
文本检测网络Psenet学习(三)
现有的文本检测方法主要有两大类,一种是基于回归框的检测方法(基于物体检测的方法),如CTPN,EAST,这类方法很难检测任意形状的文本(曲线文本), 一种是基于像素的分割检测器(基于实例分割的方法),这类方法很难将彼此非常接近的文本实例分开。Psenet文本检测方法是基于分割的方法,在2019年的论文Shape Robust Text Detection with Progressive Scale Expansion Network 中提出,优化了近距离文本实例的分离。
对于Psenet的学习,主要在于四方面:网络结构的设计,kernel的生成,渐进尺度扩展算法(progressive scale expansion),loss函数
1. 网络结构的设计
Psenet网络采用了resnet+fpn的架构,通过resnet提取特征,取不同层的特征送入fpn进行特征融合,其结构如下图所示:

上图中给出了训练过程中网络数据流,总结如下:
1. 1*3*640*640的图片输入网络,经过Resnet网络,将layer1,layer2,layer3,layer4的特征图p1(1*256*160*160), p2(1*512*80*80), p3(1*1024*40*40), p4(1*2048*20*20)送入fpn
2. 以此对应p1, p2, p3, p4, fpn网络输出特征c1(1*256*160*160), c2(1*256*80*80), c3(1*256*40*40), c4(1*256*20*20)
3. c2, c3, c4分别上采样2,4,8倍后和c1进行concat得到特征1*1024*160*160,再经过两个卷积输出1*7*160*160,上采样4倍得到网络最终的输出1*7*640*640。
4.网络最后输出了7个640*640的预测图(map),分别表示预测的text_predict,和6个kernel_predict
另外,上述采用resnet50的典型结构如下:

2. kernel的产生
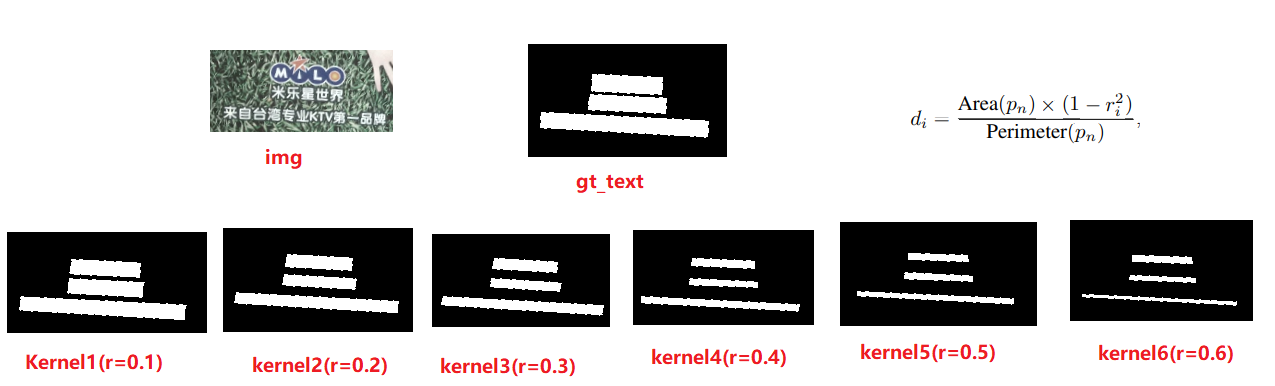
上面网络结构中提到模型最后输出7个640*640的预测图, 分别是预测的text,和6个kernel,因此在训练时也需要通过标注数据产生7个640*640的map供网络学习,即text_gt和6个kernel_gt。其中text_gt就是一张二值图,白色部分表示img中含有文字的区域,黑色部分表示背景区域,kernel_gt就是在text_gt的基础上,将白色区域按一定的比例缩小。如下图所示,根据r计算出d,表示该kernel的白色区域边缘部分相对于text_gt的白色区域向内部移动了d个像素。
3. 渐进尺度扩展算法(progressive scale expansion)
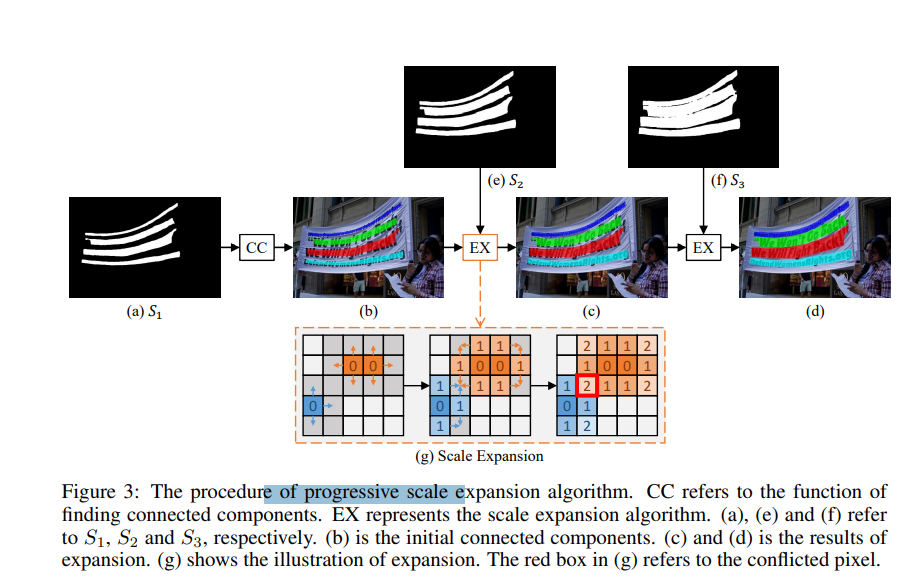
在进行推理时,需要从网络输出的6个kernel中得到需要的box,作者采用了pse(progressive scale exoansion)算法。假设有kernel1,kernel2, kernel3, kernel4, kernel5, kernel6,先从文字区域最小的kernel6开始,遍历其白色区域的像素点,采用广度优先法向四周扩展,依次合并kernel2, kernel3, kernel4, kernel5, kernel6, 最后合并得到一个kernel,整个合并算法看代码比较好理解。取合并后kernel白色区域的矩形框或轮廓线即得到文字检测框。论文中示意图如下:
参考python代码如下:


