
文字识别网络学习—CRNN+CTC
OCR(Optical Character Recognition)任务主要是识别出图片中的文字,目前深度学习的方法采用两步来解决这个问题,一是文字检测网络定位文字位置,二是文字识别网络识别出文字。
关于OCR的综述参考:http://xiaofengshi.com/2019/01/05/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0-OCR_Overview/
CRNN+CTC的文字识别网络是在2015年的论文An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition(2015) 中提出,主要用于序列文本的识别。CRNN的整体流程如下图所示,图片依次经过CNN卷积层,RNN循环层,最后经解码翻译处理得到最后的识别文本。
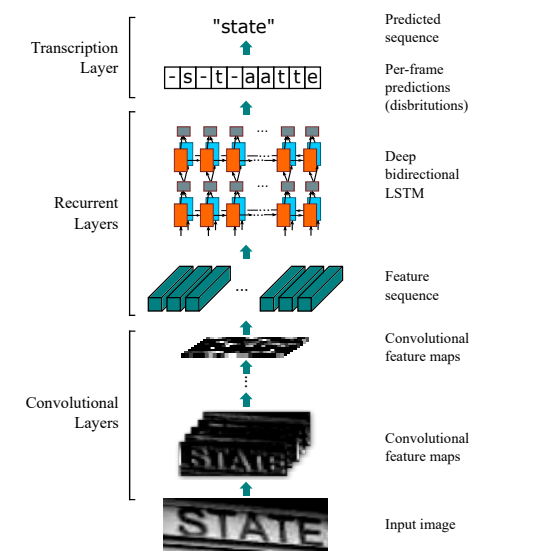
对于CRNN文字识别网络的理解主要在于三方面:网络结构,CTC损失函数,数据预处理。CRNN参考代码地址:https://github.com/bgshih/crnn, https://github.com/meijieru/crnn.pytorch
1. 网络结构
CRNN的网络结构比较简单,包括VGG11和RNN两部分。采用VGG11进行特征提取,随后采用双层的BiLSTM提取序列信息,其网络结构如图所示:
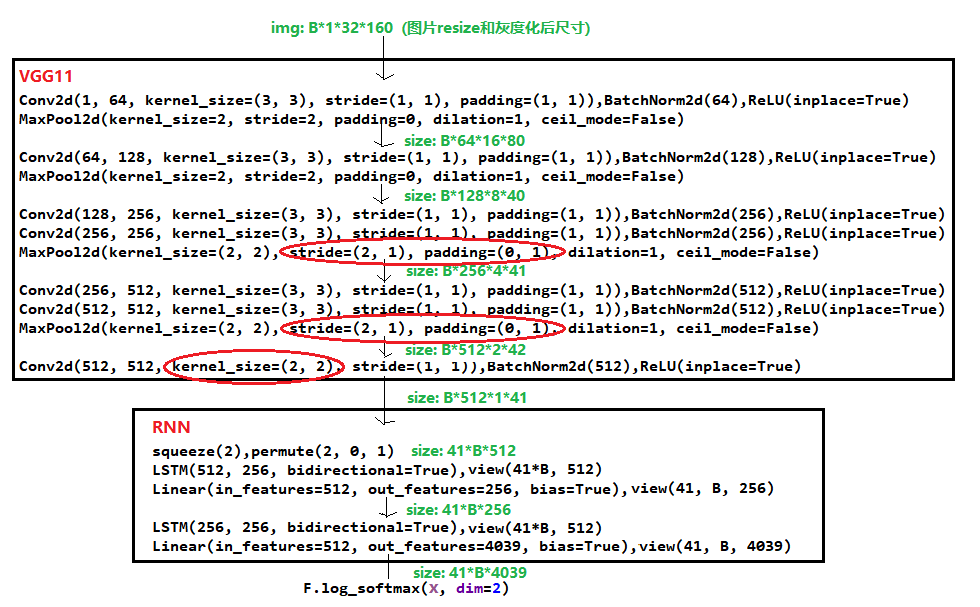
训练时模型的计算流程如下:
1. 经过灰度化和resize后图片的尺寸为(B, 1, 32, 160),图片经过VGG11卷积层得到feature尺寸为(B, 512, 1, 41)
2. feature经过RNN循环层后网络输出尺寸为(41, B, 4039)。(4039表示字典里共有4038个字符,还有一个字符"_"表示空格)
3. 尺寸为(41, B, 4039)的输出经过log_softmax后,通过CTC计算loss
2.CTC损失函数
CTC(Connectionist Temporal Classification)是在2006年的论文Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks中提出,引入了空白符号,解决了损失计算时,文字标注和网络输出之间的对齐问题。其原理比较复杂,需要专研下,参考:CTC原理理解(转载)
3.数据预处理
由于CRNN对于序列行文本效果比较好,所以对于输入的图片除了进行resize和灰度化外,还有两点要注意。
一是旋转角度过大的序列文本,需要进行一定的旋转,参考下面代码


from scipy.ndimage import filters, interpolation from numpy import amin, amax def estimate_skew_angle(raw): """ 估计图像文字角度 因为文字是水平排版,那么此位置图像的行与行之间像素值的方差应该是最大。 原理大概是这样,先对图像进行二值化处理,然后计算图像每行的均值向量,得到该向量的方差。如果图像文字不存在文字倾斜(假设所有文字朝向一致),那么对应的方差应该是最大,找到方差最大对应的角度,就是文字的倾斜角度。 本项目中,只取了-15到15度,主要是计算速度的影响,如果不考虑性能,可以计算得更准备。 """ def resize_im(im, scale, max_scale=None): f = float(scale) / min(im.shape[0], im.shape[1]) if max_scale != None and f * max(im.shape[0], im.shape[1]) > max_scale: f = float(max_scale) / max(im.shape[0], im.shape[1]) return cv2.resize(im, (0, 0), fx=f, fy=f) raw = resize_im(raw, scale=600, max_scale=900) image = raw - amin(raw) image = image / amax(image) m = interpolation.zoom(image, 0.5) m = filters.percentile_filter(m, 80, size=(20, 2)) m = filters.percentile_filter(m, 80, size=(2, 20)) m = interpolation.zoom(m, 1.0 / 0.5) w, h = min(image.shape[1], m.shape[1]), min(image.shape[0], m.shape[0]) flat = np.clip(image[:h, :w] - m[:h, :w] + 1, 0, 1) d0, d1 = flat.shape o0, o1 = int(0.1 * d0), int(0.1 * d1) flat = amax(flat) - flat flat -= amin(flat) est = flat[o0:d0 - o0, o1:d1 - o1] angles = range(-15, 15) estimates = [] for a in angles: roest = interpolation.rotate(est, a, order=0, mode='constant') v = np.mean(roest, axis=1) v = np.var(v) estimates.append((v, a)) _, a = max(estimates) return a if __name__ == "__main__": import os src = r"F:\temp" for file in os.listdir(src): if file.endswith(".jpg"): img_path = os.path.join(src, file) # img = cv2.imread(img_path, 0) img = cv2.imdecode(np.fromfile(img_path, dtype=np.uint8), flags=0) h, w = img.shape angle = estimate_skew_angle(img) print(file, angle) m = cv2.getRotationMatrix2D((int(w / 2), int(h / 2)), angle, 1) d = int(np.sqrt(h * h + w * w)) img2 = cv2.warpAffine(img, m, (w, h)) cv2.imshow("img2", img2) cv2.waitKey(0) cv2.destroyAllWindows()
二是对于长文本需要进行切割成小段,识别后再拼接,如上面网络输出序列为41*B*4039,表示支持的最长文本为41个字符
参考:https://zhuanlan.zhihu.com/p/43534801

 浙公网安备 33010602011771号
浙公网安备 33010602011771号