(output_array, 1); // figure/atomicAdd.png 图解
if(output_index >= output_capacity) // 如果计的数 超出 容量
return;
float* output_item = output_array + 1 + output_index * 2;
output_item[0] = input_array[input_index];
output_item[1] = input_index;
}
void launch_keep_item(float* input_array, int input_size, float threshold, float* output_array, int output_capacity){
const int nthreads = 512;
int block_size = input_size < nthreads ? input_size : nthreads;
int grid_size = (input_size + block_size - 1) / block_size;
launch_keep_item_kernel<<<grid_size, block_size, block_size * sizeof(float), nullptr>>>(input_array, input_size, threshold, output_array, output_capacity);
}
main.cpp
#include <cuda_runtime.h>
#include <stdio.h>
#define min(a, b) ((a) < (b) ? (a) : (b))
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
// 保留元素中,大于特定值的元素,储存其值和索引
// input_array表示为需要判断的数组
// input_size为pdata长度
// threshold为过滤掉阈值,当input_array中的元素大于threshold时会被保留
// output_array为储存的结果数组,格式是:size, [value, index], [value, index]
// output_capacity为output_array中最多可以储存的元素数量
void launch_keep_item(float* input_array, int input_size, float threshold, float* output_array, int output_capacity);
int main(){
const int n = 100000;
float* input_host = new float[n];
float* input_device = nullptr;
for(int i = 0; i < n; ++i){
input_host[i] = i % 100; // input_host对应地址上放的数据为 0 1 2 3 ... 99
}
checkRuntime(cudaMalloc(&input_device, n * sizeof(float)));
checkRuntime(cudaMemcpy(input_device, input_host, n * sizeof(float), cudaMemcpyHostToDevice));
int output_capacity = 20;
float* output_host = new float[1 + output_capacity * 2]; // 1 + output_capacity * 2 = 41
float* output_device = nullptr;
checkRuntime(cudaMalloc(&output_device, (1 + output_capacity * 2) * sizeof(float)));
checkRuntime(cudaMemset(output_device, 0, sizeof(float)));
float threshold = 99;
launch_keep_item(input_device, n, threshold, output_device, output_capacity);
checkRuntime(cudaPeekAtLastError());
checkRuntime(cudaMemcpy(output_host, output_device, (1 + output_capacity * 2) * sizeof(float), cudaMemcpyDeviceToHost));
checkRuntime(cudaDeviceSynchronize());
printf("output_size = %f\n", output_host[0]);
int output_size = min(output_host[0], output_capacity);
for(int i = 0; i < output_size; ++i){
float* output_item = output_host + 1 + i * 2;
float value = output_item[0];
int index = output_item[1];
printf("output_host[%d] = %f, %d\n", i, value, index);
}
cudaFree(input_device);
cudaFree(output_device);
delete [] input_host;
delete [] output_host;
printf("done\n");
return 0;
}
代码中相关知识点:
- atomicAdd是原子加法,同类型原子操作有很多,比如减法等等
- 输出的数组需要预先分配空间,例如这里的:output_capacity
- 最后统计结果的时候记得取min,int output_size = min(output_host[0], output_capacity);
- 因为核函数中,add的次数可能会超过capacity大小,导致后续访问越界的发生
- 输出的数组可能会乱序,即不同执行时刻结果不同。这是因为cuda是并行的,调度器的调度顺序不确定
- 因此capacity一定要比预期的最大值大一些,才可能保证结果不会丢失
- 可以通过储存index,然后在cpu上执行一次排序,实现最后是输出是有序的
- 这种类型的代码实现,是模型后处理的关键,处理动态数组的关键
1.10 warpaffine
1.10.1 基本原理
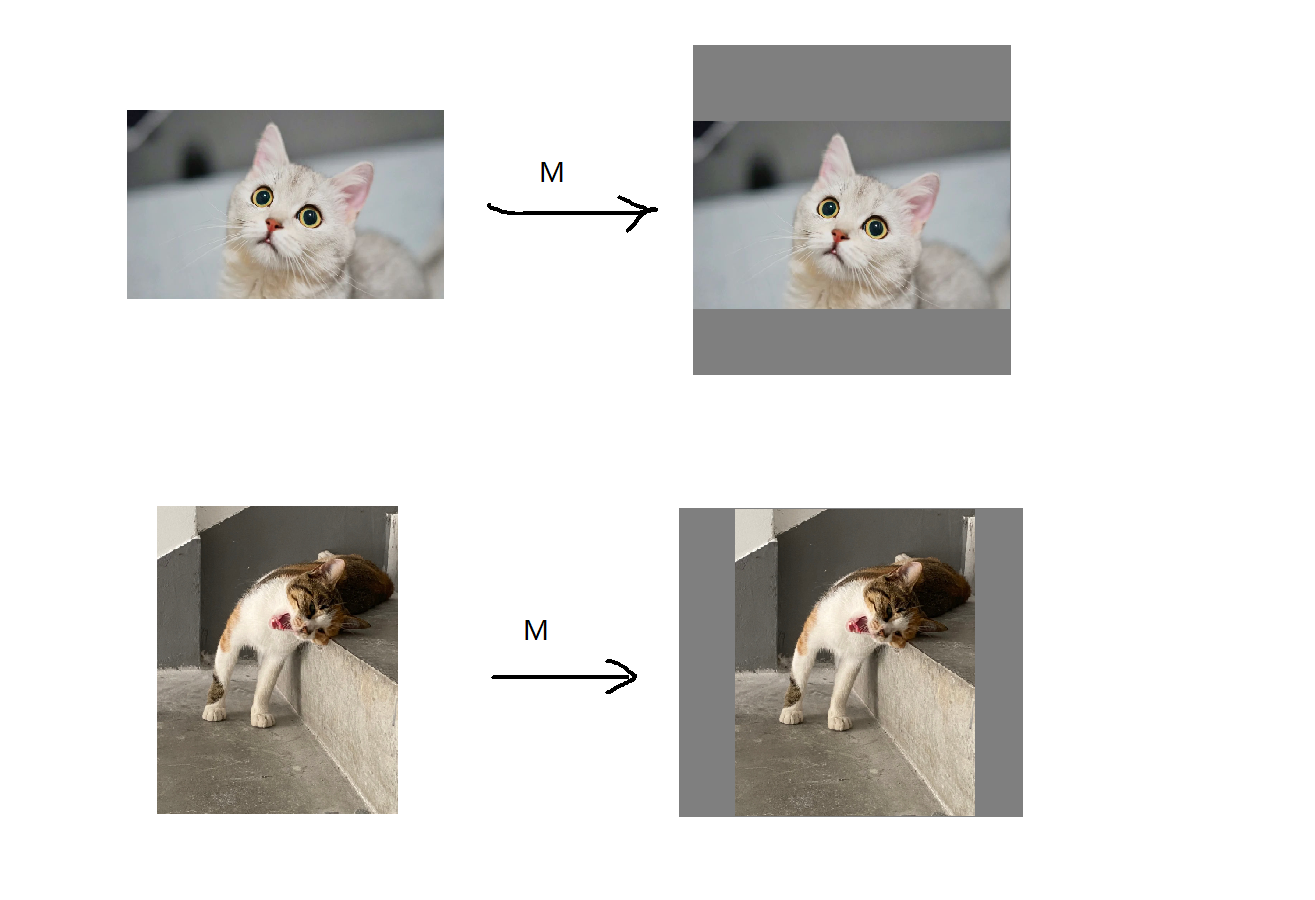
图像输入网络前,我们通常会进行一些预处理,主要是resize,padding,normalization,bgr2rgb等操作。其中resize最常见做法就是: 保持图像宽高比不变,将图像长边缩放到指定维度,然后短边进行padding补齐。如下图所示:
下面一段代码用opencv实现上述功能:
h, w = img.shape[:2]
input_width, input_height = 1280, 720
scale = min(input_height / h, input_width / w)
image = cv2.resize(image, None, fx=scale, fy=scale)
nh, nw = image.shape[:2]
if nh < input_height:
pad_h = input_height - nh
image = cv2.copyMakeBorder(image, 0, pad_h, 0, 0, borderType=cv2.BORDER_CONSTANT,
value=0)
elif nw < input_width:
pad_w = input_width - nw
image = cv2.copyMakeBorder(image, 0, 0, 0, pad_w, borderType=cv2.BORDER_CONSTANT,
value=0)
resize+padding实际上就是先缩放,再平移,可以通过仿射变换warpaffine实现,用一个矩阵可以描述这个过程, 如下图:

代码表示如下:
image = cv2.imread("cat1.png")
oh, ow = image.shape[:2]
dh, dw = 640, 640
scale = min(dw/ow, dh/oh)
M = np.array([
[scale, 0, -scale * ow * 0.5 + dw * 0.5],
[0, scale, -scale * oh * 0.5 + dh * 0.5]
])
dst_image = cv2.warpAffine(image, M, dst_size)
cv2.warpAffine函数实际上通过这个矩阵建立变换前后像素点的映射关系,然后采用双线性插值等方式得到变换后像素值。在c++部署时,可以通过核函数实现上述过程(变换矩阵+双线性插值),从而加速前处理。
1.10.2 双线性插值
在自己实现双线性插值的核函数时,需要理解和注意下双线性插值的问题。
双线性插值法是利用待求像素四个相邻像素的灰度在两个方向上做线性插值,也就是做两次线性变换。
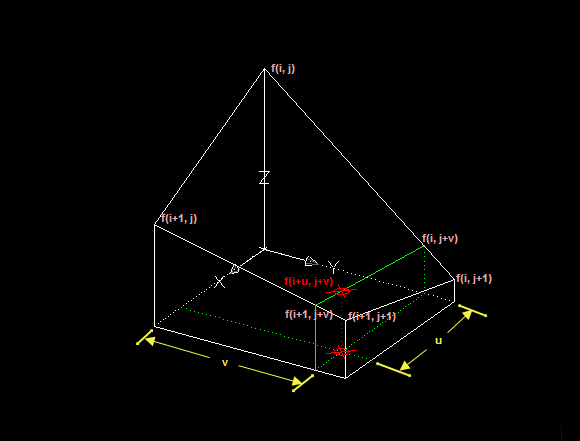
如上图所示,我们使用 表示在坐标 的像素值大小,现在要插值求坐标为 的像素值,其中 的定义与上面相同。
我们需要先求 ,因为 到 的灰度变化我们假设为线性关系,则:
同理:
上面我们已经求得了在 j 方向上的插值结果,接着在上面的基础上再计算 i 方向的插值结果即可:
