ransac算法思想
Ransac: Random Sample Consensus, 随机抽样一致性。RANSAC算法在1981年由Fischler和Bolles首次提出。
Ransac是一种通过使用观测到的数据点来估计数学模型参数的迭代方法。其中数据点包括内点(inlier),外点(outlier)。outlier对模型的估计没有价值,因此该方法也可以叫做outlier检测方法。其中inliners指样本中正确的的样本点,常称为内点,内群点,正确样本,outliners指样本中的噪声点(如测量时误差很大的点,数据值不准确的点等),常称为外点,离群点,噪声点。
所以通俗点将,就是我们有一组观测数据,但是数据点中有很多噪声点,如果我们直接用模型来拟合数据,模型肯定会受噪声点影响,而且噪声点比例越大,拟合出的模型也会越不准确。Ransac就是用来解决样本中的外点问题(噪声),最多可处理50%的外点情况。
1. Ransac的假设和思想
再深入点讨论,有一组观测数据,要建立一个模型来拟合数据,我们第一步要做的,肯定是用一个标准对数据进行筛选,去除噪声点,让数据尽量干净和准确。但是如果我们没有一个合适的筛选标准,该怎么办呢?我们可以假设:观测数据中除了外点(噪声),肯定存在内点(准确点),而且内点的个数够我们用来拟合一个模型(比如拟合一条直线,至少要两个数据点)。有了这个假设,我们可以从观测数据中随机挑选出n个数据点,用这n个点来拟合模型,然后对这个模型进行评价。如果通过迭代,反复重复这个过程,只要迭代次数过大,我们随机挑选出来的n个样本点是有可能全部是内点的,再配合上模型评价,就能找到最优的拟合模型。这就是ransac的主要假设和思想,官方叙述如下:
- RANSAC的基本假设是 “内群”数据可以通过几组模型参数来叙述其数据分布,而“离群”数据则 是不适合模型化的数据。 数据会受噪声影响, 噪声指的是离群:例如从极端的噪声, 错误解释有关数据的测量, 或不正确的假设。RANSAC假定,给定一组(通常很小的)内群,存在一个 程序,这个程序可以估算最佳解释或最适用于这一数据模型的参数。
宏观点来看,Ransac是一种思想,一种利用迭代来增加概率的方法,即:
- RANSAC是一种思想,一个求解已知模型的参数的框架。它不限定某一特定的问题,可以是计算机视觉的问题,同样也可以是统计数学,甚至可以是经济学领域的模型参数估计问题。
- RANSAC是一种迭代的方法,用来在一组包含离群的被观测数据中估算出数学模型的参数。 RANSAC 是一个非确定性算法,在某种意义上说,它会产生一个在一定概率下合理的结果,其允许使用更多次的迭代来使其概率增加。
2. Ransac基本流程和参数设置
2.1 Ransac步骤
RANSAC算法的输入:
- 1.一组观测数据(往往含有较大的噪声或无效点
- 2.一个用于解释观测数据的参数化模型
- 3.一些可信的参数
迭代过程:
- 在数据中随机选择n个点设定为内群
- 计算适合内群的模型,如线性直线模型y=ax+b
- 把其它刚才没选到的点带入刚才建立的模型中,计算是否为内群点
- 记下内群数量
- 重复以上步骤, 迭代k次
- 比较哪次计算中内群数量最多,内群最多的那次所建的模型就是我们所要求的解
注意:不同问题对应的数学模型不同,因此在计算模型参数时方法必定不同,RANSAC的作用不在于 计算模型参数。(这导致ransac的缺点在于要求数学模型已知)
