
siamrpn代码细节
1. 训练
1.1 数据预处理:
得到视频每一帧的图片和对应xml标注文件(和目标检测类似,每个目标的box和name),将图片中的每个目标切割出来,存储为子图。截取过程如下:
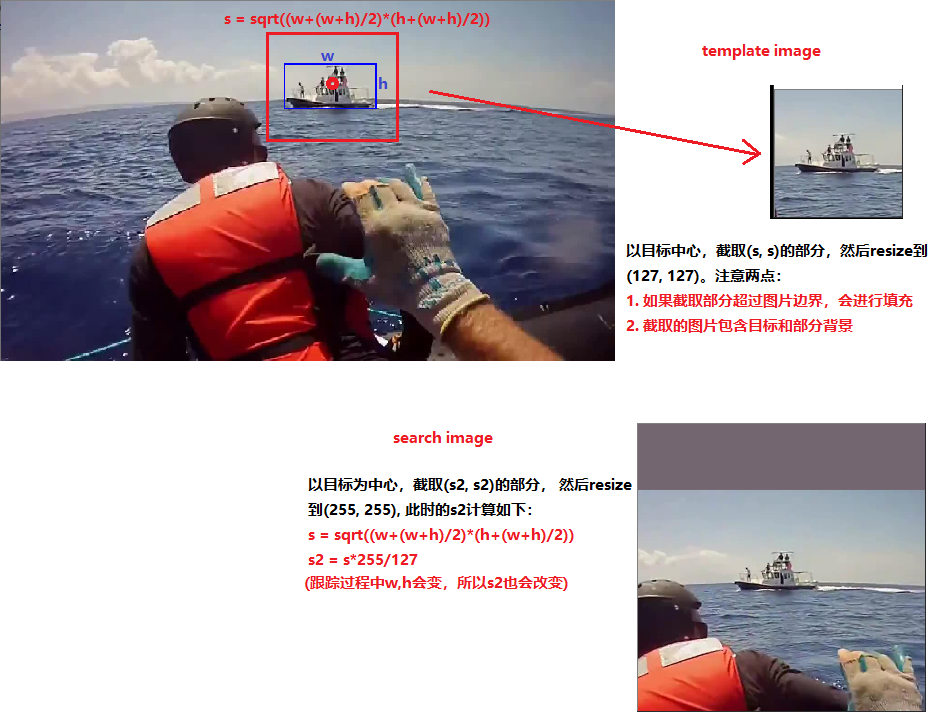
- 以目标中心点为中心,长和宽分别为s_x,截取图片并缩放到(instance_size, instance_size);
- instance_size默认为255,gluoncv中也设置为511
截取代码如下:
# image: 原始视频中每一帧的图片,box为图片中目标的box, x为截取出来的子图,保存x为图片
def crop_like_SiamFC(image, bbox, context_amount=0.5, exemplar_size=127, instance_size=255, padding=(0, 0, 0)):
"""
Dataset curation and avoid image resizing during training
if the tight bounding box has size (w, h) and the context margin is p,
then the scale factor s is chosen such that the area of the scaled rectangle is equal to a constant
s(w+2p)×s(h+2p)=A.
Parameters
----------
image: np.array, image
bbox: list or np.array, bbox
context_amount: float, the amount of context to be half of the mean dimension
exemplar_size: int, exemplar_size
instance_size: int, instance_size
Return:
crop result exemplar z and instance x
"""
target_pos = [(bbox[2]+bbox[0])/2., (bbox[3]+bbox[1])/2.]