import numpy as np import cv2 # import Queue from queue import Queue def pse(kernals, min_area): kernal_num = len(kernals) pred = np.zeros(kernals[0].shape, dtype='int32') label_num, label = cv2.connectedComponents(kernals[kernal_num - 1], connectivity=4) for label_idx in range(1, label_num): if np.sum(label == label_idx) < min_area: label[label == label_idx] = 0 queue = Queue.Queue(maxsize = 0) next_queue = Queue.Queue(maxsize = 0) points = np.array(np.where(label > 0)).transpose((1, 0)) for point_idx in range(points.shape[0]): x, y = points[point_idx, 0], points[point_idx, 1] l = label[x, y] queue.put((x, y, l)) pred[x, y] = l dx = [-1, 1, 0, 0] dy = [0, 0, -1, 1] for kernal_idx in range(kernal_num - 2, -1, -1): kernal = kernals[kernal_idx].copy() while not queue.empty(): (x, y, l) = queue.get() is_edge = True for j in range(4): tmpx = x + dx[j] tmpy = y + dy[j] if tmpx < 0 or tmpx >= kernal.shape[0] or tmpy < 0 or tmpy >= kernal.shape[1]: continue if kernal[tmpx, tmpy] == 0 or pred[tmpx, tmpy] > 0: continue queue.put((tmpx, tmpy, l)) pred[tmpx, tmpy] = l is_edge = False if is_edge: next_queue.put((x, y, l)) # kernal[pred > 0] = 0 queue, next_queue = next_queue, queue # points = np.array(np.where(pred > 0)).transpose((1, 0)) # for point_idx in range(points.shape[0]): # x, y = points[point_idx, 0], points[point_idx, 1] # l = pred[x, y] # queue.put((x, y, l)) return pred
4. loss函数理解
psenet的loss包括两部分,gt_text和kernel的loss,都采用dice loss计算损失值。总的loss计算如公司如下,权重系数一般取λ=0.7
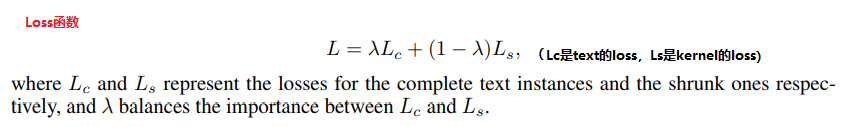
dice loss的计算公式如下,参见代码比较好理解
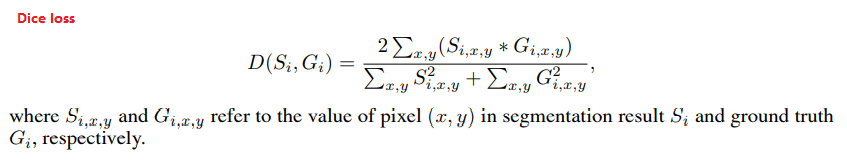
dice loss 参考代码:
def dice_loss(input, target, mask): #input为预测的map #target为标注的map input = torch.sigmoid(input) input = input.contiguous().view(input.size()[0], -1) target = target.contiguous().view(target.size()[0], -1) mask = mask.contiguous().view(mask.size()[0], -1) input = input * mask target = target * mask a = torch.sum(input * target, 1) b = torch.sum(input * input, 1) + 0.001 c = torch.sum(target * target, 1) + 0.001 d = (2 * a) / (b + c) dice_loss = torch.mean(d) return 1 - dice_loss
参考:
https://github.com/whai362/PSENet
https://github.com/WenmuZhou/PSENet.pytorch