可见这个方法比最近邻方法复杂,计算量更大,但没有灰度不连续的缺点,结果基本令人满意,只是图像轮廓可能会有一点模糊。
双线性插值的坐标系选择问题
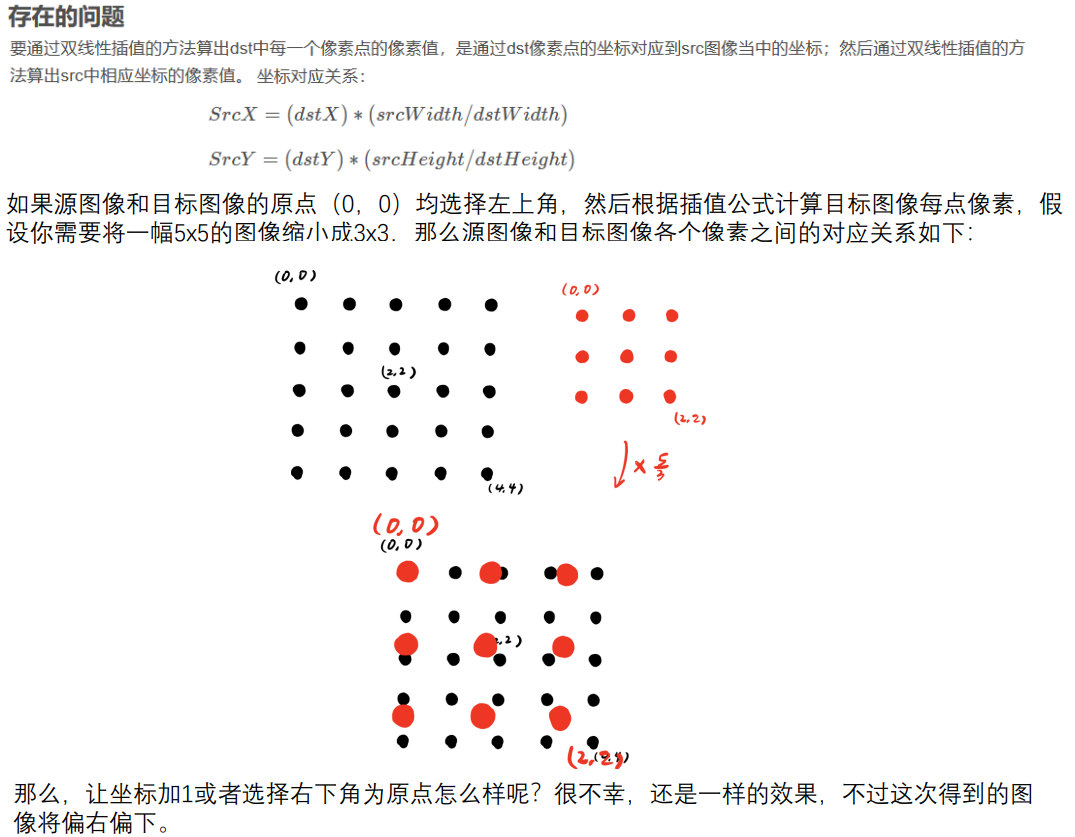
可以发现,图像上采样后像素点会存在偏上和偏下的问题,解决方法如下:
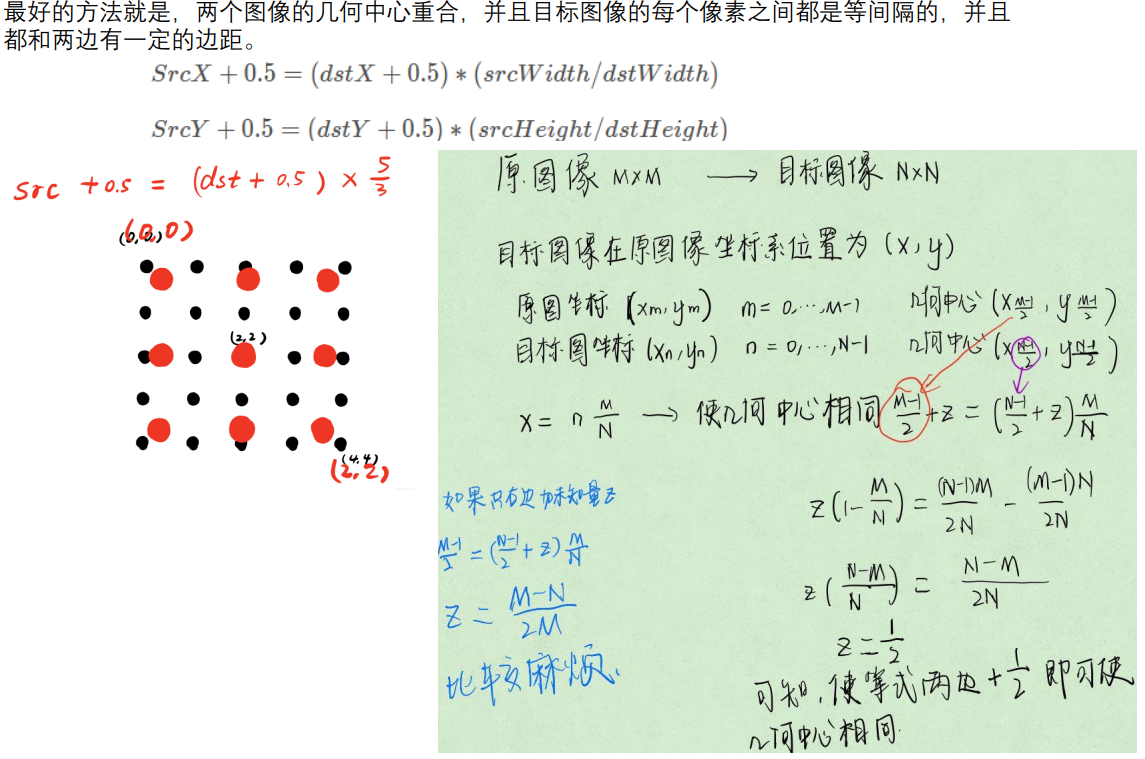
总结下,就是原始像素点和新像素点都加0.5,如果都用矩阵来表示,实际上就是缩放矩阵的差别, 如下:
# 原始缩放矩阵对应关系:dst_x = scale*src_x
scale_matrix=[
[scale, 0, 0],
[0, scale, 0,]
[0, 0, 1]
]
# 新缩放矩阵对应关系:dst_x = scale*(src_x+0.5)-0.5
new_scale_matrix=[
[scale, 0, scale*0.5-0.5],
[0, scale, scale*0.5-0.5,]
[0, 0, 1]
]
因为双线性插值坐标系选择问题,我们的变换矩阵(缩放矩阵的变动),需要进行小变动:
(https://blog.csdn.net/weixin_34273481/article/details/93593956)
# 原始矩阵
M = np.array([
[scale, 0, -scale*ow*0.5 + dw * 0.5],
[0, scale, -scale*oh*0.5 + dh * 0.5]
])
# 变动后矩阵
M = np.array([
[scale, 0, -scale*ow*0.5 + dw * 0.5 + scale * 0.5 -0.5],
[0, scale, -scale*oh*0.5 + dh * 0.5 + scale * 0.5 -0.5]
])
1.10.3 核函数实现
理解了上述过程,实现起来就很简单了,代码如下:
kernel.cu
#include <cuda_runtime.h>
#include <math.h>
#define min(a, b) ((a) < (b) ? (a) : (b))
#define num_threads 512
typedef unsigned char uint8_t;
struct Size{
int width = 0, height = 0;
Size() = default;
Size(int w, int h)
:width(w), height(h){}
};
// 计算仿射变换矩阵
// 计算的矩阵是居中缩放
struct AffineMatrix{
float i2d[6]; // image to dst(network), 2x3 matrix
float d2i[6]; // dst to image, 2x3 matrix
// 这里其实是求解imat的逆矩阵,由于这个3x3矩阵的第三行是确定的0, 0, 1,因此可以简写如下
void invertAffineTransform(float imat[6], float omat[6]){
float i00 = imat[0]; float i01 = imat[1]; float i02 = imat[2];
float i10 = imat[3]; float i11 = imat[4]; float i12 = imat[5];
// 计算行列式
float D = i00 * i11 - i01 * i10;
D = D != 0 ? 1.0 / D : 0;
// 计算剩余的伴随矩阵除以行列式
float A11 = i11 * D;
float A22 = i00 * D;
float A12 = -i01 * D;
float A21 = -i10 * D;
float b1 = -A11 * i02 - A12 * i12;
float b2 = -A21 * i02 - A22 * i12;
omat[0] = A11; omat[1] = A12; omat[2] = b1;
omat[3] = A21; omat[4] = A22; omat[5] = b2;
}
void compute(const Size& from, const Size& to){
float scale_x = to.width / (float)from.width;
float scale_y = to.height / (float)from.height;
// 这里取min的理由是
// 1. M矩阵是 from * M = to的方式进行映射,因此scale的分母一定是from
// 2. 取最小,即根据宽高比,算出最小的比例,如果取最大,则势必有一部分超出图像范围而被裁剪掉,这不是我们要的
// **
float scale = min(scale_x, scale_y);
/**
这里的仿射变换矩阵实质上是2x3的矩阵,具体实现是
scale, 0, -scale * from.width * 0.5 + to.width * 0.5
0, scale, -scale * from.height * 0.5 + to.height * 0.5
这里可以想象成,是经历过缩放、平移、平移三次变换后的组合,M = TPS
例如第一个S矩阵,定义为把输入的from图像,等比缩放scale倍,到to尺度下
S = [
scale, 0, 0
0, scale, 0
0, 0, 1
]
P矩阵定义为第一次平移变换矩阵,将图像的原点,从左上角,移动到缩放(scale)后图像的中心上
P = [
1, 0, -scale * from.width * 0.5
0, 1, -scale * from.height * 0.5
0, 0, 1
]
T矩阵定义为第二次平移变换矩阵,将图像从原点移动到目标(to)图的中心上
T = [
1, 0, to.width * 0.5,
0, 1, to.height * 0.5,
0, 0, 1
]
通过将3个矩阵顺序乘起来,即可得到下面的表达式:
M = [
scale, 0, -scale * from.width * 0.5 + to.width * 0.5
0, scale, -scale * from.height * 0.5 + to.height * 0.5
0, 0, 1
]
去掉第三行就得到opencv需要的输入2x3矩阵
**/
/*
+ scale * 0.5 - 0.5 的主要原因是使得中心更加对齐,下采样不明显,但是上采样时就比较明显
参考:https://www.iteye.com/blog/handspeaker-1545126
*/
i2d[0] = scale; i2d[1] = 0; i2d[2] =
-scale * from.width * 0.5 + to.width * 0.5 + scale * 0.5 - 0.5;
i2d[3] = 0; i2d[4] = scale; i2d[5] =
-scale * from.height * 0.5 + to.height * 0.5 + scale * 0.5 - 0.5;
invertAffineTransform(i2d, d2i);
}
};
__device__ void affine_project(float* matrix, int x, int y, float* proj_x, float* proj_y){
// matrix
// m0, m1, m2
// m3, m4, m5
*proj_x = matrix[0] * x + matrix[1] * y + matrix[2];
*proj_y = matrix[3] * x + matrix[4] * y + matrix[5];
}
__global__ void warp_affine_bilinear_kernel(
uint8_t* src, int src_line_size, int src_width, int src_height,
uint8_t* dst, int dst_line_size, int dst_width, int dst_height,
uint8_t fill_value, AffineMatrix matrix
){
int dx = blockDim.x * blockIdx.x + threadIdx.x;
int dy = blockDim.y * blockIdx.y + threadIdx.y;
if (dx >= dst_width || dy >= dst_height) return;
float c0 = fill_value, c1 = fill_value, c2 = fill_value;
float src_x = 0; float src_y = 0;
affine_project(matrix.d2i, dx, dy, &src_x, &src_y); // 变换后图像位置(x, y), 对应变换前图像像素位置(src_x, src_y)
if(src_x < -1 || src_x >= src_width || src_y < -1 || src_y >= src_height){
// out of range
// src_x < -1时,其高位high_x < 0,超出范围
// src_x >= -1时,其高位high_x >= 0,存在取值
}else{
int y_low = floorf(src_y);
int x_low = floorf(src_x);
int y_high = y_low + 1;
int x_high = x_low + 1;
uint8_t const_values[] = {fill_value, fill_value, fill_value};
float ly = src_y - y_low;