2.2 Ransac参数设置
在上面的步骤中,有两个参数比较重要,需要提前确定,即:
- 一开始的时候我们要随机选择多少点(n)
- 以及要重复迭代多少次(k)
假设每个点是真正内群的概率为 w:
通常我们不知道 w 是多少, \(w^n\)是所选择的n个点都是内群的机率, \(1-w^n\)是所选择的n个点至少有一个不是内群的机率, \((1 − w^n)^k\)是表示重复 k 次都没有全部的n个点都是内群的机率, 假设算法跑 k 次以后成功的机率是p,那么
我们可以通过P反算得到抽取次数K:\(K=log(1-P)/log(1-w^n)。\)
所以如果希望成功机率高:
- 当n不变时,k越大,则p越大;
- 当w不变时,n越大,所需的k就越大。
- 通常w未知,所以n选小一点比较好。
实际设置经验
可以先设置好P和n,然后K设置为一个很大的数,然后在迭代的过程中,每次迭代完都可以计算一次w,然后对K进行动态修改。 opencv的findHomography函数中ransac就是采用的这一策略:
H = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5) # 采用Ransac方法计算单应性矩阵
参考:https://blog.csdn.net/laobai1015/article/details/51683076/
3. Ransac应用
在计算机视觉方面,Ransac最主要的应用主要包括直线拟合,平面拟合,单应性矩阵拟合等。这里简单介绍下直线拟合和透视矩阵拟合。
3.1 Ransac直线拟合
假设我们知道两个变量X与Y之间呈线性关系,Y=aX+b,我们想确定参数a与b的具体值。通过实验, 可以得到一组X与Y的测试值。虽然理论上两个未知数的方程只需要两组值即可确认,但由于系统误差的原因,任意取两点算出的a与b的值都不尽相同。通常情况下,我们可以采用最小二乘法拟合出直线方程(最小二乘法:通过计算最小均方差关于参数a、b的偏导数为零时的值)。但是最小二乘法只适合于误差较小的情况,如果测量数据中外点较多,误差很大,就需要采用Ransac算法。
在下图中分别是Ransac和最小二乘法拟合的直线,可以看出两者的差别。直接采用最小二乘法拟合直线,直线会受离群点影响,偏离中间的内群数据点,而ransac只是挑选部分数据点进行直线拟合,所以不会受离群点影响。
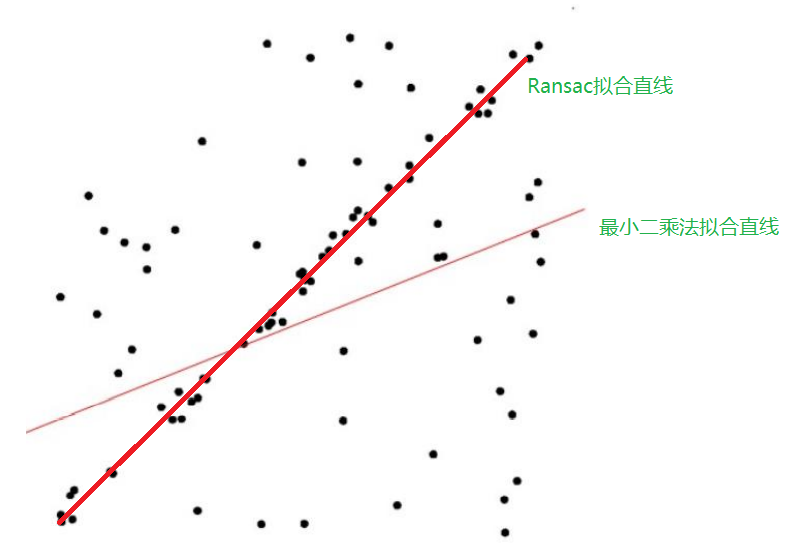
下面是一段示例代码,比较了ransac和最小二乘法拟合直线的区别:
#include<iostream>
#include<opencv2/opencv.hpp>
#include<vector>
#include<set>
using namespace std;
bool ransacFitLine(vector<cv::Point2d>& points, cv::Vec4f& bestParam, vector<cv::Point2d>& inlinerPoints, int initInlinerNums, int iter, double thresh, int EndInlinerNums){
/*
@param points: 所有的样本点.