target_size = [bbox[2]-bbox[0], bbox[3]-bbox[1]]
wc_z = target_size[1] + context_amount * sum(target_size)
hc_z = target_size[0] + context_amount * sum(target_size)
s_z = np.sqrt(wc_z * hc_z)
scale_z = exemplar_size / s_z
d_search = (instance_size - exemplar_size) / 2
pad = d_search / scale_z
s_x = s_z + 2 * pad
z = crop_hwc(image, pos_s_2_bbox(target_pos, s_z), exemplar_size, padding)
x = crop_hwc(image, pos_s_2_bbox(target_pos, s_x), instance_size, padding)
return z, x
def pos_s_2_bbox(pos, s):
"""
from center_x,center_y,s to get bbox
Parameters
----------
pos , x, bbox
s , int, bbox size
Return:
[x_min,y_min,x_max,y_max]
"""
return [pos[0]-s/2, pos[1]-s/2, pos[0]+s/2, pos[1]+s/2]
def crop_hwc(image, bbox, out_sz, padding=(0, 0, 0)):
"""
crop image
Parameters
----------
image: np.array, image
bbox: np or list, bbox coordinate [xmin,ymin,xmax,ymax]
out_sz: int , crop image size
Return:
crop result
"""
a = (out_sz-1) / (bbox[2]-bbox[0])
b = (out_sz-1) / (bbox[3]-bbox[1])
c = -a * bbox[0]
d = -b * bbox[1]
mapping = np.array([[a, 0, c],
[0, b, d]]).astype(np.float)
cv2 = try_import_cv2()
crop = cv2.warpAffine(image, mapping, (out_sz, out_sz), borderMode=cv2.BORDER_CONSTANT, borderValue=padding)
return crop
1.2 数据加载和增强
- 通过上面预处理,对于目标x,在视频1-100帧图片中都有目标x,会切出100张x的子图:
image_x_0.jpg, image_x_1.jpg,......,image_x_100.jpg - 对于目标x,假设加载image_x_20.jpg(第20帧),将其作为tempate_image, 在20帧的前后10帧随机挑选一张作为search_image
- 对于tempate_image进行数据增强,主要是随机平移,缩放,颜色变换,模糊,翻转,最后缩放到(127, 127)
- 对于search_image进行数据增强,主要是随机平移,缩放,颜色变换,模糊,翻转,最后缩放到(255, 255)
- 根据search_image的bbox计算gt_label, 包括cls, delta, delta_weight,其中cls表示每个anchor是正样本,负样本和忽略样本,delta维度为4,表示 bbox中心点相对于anchor中心点的偏移值dx, dy,以及bbox的宽高w,h;delta_weight表示正样本权重,值为1\num_pos。有两点值得注意:
- anchor映射为search_image只包括search_image中间128x128的区域,所以设置的anchor左上角中心点为(63, 63), 右下角为(63+128, 63+128)
- 为了平衡正负样本的比例,会根据anchor和gt_box的IOU挑选64个样本给RPN网络学习 ,(计算所有anchor和gt_box的IOU, IOU>0.6的为正样本,IOU<0.3的为负样本)
(search_image尺寸为255x255,中间[63, 63, 63+128, 63+128]的区域降采样8倍后,对应17x17的feature_map)

数据增强部分的代码
# data augmentation
self.template_aug = SiamRPNaugmentation(self.template_shift,
self.template_scale,
self.template_blur,
self.template_flip,
self.template_color)
self.search_aug = SiamRPNaugmentation(self.search_shift,
self.search_scale,
self.search_blur,
self.search_flip,
self.search_color)
# augmentation
template, _ = self.template_aug(template_image,
template_box,
self.train_exemplar_size, # 默认为127
gray=gray)
search, bbox = self.search_aug(search_image,
search_box,
self.train_search_size, # 默认为255
gray=gray)
class SiamRPNaugmentation:
"""dataset Augmentation for SiamRPN tracking.
Parameters
----------
shift : int
length of template augmentation shift
scale : float
template augmentation scale ratio
blur : float
template augmentation blur ratio
flip : float
template augmentation flip ratio
color : float
template augmentation color ratio
"""
def __init__(self, shift, scale, blur, flip, color):
self.shift = shift
self.scale = scale
self.blur = blur
self.flip = flip
self.color = color
self.rgbVar = np.array([[-0.55919361, 0.98062831, - 0.41940627],
[1.72091413, 0.19879334, - 1.82968581],
[4.64467907, 4.73710203, 4.88324118]], dtype=np.float32)
self.cv2 = try_import_cv2()
@staticmethod
def random():
return np.random.random() * 2 - 1.0
def _crop_roi(self, image, bbox, out_sz, padding=(0, 0, 0)):
"""crop image roi size.