float lx = src_x - x_low;
float hy = 1 - ly;
float hx = 1 - lx;
float w1 = hy * hx, w2 = hy * lx, w3 = ly * hx, w4 = ly * lx;
uint8_t* v1 = const_values;
uint8_t* v2 = const_values;
uint8_t* v3 = const_values;
uint8_t* v4 = const_values;
if(y_low >= 0){
if (x_low >= 0)
v1 = src + y_low * src_line_size + x_low * 3;
if (x_high < src_width)
v2 = src + y_low * src_line_size + x_high * 3;
}
if(y_high < src_height){
if (x_low >= 0)
v3 = src + y_high * src_line_size + x_low * 3;
if (x_high < src_width)
v4 = src + y_high * src_line_size + x_high * 3;
}
c0 = floorf(w1 * v1[0] + w2 * v2[0] + w3 * v3[0] + w4 * v4[0] + 0.5f);
c1 = floorf(w1 * v1[1] + w2 * v2[1] + w3 * v3[1] + w4 * v4[1] + 0.5f);
c2 = floorf(w1 * v1[2] + w2 * v2[2] + w3 * v3[2] + w4 * v4[2] + 0.5f);
}
// 此处可以进行bgr2rgb的操作
// if(norm.channel_type == ChannelType::Invert){
// float t = c2;
// c2 = c0; c0 = t;
// }
//此处可以进行normalize
// if(norm.type == NormType::MeanStd){
// c0 = (c0 * norm.alpha - norm.mean[0]) / norm.std[0];
// c1 = (c1 * norm.alpha - norm.mean[1]) / norm.std[1];
// c2 = (c2 * norm.alpha - norm.mean[2]) / norm.std[2];
// }else if(norm.type == NormType::AlphaBeta){
// c0 = c0 * norm.alpha + norm.beta;
// c1 = c1 * norm.alpha + norm.beta;
// c2 = c2 * norm.alpha + norm.beta;
// }
uint8_t* pdst = dst + dy * dst_line_size + dx * 3;
pdst[0] = c0; pdst[1] = c1; pdst[2] = c2;
}
void warp_affine_bilinear(
uint8_t* src, int src_line_size, int src_width, int src_height,
uint8_t* dst, int dst_line_size, int dst_width, int dst_height,
uint8_t fill_value
){
dim3 block_size(32, 32); // blocksize最大就是1024,这里用2d来看更好理解
dim3 grid_size((dst_width + 31) / 32, (dst_height + 31) / 32);
AffineMatrix affine;
affine.compute(Size(src_width, src_height), Size(dst_width, dst_height));
warp_affine_bilinear_kernel<<<grid_size, block_size, 0, nullptr>>>(
src, src_line_size, src_width, src_height,
dst, dst_line_size, dst_width, dst_height,
fill_value, affine
);
}
main.cpp
#include <cuda_runtime.h>
#include <opencv2/opencv.hpp>
#include <stdio.h>
using namespace cv;
#define min(a, b) ((a) < (b) ? (a) : (b))
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
void warp_affine_bilinear( // 声明
uint8_t* src, int src_line_size, int src_width, int src_height,
uint8_t* dst, int dst_line_size, int dst_width, int dst_height,
uint8_t fill_value
);
Mat warpaffine_to_center_align(const Mat& image, const Size& size){
Mat output(size, CV_8UC3);
uint8_t* psrc_device = nullptr;
uint8_t* pdst_device = nullptr;
size_t src_size = image.cols * image.rows * 3;
size_t dst_size = size.width * size.height * 3;
checkRuntime(cudaMalloc(&psrc_device, src_size)); // 在GPU上开辟两块空间
checkRuntime(cudaMalloc(&pdst_device, dst_size));
checkRuntime(cudaMemcpy(psrc_device, image.data, src_size, cudaMemcpyHostToDevice)); // 搬运数据到GPU上
warp_affine_bilinear(
psrc_device, image.cols * 3, image.cols, image.rows,
pdst_device, size.width * 3, size.width, size.height,
114
);
// 检查核函数执行是否存在错误
checkRuntime(cudaPeekAtLastError());
checkRuntime(cudaMemcpy(output.data, pdst_device, dst_size, cudaMemcpyDeviceToHost)); // 将预处理完的数据搬运回来
checkRuntime(cudaFree(psrc_device));
checkRuntime(cudaFree(pdst_device));
return output;
}
int main(){
// int device_count = 1;
// checkRuntime(cudaGetDeviceCount(&device_count));
const char* img_path = "./cat1.png";
Mat image = imread(img_path);
printf("image width=%d, height=%d\n", img.cols, img.rows);
Mat output = warpaffine_to_center_align(image, Size(640, 640));
cv::imshow("img", img);
cv::imshow("warp_img", output);
cv::waitKey(0);
cv::destroyAllWindows();
const char* dst_path = "./warp_cat1.png";
imwrite(dst_path, output);
printf("Done. save to output.jpg\n");
return 0;
}
上述代码知识点:
- 该代码仿射变换对象是CV8UC3的图像,经过简单修改后,可以做到端到端,把结果输入到tensorRT中
- 可以直接实现WarpAffine + Normalize + SwapRB
- 在仿射核函数里面,我们循环的次数,是dst.width * dst.height,以dst为参照集
- 也因此,无论src多大,dst固定的话,计算量也是固定的
- 另外,核函数里面得到的是dst.x、dst.y,我们需要获取对应在src上的坐标
- 所以需要src.x, src.y = project(matrix, dst.x, dst.y)
- 因此这里的project是dst -> src的变换
- AffineMatrix的compute函数计算的是src -> dst的变换矩阵i2d
- 所以才需要invertAffineTransform得到逆矩阵,即dst -> src,d2i
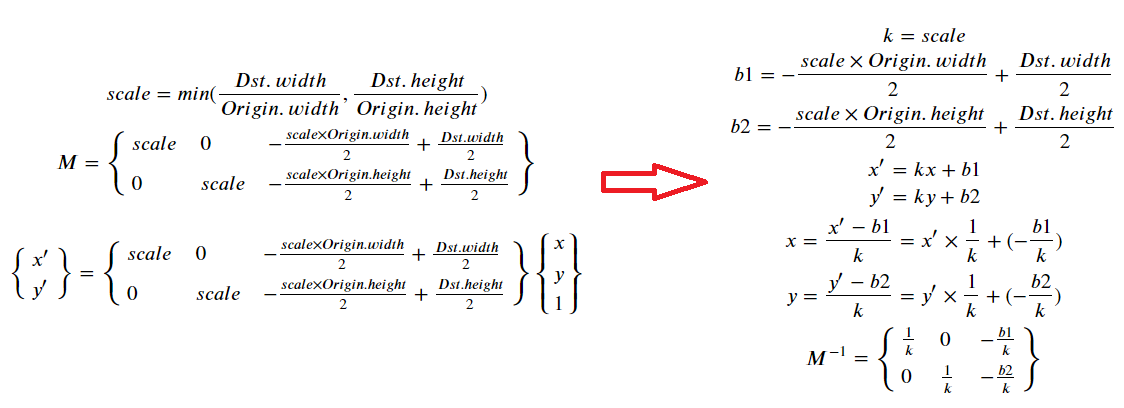
矩阵求逆
上述代码中求逆矩阵的步骤,这里稍微解释下。首先原始矩阵如下, 是一个上三角矩阵,根据上三角矩阵性值,可以分块求逆,如下:
# 原始矩阵
matrix = [
[s, 0, dx],
[0, s, dy],
[0, 0, 1]
]

若写成上图分块矩阵,A1,A2,A3对应如下
A1=[
[s, 0],
[0, s]]