@param bestParam: 拟合最好的直线方程
@param inlinerPoints: 拟合最好时的内点集合
@param initInlinerNums: 用来拟合直线的初始化内点个数
@param iter: 最大迭代次数
@param thresh: 阈值,用来判断某个点是否在拟合的直线上
@param EndInlinerNums: 阈值,内点个数超过阈值时停止迭代
*/
set<int> randomIndex;
vector<cv::Point2d> randomPoints;
vector<cv::Point2d> tempInliners;
int n = points.size();
double minErr=DBL_MAX;
bool flag = false;
while(iter>=0){
randomIndex.clear();
randomPoints.clear();
tempInliners.clear();
// 随机选取initInlinerNums个点,拟合直线,其他点作为测试点
for(int i=0; i<initInlinerNums; i++){
int index = rand()%n;
randomIndex.insert(index);
randomPoints.push_back(points[index]);
}
// 采用随机点拟合直线
cv::Vec4f lineParam;
cv::fitLine(randomPoints, lineParam, cv::DIST_L2, 0, 0.01, 0.01);
double linek = lineParam[1]/lineParam[0];
// 计算测试点是否也在拟合直线上, 在直线上的点当作inliner
for(int i=0; i<n; i++){
if(randomIndex.find(i)==randomIndex.end()){
double err = linek*(points[i].x - lineParam[2]) + lineParam[3] - points[i].y;
err = err*err; // 差值的平方作为误差
if (err < thresh){
tempInliners.push_back(points[i]);
}
}
}
// 当前inliner内点个数超过阈值时
if(tempInliners.size()>EndInlinerNums){
//采用所有的内点,拟合直线并计算平均误差
tempInliners.insert(tempInliners.end(), randomPoints.begin(), randomPoints.end());
cv::fitLine(randomPoints, lineParam, cv::DIST_L2, 0, 0.01, 0.01);
double linek = lineParam[1]/lineParam[0];
double sumErr = 0;
for(int i=0; i<tempInliners.size(); i++){
double err = linek*(points[i].x - lineParam[2]) + lineParam[3] - points[i].y;
sumErr += err*err; // 差值的平方作为误差
}
sumErr = sumErr/tempInliners.size(); // 误差平方和的平均值
if(minErr>sumErr){ // 记录最小的平均误差,
minErr = sumErr;
bestParam = lineParam;
inlinerPoints.assign(tempInliners.begin(), tempInliners.end());
flag = true;
}
}
iter--;
}
if(!flag) cout << "did't meet fit acceptance criteria" << endl;
return flag;
}
int main(int argc, char* argv[]){
cv::RNG rng(200);//seed为200
vector<cv::Point2d> points;
// 生成500个随机样本点
int nSamples = 500; // 生成样本数据个数
double k = 1 + rng.gaussian(1); // 0-2之间的随机斜率
cout << k << endl;
for(int i=0; i<nSamples; i++){
double x = rng.uniform(40, 600);
double y = k*x + rng.uniform(-30, 30); // 加入随机噪声
x += rng.uniform(-30, 30); // 加入随机噪声
points.push_back(cv::Point2d(x, y));
}
// 加入outlier
for(int j=0; j< 100; j++){
double x = rng.uniform(200, 600);
double y = rng.uniform(10, 300);
points.push_back(cv::Point2d(x, y));