Parameters
----------
image : np.array
image
bbox : list or np.array
bbox coordinate,like (xmin,ymin,xmax,ymax)
out_sz : int
size after crop
Return:
image after crop
"""
bbox = [float(x) for x in bbox]
a = (out_sz-1) / (bbox[2]-bbox[0])
b = (out_sz-1) / (bbox[3]-bbox[1])
c = -a * bbox[0]
d = -b * bbox[1]
mapping = np.array([[a, 0, c],
[0, b, d]]).astype(np.float)
crop = self.cv2.warpAffine(image, mapping, (out_sz, out_sz),
borderMode=self.cv2.BORDER_CONSTANT,
borderValue=padding)
return crop
def _blur_aug(self, image):
"""blur filter to smooth image
Parameters
----------
image : np.array
image
Return:
image after blur
"""
def rand_kernel():
sizes = np.arange(5, 46, 2)
size = np.random.choice(sizes)
kernel = np.zeros((size, size))
c = int(size/2)
wx = np.random.random()
kernel[:, c] += 1. / size * wx
kernel[c, :] += 1. / size * (1-wx)
return kernel
kernel = rand_kernel()
image = self.cv2.filter2D(image, -1, kernel)
return image
def _color_aug(self, image):
"""Random increase of image channel
Parameters
----------
image : np.array
image
Return:
image after Random increase of channel
"""
offset = np.dot(self.rgbVar, np.random.randn(3, 1))
offset = offset[::-1] # bgr 2 rgb
offset = offset.reshape(3)
image = image - offset
return image
def _gray_aug(self, image):
"""image Grayscale
Parameters
----------
image : np.array
image
Return:
image after Grayscale
"""
grayed = self.cv2.cvtColor(image, self.cv2.COLOR_BGR2GRAY)
image = self.cv2.cvtColor(grayed, self.cv2.COLOR_GRAY2BGR)
return image
def _shift_scale_aug(self, image, bbox, crop_bbox, size):
"""shift scale augmentation
Parameters
----------
image : np.array
image
bbox : list or np.array
bbox
crop_bbox :
crop size image from center
Return
image ,bbox after shift and scale
"""
im_h, im_w = image.shape[:2]
# adjust crop bounding box
crop_bbox_center = corner2center(crop_bbox)
if self.scale:
scale_x = (1.0 + SiamRPNaugmentation.random() * self.scale)
scale_y = (1.0 + SiamRPNaugmentation.random() * self.scale)
h, w = crop_bbox_center.h, crop_bbox_center.w
scale_x = min(scale_x, float(im_w) / w)
scale_y = min(scale_y, float(im_h) / h)
crop_bbox_center = Center(crop_bbox_center.x,
crop_bbox_center.y,
crop_bbox_center.w * scale_x,
crop_bbox_center.h * scale_y)
crop_bbox = center2corner(crop_bbox_center)
if self.shift:
sx = SiamRPNaugmentation.random() * self.shift
sy = SiamRPNaugmentation.random() * self.shift
x1, y1, x2, y2 = crop_bbox
sx = max(-x1, min(im_w - 1 - x2, sx))
sy = max(-y1, min(im_h - 1 - y2, sy))
crop_bbox = Corner(x1 + sx, y1 + sy, x2 + sx, y2 + sy)
# adjust target bounding box
x1, y1 = crop_bbox.x1, crop_bbox.y1
bbox = Corner(bbox.x1 - x1, bbox.y1 - y1,
bbox.x2 - x1, bbox.y2 - y1)
if self.scale:
bbox = Corner(bbox.x1 / scale_x, bbox.y1 / scale_y,
bbox.x2 / scale_x, bbox.y2 / scale_y)
image = self._crop_roi(image, crop_bbox, size)
return image, bbox
def _flip_aug(self, image, bbox):
"""flip augmentation
Parameters
----------
image : np.array
image
bbox : list or np.array
bbox
Return
image and bbox after filp
"""
image = self.cv2.flip(image, 1)
width = image.shape[1]
bbox = Corner(width - 1 - bbox.x2, bbox.y1,
width - 1 - bbox.x1, bbox.y2)
return image, bbox
def __call__(self, image, bbox, size, gray=False):
shape = image.shape
crop_bbox = center2corner(Center(shape[0]//2, shape[1]//2,