A3 = [
[dx],
[dy]]
A2 = [1]
因此原始代码中可以如下理解,
-
第一步:利用伴随矩阵求解分块矩阵A1的逆矩阵, 对应的代码部分为:
// 计算上面矩阵左上角四个元素的行列式 float D = i00 * i11 - i01 * i10; D = D != 0 ? 1.0 / D : 0; // 计算剩余的伴随矩阵除以行列式 float A11 = i11 * D; float A22 = i00 * D; float A12 = -i01 * D; float A21 = -i10 * D; -
第二部:根据A1,A2的逆矩阵计算A3的逆矩阵,对应的代码部分为:
float b1 = -A11 * i02 - A12 * i12; float b2 = -A21 * i02 - A22 * i12;
另外,矩阵比较简单时,也可以通过解方程来求解逆矩阵,如下:
1.11 cublas-gemm
1.11.1 cuBLAS
https://zhuanlan.zhihu.com/p/438551588
官网:https://docs.nvidia.com/cuda/cublas/index.html
cuBLAS简介:CUDA基本线性代数子程序库(CUDA Basic Linear Algebra Subroutine library)。
cuBLAS库用于进行矩阵运算,它包含两套API,一个是常用到的cuBLAS API,需要用户自己分配GPU内存空间,按照规定格式填入数据,;还有一套CUBLASXT API,可以分配数据在CPU端,然后调用函数,它会自动管理内存、执行计算。既然都用cuda了,其实还是用第一套API多一点。
最初,为了尽可能地兼容Fortran语言环境,cuBLAS库被设计成列优先存储的数据格式,不过C/C++是行优先的,我们比较好理解的也是行优先的格式,所以需要费点心思在数据格式上。
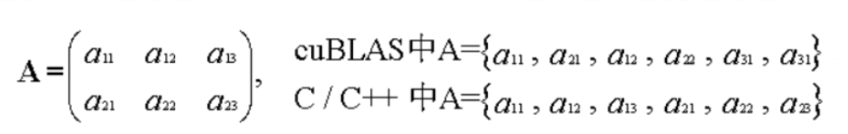
cuBLAS知识点 :
-
装好cuda会自带cuBLAS库的,只要include 头文件“cublas_v2.h”就可以调用它了
-
使用cuBLAS库函数,必须初始化一个句柄来管理cuBLAS上下文
// 创建 cublasHandle_t cublas_h = nullptr; cublasCreate(&cublas_h); //销毁 cublasDestroy(&cublas_h); -
cuBLAS运算函数:官方分为了3个等级,Level-1、Level-2、Level-3处理的情境逐渐变得复杂,功能变得强大。Level-1里求最大最小值,求和,旋转等等。Level-3就全是矩阵与矩阵间运算的函数了,矩阵相乘就在这里面。
cublasSgemm(): 处理float数据类型的矩阵相乘cublasDgemm(): 处理double数据类型的矩阵相乘
// 注意这里的内存序列是列主序列的 // 矩阵A -> m x n // 矩阵B -> n x k // 矩阵C -> m x k int lda = n; int ldb = k; int ldc = m; // cublasSgemm函数运算:C = A * B * alpha + beta cublasSgemm(cublas_h, cublasOperation_t::CUBLAS_OP_T, // 提供的数据是行排列,因此需要转置 cublasOperation_t::CUBLAS_OP_T, // 提供的数据是行排列,因此需要转置 m, // 矩阵A的行数 k, // 矩阵B的列数 n, // 矩阵A的列数 &alpha, // 乘数 dA, // A的地址 lda, // 矩阵A的列数 dB, // B的地址 ldb, // 矩阵B的列数 &beta, // 加数 dC, // C的地址 ldc // C的行数(C=A*B,结果C是列排列,所以C的结果是k x m的,需要转置到m x k) );
1.11.2 Cuda Events
https://zhuanlan.zhihu.com/p/369367933
Event是stream相关的一个重要概念,其用来标记strean执行过程的某个特定的点。其主要用途是:
- 同步stream执行: 在stream流中插入event, 查询该event是否完成 。 只有当该event标记的stream位置的所有操作都被执行完毕,该event才算完成。
官网api:https://docs.nvidia.com/cuda/archive/8.0/cuda-runtime-api/group__CUDART__EVENT.html
// 声明
cudaEvent_t event;
// 创建
cudaError_t cudaEventCreate(cudaEvent_t* event);
// 销毁
cudaError_t cudaEventDestroy(cudaEvent_t event);
//将event关联到指定stream
cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream = 0);
//类似于cudaStreamSynchronize,只不过是等待一个event而不是整个stream执行完毕(会阻塞host)
cudaError_t cudaEventSynchronize(cudaEvent_t event);
//测试event是否完成,该函数不会阻塞host
cudaError_t cudaEventQuery(cudaEvent_t event);
//度量两个event之间的时间间隔:
cudaError_t cudaEventElapsedTime(float* ms, cudaEvent_t start, cudaEvent_t stop);
1.11.3 矩阵分块相乘
参考:https://zhuanlan.zhihu.com/p/133330692
矩阵分块相乘定义

矩阵分块相乘作用
对于特别大的矩阵相乘时,如果内存或者显存不够时,可以将其拆分为多个小矩阵相乘。另外使用cuda核函数实现矩阵乘法时,拆分成小矩阵乘法,可以利用共享内存的特性,加速计算。
1.11.4 显存中共享内存
https://www.cnblogs.com/weijiakai/p/15495608.html
共享内存:线程块(block)中的所有线程所共享,即每个block中的所有线程都可以访问和修改
- 共享内存是片上内存,更靠近计算单元,因此比global Memory速度更快,通常可以充当缓存使用
下面代码,比较了cpu,两种cuda核函数,cublas库实现的矩阵乘法运算速度:
main.cpp
#include <cuda_runtime.h>
#include <cublas_v2.h>
#include <opencv2/opencv.hpp>
#include <stdio.h>
#include <chrono>
using namespace std;
using namespace cv;
#define min(a, b) ((a) < (b) ? (a) : (b))
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
void gemm_0(const float* A, const float* B, float* C, int m, int n, int k, cudaStream_t stream);
void gemm_1(const float* A, const float* B, float* C, int m, int n, int k, cudaStream_t stream);
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
void verify(const cv::Mat& a, const cv::Mat& b, float eps = 1e-5){
auto diff = cv::Mat(a - b);
float* p = diff.ptr<float>(0);
int error_count = 0;
float max_diff = *p;
float min_diff = *p;
for(int i = 0; i < diff.rows*diff.cols; ++i, ++p){
if(fabs(*p) >= eps){
if(error_count < 10)
printf("Error value: %f, %d\n", *p, i);
error_count += 1;
}
max_diff = max(max_diff, *p);
min_diff = min(min_diff, *p);
}
if(error_count > 0){
printf("... error count = %d. max = %f, min = %f\n", error_count, max_diff, min_diff);
}else{
printf("Done no error. max = %f, min = %f\n", max_diff, min_diff);
}
}
int main(){
cv::Mat A, B, C;
int m = 2000, n = 3000, k = 5000;
A.create(m, n, CV_32F);
B.create(n, k, CV_32F);
C.create(m, k, CV_32F);
cv::randn(A, 0, 1);
cv::randn(B, 0, 1);
cudaEvent_t tc0, tc1, tc2, tc3;
cudaStream_t stream = nullptr;
cublasHandle_t cublas_h = nullptr;