}
cv::Mat img = cv::Mat(720, 720, CV_8UC3, cv::Scalar(255,255,255));
//绘制point
for(int i=0; i<points.size(); i++){
cv::circle(img, points[i], 3, cv::Scalar(0, 0, 0), 2);
}
// 最小二乘法
if(1){
cv::Vec4f lineParam;
fitLine(points, lineParam, cv::DIST_L2, 0.0, 0.01, 0.01);
//获取点斜式的点和斜率, y=k(x-x0) + y0
cv::Point point0;
point0.x = lineParam[2];
point0.y = lineParam[3];
double linek = lineParam[1] / lineParam[0];
//绘制最小二乘法拟合的直线
cv::Point2d point1, point2;
point1.x=10;
point1.y = linek*(point1.x-point0.x) + point0.y;
point2.x = 600;
point2.y = linek*(point2.x-point0.x) + point0.y;
cv::line(img, point1, point2, cv::Scalar(0, 255, 0), 4);
}
// ransac拟合直线
if(1){ // 为了避免命名冲突,所以放在if局部范围内
cv::Vec4f lineParam;
vector<cv::Point2d> inlinerPoints;
bool ret = ransacFitLine(points, lineParam, inlinerPoints, 50, 1000, 7e3, 300);
if(ret){
cout << ret << endl;
cout << lineParam << endl;
cout << inlinerPoints.size() << endl;
//获取点斜式的点和斜率, y=k(x-x0) + y0
cv::Point point0;
point0.x = lineParam[2];
point0.y = lineParam[3];
double linek = lineParam[1] / lineParam[0];
//绘制拟合的直线
cv::Point2d point1, point2;
point1.x=10;
point1.y = linek*(point1.x-point0.x) + point0.y;
point2.x = 600;
point2.y = linek*(point2.x-point0.x) + point0.y;
cv::line(img, point1, point2, cv::Scalar(0, 0, 255), 4);
}else{
cout << "Fitting failed, try to change parameters for ransac!!!" << endl;
}
}
cv::imshow("img", img);
cv::waitKey(0);
cv::destroyAllWindows();
return 0;
}
代码结果如下:
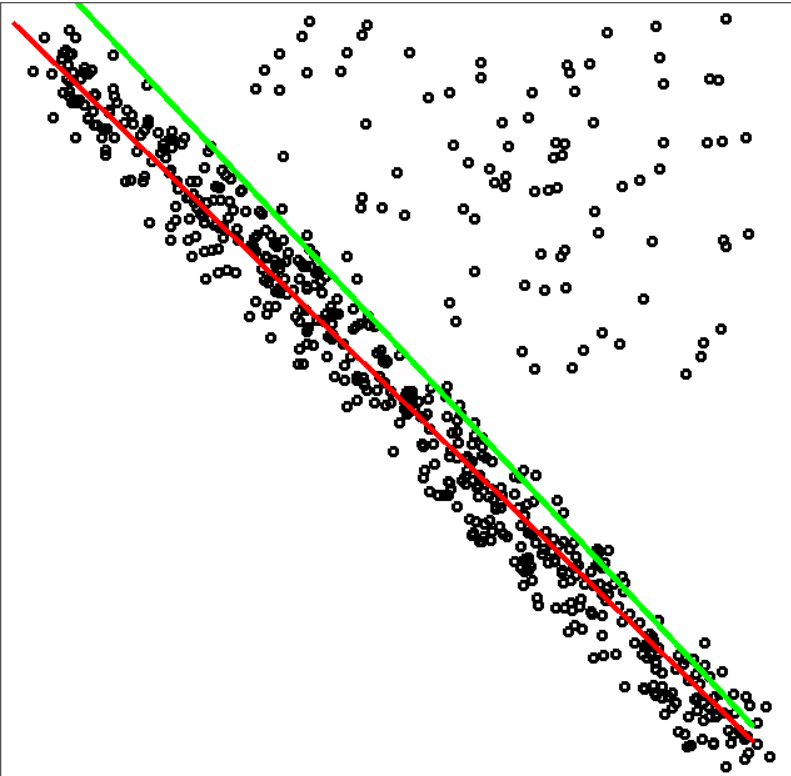
3.2 Ransac单应性矩阵拟合
关于单应矩阵理解:https://zhuanlan.zhihu.com/p/49435367
在进行图像匹配,全景拼接等时,常会用到单应性矩阵。例如在做全景拼接时,对于同一个场景,相机在不同角度拍摄了两张照片,一般先寻找两幅图片的匹配特征点,然后通过匹配特征点的对应关系计算出一个矩阵,这个矩阵就是单应性矩阵,利用这个矩阵就能将两张图片组合在一起。所以单应矩阵描述的是两组坐标点的关系,即:
上面H即为单应性矩阵,\((x_0, y_0)\)为第一幅图片上的坐标点,\((X'_0, Y'_0)\)为第二幅图片上的坐标点,两个点是一组匹配点。H一般为3x3的矩阵,形式如下:
这个矩阵有9个未知数(自由度为8),为了求解矩阵我们一般令\(a_{33}=1\), 则一组匹配点可以列如下两个方程:
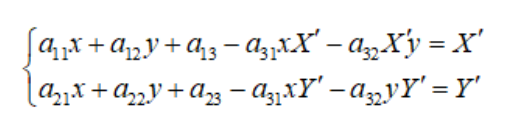
若有四组匹配点,就能列出8个方程,便能计算出单应矩阵H, 如下图所示:

opencv的getPerspectiveTransform函数就是通过四组匹配点来计算单应性矩阵(投影矩阵/透视矩阵),如下:
H = cv2.getPerspectiveTransform(src, dst) # 返回3*3的矩阵
参数:
src:原图像中的四组坐标,如 np.float32([[56,65],[368,52],[28,387],[389,390]])
dst: 转换后的对应四组坐标,如np.float32([[0,0],[300,0],[0,300],[300,300]])
如果我们只有四组匹配点,而且能够保证匹配点都是正确的,的确可以采用上述方法求解单应矩阵,但是如果我们有100组匹配点,而且有些匹配点可能是错误的,该怎么求解一个拟合最好的矩阵呢?