size-1, size-1))
# gray augmentation
if gray:
image = self._gray_aug(image)
# shift scale augmentation
image, bbox = self._shift_scale_aug(image, bbox, crop_bbox, size)
# color augmentation
if self.color > np.random.random():
image = self._color_aug(image)
# blur augmentation
if self.blur > np.random.random():
image = self._blur_aug(image)
# flip augmentation
if self.flip and self.flip > np.random.random():
image, bbox = self._flip_aug(image, bbox)
return image, bbox
anchorTarget部分代码
# create anchor target
self.anchor_target = AnchorTarget(anchor_stride=self.anchor_stride,
anchor_ratios=self.anchor_ratios,
train_search_size=self.train_search_size,
train_output_size=self.train_output_size,
train_thr_high=self.train_thr_high,
train_thr_low=self.train_thr_low,
train_pos_num=self.train_pos_num,
train_neg_num=self.train_neg_num,
train_total_num=self.train_total_num)
# get labels
cls, delta, delta_weight, _ = self.anchor_target(bbox, self.train_output_size, neg)
template = template.transpose((2, 0, 1)).astype(np.float32)
search = search.transpose((2, 0, 1)).astype(np.float32)
return template, search, cls, delta, delta_weight, np.array(bbox)
class AnchorTarget:
def __init__(self, anchor_stride, anchor_ratios, train_search_size, train_output_size,
train_thr_high=0.6, train_thr_low=0.3, train_pos_num=16, train_neg_num=16,
train_total_num=64):
"""create anchor target
Parameters
----------
anchor_stride : int
anchor stride
anchor_ratios : tuple
anchor ratios
train_search_size : int
train search size
train_output_size : int
train output size
train_thr_high : float
Positive anchor threshold
train_thr_low : float
Negative anchor threshold
train_pos_num : int
Number of Positive
train_neg_num : int
Number of Negative
train_total_num : int
total number
"""
self.anchor_stride = anchor_stride
self.anchor_ratios = anchor_ratios
self.anchor_scales = [8]
self.anchors = Anchors(self.anchor_stride,
self.anchor_ratios,
self.anchor_scales)
self.train_search_size = train_search_size
self.train_output_size = train_output_size
self.anchors.generate_all_anchors(im_c=self.train_search_size//2,
size=self.train_output_size)
self.train_thr_high = train_thr_high
self.train_thr_low = train_thr_low
self.train_pos_num = train_pos_num
self.train_neg_num = train_neg_num
self.train_total_num = train_total_num
def __call__(self, target, size, neg=False):
anchor_num = len(self.anchor_ratios) * len(self.anchor_scales)
# -1 ignore 0 negative 1 positive
cls = -1 * np.ones((anchor_num, size, size), dtype=np.int64)
delta = np.zeros((4, anchor_num, size, size), dtype=np.float32)
delta_weight = np.zeros((anchor_num, size, size), dtype=np.float32)
def select(position, keep_num=16):
num = position[0].shape[0]
if num <= keep_num:
return position, num
slt = np.arange(num)
np.random.shuffle(slt)
slt = slt[:keep_num]
return tuple(p[slt] for p in position), keep_num
tcx, tcy, tw, th = corner2center(target)
if neg:
cx = size // 2
cy = size // 2
cx += int(np.ceil((tcx - self.train_search_size // 2) /
self.anchor_stride + 0.5))
cy += int(np.ceil((tcy - self.train_search_size // 2) /
self.anchor_stride + 0.5))
l = max(0, cx - 3)
r = min(size, cx + 4)
u = max(0, cy - 3)
d = min(size, cy + 4)
cls[:, u:d, l:r] = 0
neg, _ = select(np.where(cls == 0), self.train_neg_num)
cls[:] = -1
cls[neg] = 0