cudaStreamCreate(&stream);
cublasCreate(&cublas_h);
cublasSetStream(cublas_h, stream);
cudaEventCreate(&tc0);
cudaEventCreate(&tc1);
cudaEventCreate(&tc2);
cudaEventCreate(&tc3);
int Abytes = m * n * sizeof(float);
int Bbytes = n * k * sizeof(float);
int Cbytes = m * k * sizeof(float);
cudaHostRegister(A.data, Abytes, cudaHostRegisterDefault); // 转换成锁页内存 page-locked memory
cudaHostRegister(B.data, Bbytes, cudaHostRegisterDefault);
cudaHostRegister(C.data, Cbytes, cudaHostRegisterDefault);
float *dA, *dB, *dC;
cudaMalloc(&dA, Abytes);
cudaMalloc(&dB, Bbytes);
cudaMalloc(&dC, Cbytes);
cudaMemcpyAsync(dA, A.data, Abytes, cudaMemcpyHostToDevice, stream);
cudaMemcpyAsync(dB, B.data, Bbytes, cudaMemcpyHostToDevice, stream);
// warm up
for(int i = 0; i < 10; ++i)
gemm_0(dA, dB, dC, m, n, k, stream);
cudaEventRecord(tc0, stream); // 将Event关联到stream
gemm_0(dA, dB, dC, m, n, k, stream);
cudaEventRecord(tc1, stream);
gemm_1(dA, dB, dC, m, n, k, stream);
cudaEventRecord(tc2, stream);
float alpha = 1.0f;
float beta = 0.0f;
int lda = n;
int ldb = k;
int ldc = m;
// 注意他的结果是列优先的,需要转置才能做对比
// cv::Mat tmp(C.cols, C.rows, CV_32F, C.data);
// verify(tmp.t(), tC, 1e-4);
// C = OP(A) * OP(B) * alpha + beta
// 注意这里的内存序列是列主序列的
// A -> m x n
// B -> n x k
// C -> m x k
cublasSgemm(cublas_h,
cublasOperation_t::CUBLAS_OP_T, // 提供的数据是行排列,因此需要转置 (将矩阵A转置, m*n-->n*m)
cublasOperation_t::CUBLAS_OP_T, // 提供的数据是行排列,因此需要转置 (将矩阵B转置, n*k-->k*n)
m, // op(A)的行数
k, // op(B)的列数
n, // op(A)的列数
&alpha, // 乘数
dA, // A的地址
lda, // op(A)的列数
dB, // B的地址
ldb, // op(B)的列数
&beta, // 加数
dC, // C的地址
ldc // C的行数 (C = op(A) * op(B),因为结果C是列排列的,所以C的结果是k x m的,需要转置到m x k)
);
cudaEventRecord(tc3, stream);
cudaMemcpyAsync(C.data, dC, Cbytes, cudaMemcpyDeviceToHost, stream);
cudaStreamSynchronize(stream);
float time_kernel_0 = 0;
float time_kernel_1 = 0;
float time_kernel_cublas = 0;
cudaEventElapsedTime(&time_kernel_0, tc0, tc1);
cudaEventElapsedTime(&time_kernel_1, tc1, tc2);
cudaEventElapsedTime(&time_kernel_cublas, tc2, tc3);
printf(
"kernel_0 = %.5f ms, kernel_1 = %.5f ms, kernel_cublas = %.5f ms\n",
time_kernel_0, time_kernel_1, time_kernel_cublas
);
auto t0 = chrono::duration_cast<chrono::microseconds>(chrono::system_clock::now().time_since_epoch()).count() / 1000.0;
auto tC = cv::Mat(A * B);
auto t1 = chrono::duration_cast<chrono::microseconds>(chrono::system_clock::now().time_since_epoch()).count() / 1000.0;
printf("CPU times: %.5f ms\n", t1 - t0);
// 这个转换只应用于cublas,因为cublas输出结果是列优先的
bool cublas_result = true;
if(cublas_result){
cv::Mat tmp(C.cols, C.rows, CV_32F, C.data); // tmp: (2000, 5000)
tmp = tmp.t(); // tmp: (5000, 2000)
verify(tmp, tC, 1e-3);
}else{
verify(C, tC, 1e-3);
}
return 0;
checkRuntime(cudaFree(dA));
checkRuntime(cudaFree(dB));
checkRuntime(cudaFree(dC));
}
kernel.cu
#include <cuda_runtime.h>
__global__ void gemm_kernel_0(const float* A, const float* B, float* C, int m, int n, int k)
{
// A -> m x n
// B -> n x k
// C -> m x k
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if(row >= m || col >= k)
return;
float csum = 0;
for (int i = 0; i < n; ++i){
csum += A[row * n + i] * B[i * k + col];
}
C[row * k + col] = csum;
}
void gemm_0(const float* A, const float* B, float* C, int m, int n, int k, cudaStream_t stream){
dim3 block(16, 16, 1);
dim3 grid((k + block.x - 1) / block.x, (m + block.y - 1) / block.y, 1);
gemm_kernel_0<<<grid, block, 0, stream>>>(A, B, C, m, n, k);
}
// 核心思想是矩阵分块计算后累加,在高数里面利用矩阵的分块原理
// 并且利用到了共享内存技术,降低访问耗时
// Compute C = A * B
template<int BLOCK_SIZE>
__global__ void gemm_kernel_1(const float *A, const float *B, float *C, int m, int n, int k) {
__shared__ float sharedM[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float sharedN[BLOCK_SIZE][BLOCK_SIZE];
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int row = by*BLOCK_SIZE + ty;
int col = bx*BLOCK_SIZE + tx;
float v = 0.0;
for (int i = 0; i < (int)(ceil((float)n/BLOCK_SIZE)); i++)
{
if (i*BLOCK_SIZE + tx < n && row < m)
sharedM[ty][tx] = A[row*n + i*BLOCK_SIZE + tx];
else
sharedM[ty][tx] = 0.0;
if (i*BLOCK_SIZE + ty < n && col < k)
sharedN[ty][tx] = B[(i*BLOCK_SIZE + ty)*k + col];
else
sharedN[ty][tx] = 0.0;
__syncthreads();
// 每个block为一个小矩阵块
for(int j = 0; j < BLOCK_SIZE; j++)
v += sharedM[ty][j] * sharedN[j][tx];
__syncthreads();
}