仔细观察上面八个方程的形式,发现是一个矩阵求解的问题:
其中,A是8x8的矩阵,H是8x1的矩阵,B也是8x1的矩阵。若有100组匹配点,则A是200x8的矩阵,B是200x1的矩阵。
联想到上面最小二乘法拟合直线的问题:\(y=wx\),那么在这里x就是矩阵A的每一行(8x1的向量),\(w\)就是矩阵H,\(y\)
就是矩阵B的每一行(1x1), 如下图所示:
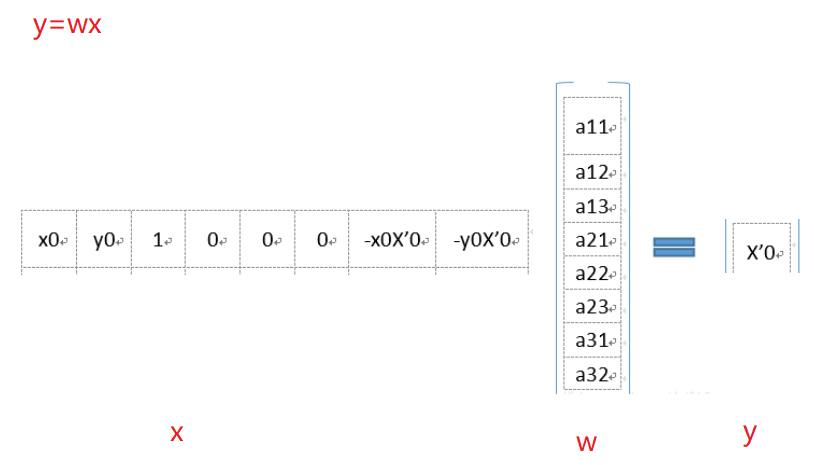
所以100组匹配点就是对应200条数据,采用最小二乘法进行拟合(不算是直线了,算平面拟合了)。
有了求解方法,另一个问题就是:100组匹配点中可能存在错误的匹配,很明显错误的匹配就是所谓的outlier了。很自然的能想到:采用ransac代替上面的最小二乘法即可。
上述就是采用Ransac拟合单应性矩阵的思想,在opencv中findHomography函数实现了上述过程,如下所示:
#findHomography(srcPoints,dstPoints,method=0,ransacReprojThreshold=3,mask=noArray(),maxIters=2000,confidence=0.995)
H = cv2.findHomography(src_pts, dst_pts, method=cv2.RANSAC, ransacReprojThreshold=5) # 生成变换矩阵
参数:
src_pts:原图像中的坐标(大于等于四组)
dst_pts: 转换后的对应坐标(大于等于四组)
method:求解单应矩阵的方法,取值如下:
0:最小二乘法
RANSAC:RANSAC拟合方法
LMEDS: Least-Median robust method
RHO:PROSAC-based robust method
ransacReprojThreshold:ransac中判断是否是内点的阈值
下面看一个全景拼接的示例,全景拼接的常规流程 如下:
-
1、针对某个场景拍摄多张/序列图像
-
2、通过匹配特征(sift匹配)计算下一张图像与上一张图像之间的匹配特征点
-
3、对匹配特征点进行筛选,剔除掉部分匹配点。采用ransanc拟合匹配点之间的单应性矩阵
-
3、利用单应性矩阵进行图像映射,将下一张图像叠加到上一张图像的坐标系中
-
4、变换后的融合/合成
![]()

下面是一个代码示例:
# coding: utf-8
import numpy as np
import cv2
left_img = cv2.imdecode(np.fromfile(r"D:\笔记\cpp\image_processing\图像拼接\left.jpg", dtype=np.uint8), 1)
left_img = cv2.resize(left_img, (600, 400))
right_img = cv2.imdecode(np.fromfile(r"D:\笔记\cpp\image_processing\图像拼接\right.jpg", dtype=np.uint8), 1)
right_img = cv2.resize(right_img, (600, 400))
left_gray = cv2.cvtColor(left_img, cv2.COLOR_BGR2GRAY)
right_gray = cv2.cvtColor(right_img, cv2.COLOR_BGR2GRAY)
hessian = 300
surf = cv2.xfeatures2d.SIFT_create(hessian) # 将Hessian Threshold设置为400,阈值越大能检测的特征就越少
kp1, des1 = surf.detectAndCompute(left_gray, None) # 查找关键点和描述符
kp2, des2 = surf.detectAndCompute(right_gray, None)
# kp1s = np.float32([kp.pt for kp in kp1])
# kp2s = np.float32([kp.pt for kp in kp2])
# 显示特征点
img_with_drawKeyPoint_left = cv2.drawKeypoints(left_gray, kp1, np.array([]), flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow("img_with_drawKeyPoint_left", img_with_drawKeyPoint_left)
img_with_drawKeyPoint_right = cv2.drawKeypoints(right_gray, kp2, np.array([]), flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow("img_with_drawKeyPoint_right", img_with_drawKeyPoint_right)
'''
BFMatcher简称暴力匹配,意思就是尝试所有可能匹配,实现最佳匹配。
FlannBasedMatcher简称最近邻近似匹配。
是一种近似匹配方法,并不追求完美!,因此速度更快。