overlap = np.zeros((anchor_num, size, size), dtype=np.float32)
return cls, delta, delta_weight, overlap
anchor_box = self.anchors.all_anchors[0]
anchor_center = self.anchors.all_anchors[1]
x1, y1, x2, y2 = anchor_box[0], anchor_box[1], \
anchor_box[2], anchor_box[3]
cx, cy, w, h = anchor_center[0], anchor_center[1], \
anchor_center[2], anchor_center[3]
delta[0] = (tcx - cx) / w
delta[1] = (tcy - cy) / h
delta[2] = np.log(tw / w)
delta[3] = np.log(th / h)
target = np.array([target[0], target[1], target[2], target[3]]).reshape(1, -1)
bbox = np.array([x1, y1, x2, y2]).reshape(4, -1).T
overlap = bbox_iou(bbox, target)
overlap = overlap.reshape(-1, self.train_output_size, self.train_output_size)
pos = np.where(overlap > self.train_thr_high)
neg = np.where(overlap < self.train_thr_low)
pos, pos_num = select(pos, self.train_pos_num)
neg, _ = select(neg, self.train_total_num - self.train_pos_num)
cls[pos] = 1
delta_weight[pos] = 1. / (pos_num + 1e-6)
cls[neg] = 0
return cls, delta, delta_weight, overlap
1.3 训练流程
训练流程大致如下:
-
从上述训练数据中,加载两张图片template_img, search_img, 以及search_img对应的cls_label, delta, delta_weight
-
将两张图片template_img, search_img输入网络, 网络输出pred_cls, pred_loc, pred_cls表示anchor是否是目标的分数置信度, pred_loc表示目标相对于anchor的中心点偏移值和宽高
-
根据真实数据cls_label, delta, delta_weight, 以及预测数据pred_cls, pred_loc, 计算总的loss。(类别损失用交叉熵,位置损失用带权重的L1损失)
训练代码
for i, data in enumerate(train_loader):
template, search, label_cls, label_loc, label_loc_weight = train_batch_fn(data, opt)
cls_losses = []
loc_losses = []
total_losses = []
with autograd.record():
for j in range(len(opt.ctx)):
cls, loc = net(template[j], search[j])
label_cls_temp = label_cls[j].reshape(-1).asnumpy()
pos_index = np.argwhere(label_cls_temp == 1).reshape(-1)
neg_index = np.argwhere(label_cls_temp == 0).reshape(-1)
if len(pos_index):
pos_index = nd.array(pos_index, ctx=opt.ctx[j])
else:
pos_index = nd.array(np.array([]), ctx=opt.ctx[j])
if len(neg_index):
neg_index = nd.array(neg_index, ctx=opt.ctx[j])
else:
neg_index = nd.array(np.array([]), ctx=opt.ctx[j])
cls_loss, loc_loss = criterion(cls, loc, label_cls[j], pos_index, neg_index,
label_loc[j], label_loc_weight[j])
total_loss = opt.cls_weight*cls_loss+opt.loc_weight*loc_loss
cls_losses.append(cls_loss)
loc_losses.append(loc_loss)
total_losses.append(total_loss)
mx.nd.waitall()
if opt.use_amp:
with amp.scale_loss(total_losses, trainer) as scaled_loss:
autograd.backward(scaled_loss)
else:
autograd.backward(total_losses)
trainer.step(batch_size)
loss_total_val += sum([l.mean().asscalar() for l in total_losses]) / len(total_losses)
loss_loc_val += sum([l.mean().asscalar() for l in loc_losses]) / len(loc_losses)
loss_cls_val += sum([l.mean().asscalar() for l in cls_losses]) / len(cls_losses)
if i%(opt.log_interval) == 0:
logger.info('Epoch %d iteration %04d/%04d: loc loss %.3f, cls loss %.3f, \
training loss %.3f, batch time %.3f'% \
(epoch, i, len(train_loader), loss_loc_val/(i+1), loss_cls_val/(i+1),
loss_total_val/(i+1), time.time()-batch_time))
batch_time = time.time()
mx.nd.waitall()
# save every epoch
if opt.no_val:
save_checkpoint(net, opt, epoch, False)
损失函数代码
class SiamRPNLoss(gluon.HybridBlock):
r"""Weighted l1 loss and cross entropy loss for SiamRPN training
Parameters
----------
batch_size : int, default 128
training batch size per device (CPU/GPU).