if (row < m && col < k)
C[row*k + col] = v;
}
void gemm_1(const float* A, const float* B, float* C, int m, int n, int k, cudaStream_t stream){
dim3 block(16, 16, 1);
dim3 grid((k + block.x - 1) / block.x, (m + block.y - 1) / block.y, 1);
gemm_kernel_1<16><<<grid, block, 0, stream>>>(A, B, C, m, n, k);
}
输出结果如下:(我笔记本1050显卡)

1. 12 yolov5 后处理
对于shape为(608, 608, 3)的图片输入,yolov5模型的输出包括三个尺度的输出,分别为(76, 76, 255), (38, 38, 255), (19, 19, 255), 将这三个输出reshape为(76x76x3, 85), (38x38x3, 85), (19x19x3, 85), 最后进行concatenate得到(22743, 85)的输出,将其保存为二进制文件predict.data, 如下代码所示:
# predict.data是yolov5的网络输出,n*85的矩阵
pred = model(imn, training=False)
with open("../workspace/predict.data", "wb") as f:
f.write(pred.cpu().data.numpy().tobytes())
yolov5后处理主要是:预测结果中挑选大于阈值分数的检测框,并进行nms去重。下面代码分别实现了cpu和gpu版本的后处理:
main.cpp
#include <cuda_runtime.h>
#include <opencv2/opencv.hpp>
#include <stdio.h>
#include <chrono>
#include <fstream>
#include "box.hpp"
using namespace std;
using namespace cv;
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
static std::vector<uint8_t> load_file(const string& file){
ifstream in(file, ios::in | ios::binary);
if (!in.is_open())
return {};
in.seekg(0, ios::end);
size_t length = in.tellg();
std::vector<uint8_t> data;
if (length > 0){
in.seekg(0, ios::beg);
data.resize(length);
in.read((char*)&data[0], length);
}
in.close();
return data;
}
vector<Box> cpu_decode(float* predict, int rows, int cols, float confidence_threshold = 0.25f, float nms_threshold = 0.45f){
vector<Box> boxes;
int num_classes = cols - 5;
for(int i = 0; i < rows; ++i){
float* pitem = predict + i * cols; // col: x, y, w, h, conf, class1.......class80
float objness = pitem[4];
if(objness < confidence_threshold)
continue;
float* pclass = pitem + 5;
int label = std::max_element(pclass, pclass + num_classes) - pclass; // std::max_element()返回指向最大值的指针
float prob = pclass[label];
float confidence = prob * objness;
if(confidence < confidence_threshold)
continue;
float cx = pitem[0];
float cy = pitem[1];
float width = pitem[2];
float height = pitem[3];
float left = cx - width * 0.5;
float top = cy - height * 0.5;
float right = cx + width * 0.5;
float bottom = cy + height * 0.5;
// boxes.emplace_back(left, top, right, bottom, confidence, (float)label);
boxes.emplace_back(left, top, right, bottom, confidence, label);
}
std::sort(boxes.begin(), boxes.end(), [](Box& a, Box& b){return a.confidence > b.confidence;});
std::vector<bool> remove_flags(boxes.size());
std::vector<Box> box_result;
box_result.reserve(boxes.size()); // reserve容器预留空间,capacity的大小,超过时重写分配空间
auto iou = [](const Box& a, const Box& b){
float cross_left = std::max(a.left, b.left);
float cross_top = std::max(a.top, b.top);
float cross_right = std::min(a.right, b.right);
float cross_bottom = std::min(a.bottom, b.bottom);
float cross_area = std::max(0.0f, cross_right - cross_left) * std::max(0.0f, cross_bottom - cross_top);
float union_area = std::max(0.0f, a.right - a.left) * std::max(0.0f, a.bottom - a.top)
+ std::max(0.0f, b.right - b.left) * std::max(0.0f, b.bottom - b.top) - cross_area;
if(cross_area == 0 || union_area == 0) return 0.0f;
return cross_area / union_area;
};
for(int i = 0; i < boxes.size(); ++i){
if(remove_flags[i]) continue;
auto& ibox = boxes[i];
box_result.emplace_back(ibox);
for(int j = i + 1; j < boxes.size(); ++j){
if(remove_flags[j]) continue;
auto& jbox = boxes[j];
if(ibox.label == jbox.label){
// class matched
if(iou(ibox, jbox) > nms_threshold)
remove_flags[j] = true;
}
}
}
return box_result;
}
void decode_kernel_invoker(
float* predict, int num_bboxes, int num_classes, float confidence_threshold,
float nms_threshold, float* invert_affine_matrix, float* parray, int max_objects, int NUM_BOX_ELEMENT, cudaStream_t stream);
vector<Box> gpu_decode(float* predict, int rows, int cols, float confidence_threshold = 0.25f, float nms_threshold = 0.45f){
vector<Box> box_result;
cudaStream_t stream = nullptr;
checkRuntime(cudaStreamCreate(&stream));
float* predict_device = nullptr;
float* output_device = nullptr;
float* output_host = nullptr;
int max_objects = 1000;
int NUM_BOX_ELEMENT = 7; // left, top, right, bottom, confidence, class, keepflag
checkRuntime(cudaMalloc(&predict_device, rows * cols * sizeof(float)));