可以调整FlannBasedMatcher参数改变匹配精度或改变算法速度。
参考:https://blog.csdn.net/claroja/article/details/83411108
'''
FLANN_INDEX_KDTREE = 0 # 建立FLANN匹配器的参数
indexParams = dict(algorithm=FLANN_INDEX_KDTREE, trees=5) # 配置索引,密度树的数量为5
searchParams = dict(checks=50) # 指定递归次数
# FlannBasedMatcher:是目前最快的特征匹配算法(最近邻搜索)
flann = cv2.FlannBasedMatcher(indexParams, searchParams) # 建立匹配器
# 参考https://docs.opencv.org/master/db/d39/classcv_1_1DescriptorMatcher.html#a378f35c9b1a5dfa4022839a45cdf0e89
'''
int queryIdx –>是测试图像的特征点描述符(descriptor)的下标,同时也是描述符对应特征点(keypoint)的下标。
int trainIdx –> 是样本图像的特征点描述符的下标,同样也是相应的特征点的下标。
int imgIdx –>当样本是多张图像的话有用。
float distance –>代表这一对匹配的特征点描述符(本质是向量)的欧氏距离,数值越小也就说明两个特征点越相像。
'''
matches = flann.knnMatch(des1, des2, k=2) # 得出匹配的关键点
good = []
# 提取优秀的特征点
for m, n in matches:
if m.distance < 0.7 * n.distance: # 如果第一个邻近距离比第二个邻近距离的0.7倍小,则保留
good.append(m)
src_pts = np.array([kp1[m.queryIdx].pt for m in good]) # 查询图像的特征描述子索引
dst_pts = np.array([kp2[m.trainIdx].pt for m in good]) # 训练(模板)图像的特征描述子索引
# findHomography参考https://docs.opencv.org/master/d9/d0c/group__calib3d.html#ga4abc2ece9fab9398f2e560d53c8c9780
# 单应矩阵:https://www.cnblogs.com/wangguchangqing/p/8287585.html
H = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5) # 生成变换矩阵
h1, w1 = left_gray.shape[:2]
h2, w2 = right_gray.shape[:2]
shift = np.array([[1.0, 0, w1], [0, 1.0, 0], [0, 0, 1.0]])
# 点积
M = np.dot(shift, H[0]) # 获取左边图像到右边图像的投影映射关系, 向右移动w1?
dst = cv2.warpPerspective(left_img, M, (w1+w2, max(h1, h2))) # 透视变换,新图像可容纳完整的两幅图
cv2.imshow('left_img', dst) # 显示,第一幅图已在标准位置
dst[0:h2, w1:w1+w2] = right_img # 将第二幅图放在右侧
# cv2.imwrite('tiled.jpg',dst_corners)
cv2.imshow('total_img', dst)
cv2.imshow('leftgray', left_img)
cv2.imshow('rightgray', right_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
效果如下:

参考:
https://blog.csdn.net/hzwwpgmwy/article/details/83578694
https://zhuanlan.zhihu.com/p/82793501
4 Ransac优缺点
优点:
它能鲁棒的估计模型参数。例如,它能从包含大量局外点的数据集中估计出高精度的参数。
缺点:
- 它计算参数的迭代次数没有上限;如果设置迭代次数的上限,得到的结果可能不是最优的结果,甚至可能得到错误的结果。
- RANSAC只有一定的概率得到可信的模型,概率与迭代次数成正比。
- 它要求设置跟问题相关的阀值。
- RANSAC只能从特定的数据集中估计出一个模型,如果存在两个(或多个)模型,RANSAC不能找到别的模型。
- 要求数学模型已知
参考:https://zhuanlan.zhihu.com/p/36301702/
https://blog.csdn.net/leonardohaig/article/details/104570965

 浙公网安备 33010602011771号
浙公网安备 33010602011771号