"""
def __init__(self, batch_size=128, **kwargs):
super(SiamRPNLoss, self).__init__(**kwargs)
self.conf_loss = gluon.loss.SoftmaxCrossEntropyLoss()
self.h = 17
self.w = 17
self.b = batch_size
self.loc_c = 10
self.cls_c = 5
def weight_l1_loss(self, F, pred_loc, label_loc, loss_weight):
"""Compute weight_l1_loss"""
pred_loc = pred_loc.reshape((self.b, 4, -1, self.h, self.w))
diff = F.abs((pred_loc - label_loc))
diff = F.sum(diff, axis=1).reshape((self.b, -1, self.h, self.w))
loss = diff * loss_weight
return F.sum(loss)/self.b
def get_cls_loss(self, F, pred, label, select):
"""Compute SoftmaxCrossEntropyLoss"""
if len(select) == 0:
return 0
pred = F.gather_nd(pred, select.reshape(1, -1))
label = F.gather_nd(label.reshape(-1, 1), select.reshape(1, -1)).reshape(-1)
return self.conf_loss(pred, label).mean()
def cross_entropy_loss(self, F, pred, label, pos_index, neg_index):
"""Compute cross_entropy_loss"""
pred = pred.reshape(self.b, 2, self.loc_c//2, self.h, self.h)
pred = F.transpose(pred, axes=((0, 2, 3, 4, 1)))
pred = pred.reshape(-1, 2)
label = label.reshape(-1)
loss_pos = self.get_cls_loss(F, pred, label, pos_index)
loss_neg = self.get_cls_loss(F, pred, label, neg_index)
return loss_pos * 0.5 + loss_neg * 0.5
def hybrid_forward(self, F, cls_pred, loc_pred, label_cls, pos_index, neg_index,
label_loc, label_loc_weight):
"""Compute loss"""
loc_loss = self.weight_l1_loss(F, loc_pred, label_loc, label_loc_weight)
cls_loss = self.cross_entropy_loss(F, cls_pred, label_cls, pos_index, neg_index)
return cls_loss, loc_loss
2. 测试时跟踪过程
跟踪过程大致可以分为几步:
1.从第一帧图片中,以跟踪目标的中心点截取127*127的区域,作为template
2.在随后的图片中,以上一帧跟踪目标的中心点截取255*255的区域,作为search
3.将template,search送入siamrpn网络预测出目标的box和score
4.对score进行两次后处理, 一是scale penalty和ratio penalty;二是window penalty,即采用窗函数(汉宁窗,余弦窗等)对距离中心点较远的边缘区域分数进行惩罚。
5.取分数最高的box中心点作为新的中心点,上一帧目标的宽高和box的宽高进行平滑加权作为新的宽高
6.采用新的中心点和宽高作为当前帧的box
详细解释如下:
2.1 template和search截取
template设置的大小为(127, 127), search设置为(255, 255), 可以进行调整。(gluoncv中search设置为(287, 287)?)