checkRuntime(cudaMalloc(&output_device, sizeof(float) + max_objects * NUM_BOX_ELEMENT * sizeof(float)));
checkRuntime(cudaMallocHost(&output_host, sizeof(float) + max_objects * NUM_BOX_ELEMENT * sizeof(float)));
checkRuntime(cudaMemcpyAsync(predict_device, predict, rows * cols * sizeof(float), cudaMemcpyHostToDevice, stream));
decode_kernel_invoker(
predict_device, rows, cols - 5, confidence_threshold,
nms_threshold, nullptr, output_device, max_objects, NUM_BOX_ELEMENT, stream
);
checkRuntime(cudaMemcpyAsync(output_host, output_device,
sizeof(int) + max_objects * NUM_BOX_ELEMENT * sizeof(float),
cudaMemcpyDeviceToHost, stream
));
checkRuntime(cudaStreamSynchronize(stream));
int num_boxes = min((int)output_host[0], max_objects);
for(int i = 0; i < num_boxes; ++i){
float* ptr = output_host + 1 + NUM_BOX_ELEMENT * i;
int keep_flag = ptr[6];
if(keep_flag){
box_result.emplace_back(
ptr[0], ptr[1], ptr[2], ptr[3], ptr[4], (int)ptr[5]
);
}
}
checkRuntime(cudaStreamDestroy(stream));
checkRuntime(cudaFree(predict_device));
checkRuntime(cudaFree(output_device));
checkRuntime(cudaFreeHost(output_host));
return box_result;
}
int main(){
auto data = load_file("predict.data");
auto image = cv::imread("input-image.jpg");
float* ptr = (float*)data.data();
int nelem = data.size() / sizeof(float);
int ncols = 85;
int nrows = nelem / ncols;
// 测量时间
for(int i=0; i<10; ++i){
auto t0 = std::chrono::duration_cast<std::chrono::microseconds>(std::chrono::system_clock::now().time_since_epoch()).count() / 1000.0;
//auto boxes = cpu_decode(ptr, nrows, ncols);
auto boxes = gpu_decode(ptr, nrows, ncols);
auto t1 = std::chrono::duration_cast<std::chrono::microseconds>(std::chrono::system_clock::now().time_since_epoch()).count() / 1000.0;
printf("Decode times: %.5f ms\n", t1 - t0);
}
//auto boxes = cpu_decode(ptr, nrows, ncols);
auto boxes = gpu_decode(ptr, nrows, ncols);
for(auto& box : boxes){
cv::rectangle(image, cv::Point(box.left, box.top), cv::Point(box.right, box.bottom), cv::Scalar(0, 255, 0), 2);
cv::putText(image, cv::format("%.2f", box.confidence), cv::Point(box.left, box.top - 7), 0, 0.8, cv::Scalar(0, 0, 255), 2, 16);
}
cv::imshow("img", image);
cv::waitKey(0);
cv::destroyAllWindows();
// cv::imwrite("image-draw.jpg", image);
return 0;
}
box.hpp
#ifndef BOX_HPP
#define BOX_HPP
struct Box{
float left, top, right, bottom, confidence;
int label;
Box() = default;
Box(float left, float top, float right, float bottom, float confidence, int label):
left(left), top(top), right(right), bottom(bottom), confidence(confidence), label(label){}
};
#endif // BOX_HPP
gpu_decode.cu
#include <cuda_runtime.h>
#define min(a, b) ((a)<(b)?(a):(b))
#define max(a, b) ((a)>(b)?(a):(b))
static __device__ void affine_project(float* matrix, float x, float y, float* ox, float* oy){
*ox = matrix[0] * x + matrix[1] * y + matrix[2];
*oy = matrix[3] * x + matrix[4] * y + matrix[5];
}
static __global__ void decode_kernel(
float* predict, int num_bboxes, int num_classes, float confidence_threshold,
float* invert_affine_matrix, float* parray, int max_objects, int NUM_BOX_ELEMENT
){
int position = blockDim.x * blockIdx.x + threadIdx.x;
if (position >= num_bboxes) return;
float* pitem = predict + (5 + num_classes) * position;
float objectness = pitem[4];
if(objectness < confidence_threshold)
return;
// 分数最高的类别
float* class_confidence = pitem + 5;
float confidence = *class_confidence++;
int label = 0;
for(int i = 1; i < num_classes; ++i, ++class_confidence){
if(*class_confidence > confidence){
confidence = *class_confidence;
label = i;
}
}
confidence *= objectness;
if(confidence < confidence_threshold)
return;
int index = atomicAdd(parray, 1);
if(index >= max_objects)
return;
float cx = *pitem++;
float cy = *pitem++;
float width = *pitem++;
float height = *pitem++;
float left = cx - width * 0.5f;
float top = cy - height * 0.5f;
float right = cx + width * 0.5f;
float bottom = cy + height * 0.5f;
// affine_project(invert_affine_matrix, left, top, &left, &top);
// affine_project(invert_affine_matrix, right, bottom, &right, &bottom);
// left, top, right, bottom, confidence, class, keepflag
float* pout_item = parray + 1 + index * NUM_BOX_ELEMENT;
*pout_item++ = left;
*pout_item++ = top;
*pout_item++ = right;
*pout_item++ = bottom;
*pout_item++ = confidence;
*pout_item++ = label;
*pout_item++ = 1; // 1 = keep, 0 = ignore
}
static __device__ float box_iou(
float aleft, float atop, float aright, float abottom,
float bleft, float btop, float bright, float bbottom
){
float cleft = max(aleft, bleft);
float ctop = max(atop, btop);
float cright = min(aright, bright);
float cbottom = min(abottom, bbottom);
float c_area = max(cright - cleft, 0.0f) * max(cbottom - ctop, 0.0f);
if(c_area == 0.0f)
return 0.0f;
float a_area = max(0.0f, aright - aleft) * max(0.0f, abottom - atop);
float b_area = max(0.0f, bright - bleft) * max(0.0f, bbottom - btop);
return c_area / (a_area + b_area - c_area);
}
static __global__ void fast_nms_kernel(float* bboxes, int max_objects, float threshold, int NUM_BOX_ELEMENT){
int position = (blockDim.x * blockIdx.x + threadIdx.x);
int count = min((int)*bboxes, max_objects);
if (position >= count)
return;
// left, top, right, bottom, confidence, class, keepflag
float* pcurrent = bboxes + 1 + position * NUM_BOX_ELEMENT;
for(int i = 0; i < count; ++i){
float* pitem = bboxes + 1 + i * NUM_BOX_ELEMENT;
if(i == position || pcurrent[5] != pitem[5]) continue;
if(pitem[4] >= pcurrent[4]){
if(pitem[4] == pcurrent[4] && i < position)
continue;
float iou = box_iou(
pcurrent[0], pcurrent[1], pcurrent[2], pcurrent[3],
pitem[0], pitem[1], pitem[2], pitem[3]
);
if(iou > threshold){
pcurrent[6] = 0; // 1=keep, 0=ignore
return;
}
}
}
}
void decode_kernel_invoker(
float* predict, int num_bboxes, int num_classes, float confidence_threshold,
float nms_threshold, float* invert_affine_matrix, float* parray, int max_objects, int NUM_BOX_ELEMENT, cudaStream_t stream){
auto block = num_bboxes > 512 ? 512 : num_bboxes;
auto grid = (num_bboxes + block - 1) / block;
/* 如果核函数有波浪线,没关系,他是正常的,你只是看不顺眼罢了 */
decode_kernel<<<grid, block, 0, stream>>>(
predict, num_bboxes, num_classes, confidence_threshold,
invert_affine_matrix, parray, max_objects, NUM_BOX_ELEMENT
);
block = max_objects > 512 ? 512 : max_objects;
grid = (max_objects + block - 1) / block;
fast_nms_kernel<<<grid, block, 0, stream>>>(parray, max_objects, nms_threshold, NUM_BOX_ELEMENT);
}
需要注意的时,上述代码中测试gpu_decode()和cpu_decode()的时间时,gpu_decode()时间会比较长,这是因为这里存在一个gpu和cpu数据拷贝的过程,实际我们推理使用时,推理结果就在gpu上,不会存在这个问题,我们可以通过cudaEvent来只测试gpu核函数的时间来获取真实的gpu_decode时间,如下代码:
std::vector<Box> gpu_decode(float* predict, int rows, int cols, float confidence_threshold = 0.25f, float nms_threshold = 0.45f) {
std::vector<Box> box_result;
cudaStream_t stream = nullptr;
checkRuntime(cudaStreamCreate(&stream));
cudaEvent_t t0, t1;
cudaEventCreate(&t0);
cudaEventCreate(&t1);
float* predict_device = nullptr;
float* output_device = nullptr;
float* output_host = nullptr;
int max_objects = 1000;
int NUM_BOX_ELEMENT = 7; // left, top, right, bottom, confidence, class, keepflag
checkRuntime(cudaMalloc(&predict_device, rows*cols * sizeof(float)));
checkRuntime(cudaMalloc(&output_device, max_objects*NUM_BOX_ELEMENT * sizeof(float) + sizeof(float)));
checkRuntime(cudaMallocHost(&output_host, max_objects*NUM_BOX_ELEMENT * sizeof(float) + sizeof(float)));
checkRuntime(cudaMemcpyAsync(predict_device, predict, rows*cols * sizeof(float), cudaMemcpyHostToDevice, stream));
cudaEventRecord(t0, stream);
decode_kernel_invoker(predict_device, rows, cols - 5, confidence_threshold, nms_threshold,
nullptr, output_device, max_objects, NUM_BOX_ELEMENT, stream);
cudaEventRecord(t1, stream);
checkRuntime(cudaMemcpyAsync(output_host, output_device,
max_objects*NUM_BOX_ELEMENT * sizeof(float) + sizeof(float), cudaMemcpyDeviceToHost, stream));
checkRuntime(cudaStreamSynchronize(stream));
//除去gup和cpu拷贝后,核函数真实执行时间
float gpu_decode_time = 0;
cudaEventElapsedTime(&gpu_decode_time, t0, t1);
printf("gpu decode kernel function: %.2f ms\n", gpu_decode_time);
int num_boxes = std::min((int)output_host[0], max_objects);
for (int i = 0; i < num_boxes; ++i) {
float* ptr = output_host+1+NUM_BOX_ELEMENT*i;
int keep_flag = ptr[6];
if (keep_flag) {
box_result.emplace_back(Box(ptr[0], ptr[1], ptr[2], ptr[3], ptr[4], (int)ptr[5]));
}
}
checkRuntime(cudaStreamDestroy(stream));
checkRuntime(cudaFree(output_device));
checkRuntime(cudaFree(predict_device));
checkRuntime(cudaFreeHost(output_host));
cudaEventDestroy(t0);
cudaEventDestroy(t1);
return box_result;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