2.2 后处理一:尺度和宽高比惩罚
outputs = self.model.track(x_crop)
#get coordinate
pred_bbox = self._convert_bbox(outputs['loc'], self.anchors) #预测的box:[x_center, y_center, w, h]
#get cls
score = self._convert_score(outputs['cls']) #预测的置信度
def change(hw_r): # 保证比值大于等于1
return np.maximum(hw_r, 1. / hw_r)
def get_scale(bbox_w, bbox_h):
pad = (bbox_w + bbox_h) * 0.5
return np.sqrt((bbox_w + pad) * (bbox_h + pad))
# scale penalty,
# compare the overall scale of the proposal and last frame
s_c = change(get_scale(pred_bbox[2, :], pred_bbox[3, :]) /
(get_scale(self.size[0]*scale_z, self.size[1]*scale_z))) # 尺度变化率:self.size=[w, h], 预测box和上一帧box的尺度比值
# aspect ratio penalty. ratio is ratio of height and width.
# compare proposal’s ratio and last frame
r_c = change((self.size[0]/self.size[1]) /
(pred_bbox[2, :]/pred_bbox[3, :])) # 宽高比变换率
penalty = np.exp(-(r_c * s_c - 1) * self.PENALTY_K) # 默认self.PENALTY_K=0.16, r_c>=1, s_c>=1, 变化率越大惩罚越大
pscore = penalty * score
2.3 后处理二:汉宁窗(Hanning)
汉宁窗定义:
汉宁窗采用余弦函数,其定义为:
例如构建一个长度为4的汉宁窗,就是取M=4, n依次取0,1,2,3计算函数值:
假设要构建4x4的二维汉宁窗,可以直接采用上面一维汉宁窗构建:\(ww^T\):
4x4汉宁窗
[[0. 0. 0. 0. ]
[0. 0.5625 0.5625 0. ]
[0. 0.5625 0.5625 0. ]
[0. 0. 0. 0. ]]
采用numpy构建汉宁窗代码如下:
import numpy as np
# 构建一个4x4的汉宁窗:
def hanning(size=4):
hanning = np.hanning(size) # shape(4, )
print(hanning, hanning.shape)
window = np.outer(hanning, hanning) # shape(4, 4): hanning*(hanning)^T
print(window, window.shape)
if __name__ == "__main__":
hanning(4)
汉宁窗使用:
hanning = np.hanning(self.score_size) # shape(17)
window = np.outer(hanning, hanning) # shape(17, 17)
self.window = np.tile(window.flatten(), self.anchor_num) # shape(17*17, 5)
self.WINDOW_INFLUENCE = 0.4
# window penalty
pscore = pscore * (1 - self.WINDOW_INFLUENCE) + \
self.window * self.WINDOW_INFLUENCE # pscore为进行scale+ratio penealty后的预测分数, self.window为汉宁窗分数,两者进行加权平均
2.4 更新box
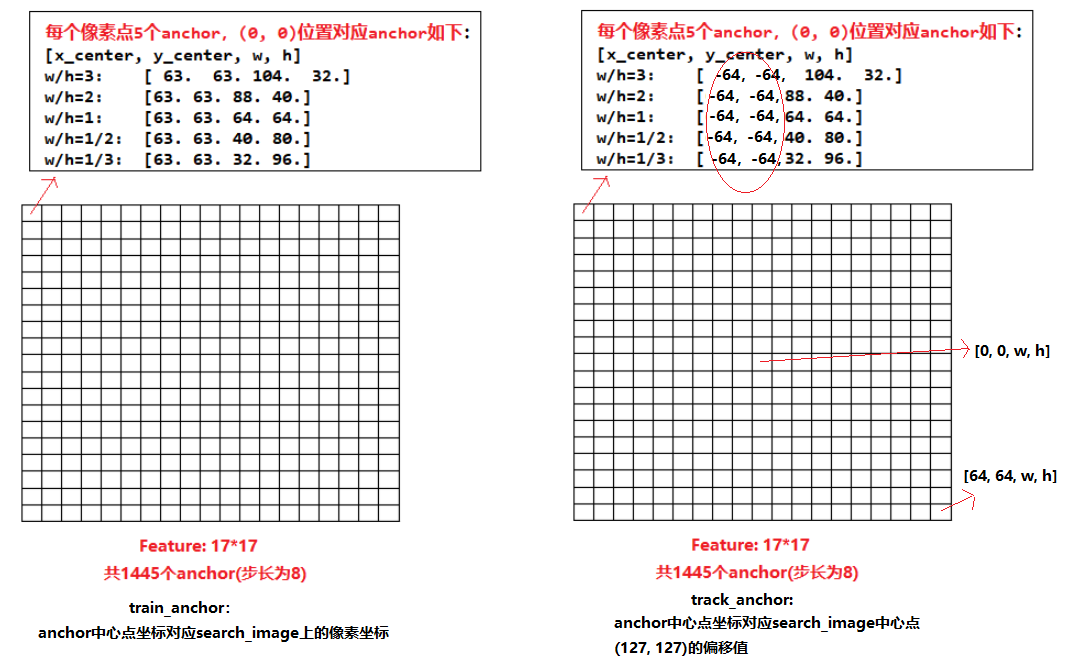
1. anchor理解
对于模型输出的loc和cls进行解码,这里有两点要注意:
- 对cls先进行解码后,然后进行上述的两步后处理进行惩罚,会改变分数的大小, 最后再挑选分数最高的bbox
- 对bbox进行解码时,采用的anchor与训练时anchor有一点点小差异,两个train_anchor和track_anchor的中心点不一样,宽高一样
如下图中左边是train_anchor, 右边是track_anchor, 两者差别如下:
- train_anchor中心点坐标对应search_image上的像素坐标
- track_anchor中心点坐标对应其相对于search_image中心点(127, 127)的偏移值
2. box解码
box解码代码逻辑如下:
def _convert_bbox(self, delta, anchor):
"""from loc to predict postion
Parameters
----------
delta : ndarray or np.ndarray
network output
anchor : np.ndarray
generate anchor location
Returns
-------
rejust predict postion though Anchor
"""
delta = nd.transpose(delta, axes=(1, 2, 3, 0))
delta = nd.reshape(delta, shape=(4, -1))
delta = delta.asnumpy()
delta[0, :] = delta[0, :] * anchor[:, 2] + anchor[:, 0]
delta[1, :] = delta[1, :] * anchor[:, 3] + anchor[:, 1]
delta[2, :] = np.exp(delta[2, :]) * anchor[:, 2]
delta[3, :] = np.exp(delta[3, :]) * anchor[:, 3]
return delta
上述需要理解的代码为:
delta[0, :] = delta[0, :] * anchor[:, 2] + anchor[:, 0]
delta[0, :] * anchor[:, 2]表示网络预测的目标中心点相对于anchor中心点的距离anchor[:, 0]表示anchor中心点相对于(127, 127)的偏移值。而(127, 127)就是search_image的中心点,即template_image中目标中心点位置- 综合上述,
delta[0, :] * anchor[:, 2] + anchor[:, 0]表示的就是预测的目标中心点相对于template_image中目标中心点的偏移位置
所以最终,box更新表达式如下:
center_x = bbox[0] + self.center_pos[0] # center_pos为上一帧目标的中心点, bbox为网络预测的相对于目标中心点的偏移位置
center_y = bbox[1] + self.center_pos[1]
# clip boundary
center_x, center_y, width, height = self._bbox_clip(center_x, center_y, width, height, img.shape[:2])
self.center_pos = np.array([center_x, center_y])
2.5 宽高更新
宽高更新比较简单,原始box的宽高和预测宽高的加权平均:
# smooth bbox
penalty_lr = penalty[best_idx] * score[best_idx] * self.LR # penalty为形变和比例惩罚分数,score为网络预测分数,默认self.LR=0.3
width = self.size[0] * (1 - penalty_lr) + bbox[2] * penalty_lr
height = self.size[1] * (1 - penalty_lr) + bbox[3] * penalty_lr
# clip boundary
center_x, center_y, width, height = self._bbox_clip(center_x, center_y, width, height, img.shape[:2])
self.size = np.array([width, height])

