分类和目标检测的性能评价指标
对于深度学习的网络模型,希望其速度快,内存小,精度高。因此需要量化指标来评价这些性能,常用的指标有:mAP(平均准确度均值,精度指标), FPS(每秒处理的图片数量或每张图片处理需要时间,同样硬件条件下的速度指标) , 模型参数大小(内存大小指标)。
1.mAP (mean Avearage Precision)
mAP指的是各类别的AP平均值,而AP指PR曲线的面积(precision和Recall关系曲线),因此得先了解下precision(精确率)和recall(召回率),以及相关的accuracy(准确度), F-measurement(F值), ROC曲线等。
recall和precision是二分类问题中常用的评价指标,通常以关注的类为正类,其他类为负类,分类器的结果在测试数据上有4种情况:


Precision和Recall计算举例:
假设我们在数据集上训练了一个识别猫咪的模型,测试集包含100个样本,其中猫咪60张,另外40张为小狗。测试结果显示为猫咪的一共有52张图片,其中确实为猫咪的共50张,也就是有10张猫咪没有被模型检测出来,而且在检测结果中有2张为误检。因为猫咪更可爱,我们更关注猫咪的检测情况,所以这里将猫咪认为是正类:所以TP=50,TN=38,FN=10,FP=2,P=50/52,R=50/60,acc=(50+38)/(50+38+10+2)
为什么引入Precision和Recall:
recall和precision是模型性能两个不同维度的度量:在图像分类任务中,虽然很多时候考察的是accuracy,比如ImageNet的评价标准。但具体到单个类别,如果recall比较高,但precision较低,比如大部分的汽车都被识别出来了,但把很多卡车也误识别为了汽车,这时候对应一个原因。如果recall较低,precision较高,比如检测出的飞机结果很准确,但是有很多的飞机没有被识别出来,这时候又有一个原因.
recall度量的是「查全率」,所有的正样本是不是都被检测出来了。比如在肿瘤预测场景中,要求模型有更高的recall,不能放过每一个肿瘤。
precision度量的是「查准率」,在所有检测出的正样本中是不是实际都为正样本。比如在垃圾邮件判断等场景中,要求有更高的precision,确保放到回收站的都是垃圾邮件。
F-score/F-measurement:
上面分析发现,精确率和召回率反映了分类器性能的两个方面,单一依靠某个指标并不能较为全面地评价一个分类器的性能。一般情况下,精确率越高,召回率越低;反之,召回率越高,精确率越低。为了平衡精确率和召回率的影响,较为全面地评价一个分类器,引入了F-score这个综合指标。
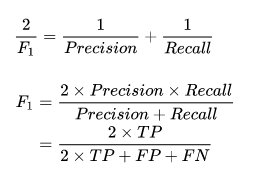
F-score是精确率和召回率的调和均值,计算公式如下:

其中, (
)的取值反映了精确率和召回率在性能评估中的相对重要性具体,通常情况下,取值为1。描述如下:
(1)当 时,就是常用的
值,表明精确率和召回率一样重要,计算公式如下:
 (2)当
(2)当 时,
表明召回率的权重比精确率高;
(3)当 时,
表明精确率的权重比召回率高。
Accuracy:也是对模型预测准确的整体评估, 通常用到的准确率计算公式如下:
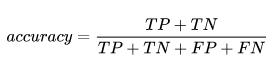
AP/PR曲线:
即recall为横坐标,precision为纵坐标,绘制不同recall下的precison值,可以得到一条Precisoin和recall的曲线,AP就是这个P-R曲线下的面积,定义:
举例子比较好理解,
分类问题:
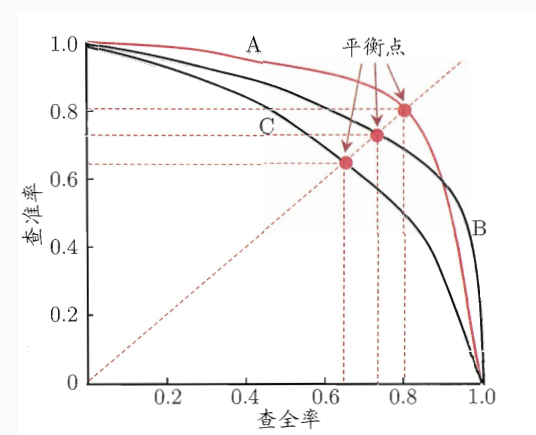
假设有100张图片,要分成猫,狗,鸡三类,100张图片对应100个真实值,模型分类后我们会得到对应的100个预测值。这里我们可以只取前10个预测值出来,计算10个值中猫预测出几张,预测对几张,从而能计算出猫的precison和recall;接着我们可以取前20个预测值同样能计算出一组猫的precison和recall;这样一直增加到取100个预测值,就能得到猫的10组(recall, precision)值来绘制曲线。这里要注意的是:随着选取预测值增加,recall肯定是增加或不变的(选取的预测值越多,预测出来的猫越多,即查全率肯定是在增加或不变),若增加选取预测值后,recall不变,一个recall会对应两个precison值,一般选取较大的那个precision值。 如果我们每次只增加一个预测值,就会得到大约100对(recall, precisoin)值,然后就能绘制猫的PR曲线,计算出其下方的面积,就是猫对应的AP值(Average Precision)。 如果我们接着对狗和鸡也采用相同方法绘制出PR曲线, 就能得到猫,狗, 鸡三个AP值,取平均值即得到了整个模型最终的mAP(mean Average Precsion)。如下图中A, B, C三条PR曲线:
目标检测:
在目标检测中还有一个IoU(交并比、Intersection over Union、IoU), 通过比较检测bbox和真实bbox的IoU来判断是否属于TP(True Positive
),例如设置IoU阈值为0.7,则IoU大于0.7的则判定为TP,否则为FP。因此当我们设置不同的IoU阈值时,也会得到不同的mAP值,再将这些mAP值进行平均就会得到mmAP,一般不做特别说明mmAP即指通常意义上的mAP。
因此目标检测mAP计算方法如下:给定一组IOU阈值,在每个IOU阈值下面,求所有类别的AP,并将其平均起来,作为这个IOU阈值下的检测性能,称为mAP(比如mAP@0.5就表示IOU阈值为0.5时的mAP);最后,将所有IOU阈值下的mAP进行平均,就得到了最终的性能评价指标:mmAP。
ROC曲线与AUC:
除了绘制PR曲线,计算AP,有时候也会绘制ROC曲线,计算AUC。(参考文章)
ROC(receiveroperating characteristic):接受者操作特征,指的是TPR和FPR间的关系,纵坐标为TPR, 横坐标为FPR, 计算公式如下:
AUC(area under curve):表示ROC曲线下的面积。


参考:https://zhuanlan.zhihu.com/p/43068926
https://zhuanlan.zhihu.com/p/55575423
https://zhuanlan.zhihu.com/p/70306015
https://zhuanlan.zhihu.com/p/30953081
2. FLOPs (浮点运算数)
FLOPs:(Floating Point Operations) s小写,指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。(模型) 在论文中常用GFLOPs(1 GFLOPs = 10^9 FLOPs)
FLOPS: (Floating Point operations per second), S大写, 指每秒浮点运算的次数,可以理解为运算的速度,是衡量硬件性能的一个指标。
一般计算FLOPs来衡量模型的复杂度,FLOPs越小时,表示模型所需计算量越小,运行起来时速度更快。对于卷积和全连接运算,其公式如下:
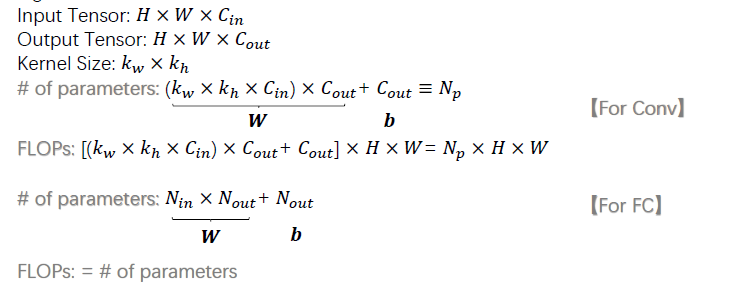
另外,MAC(memory access cost, 内存访问成本)也会被用来衡量模型的运行速度, 一般MAC=2*FLOPs (一次加法运算和一次乘法算法):

有一个基于pytorch的torchstat包,可以计算模型的FLOPs数,参数大小等指标,示例代码如下:
from torchstat import stat import torchvision.models as models model = model.alexnet() stat(model, (3, 224, 224))
3. 模型参数大小
常用模型的参数所占大小来衡量模型所需内存大小,一般可分为Vgg, GoogleNet, Resnet等参数量大的模型,和squeezeNet,mobilerNet,shuffleNet等参数量小的轻量级模型,常用一些模型的参数量和FLOPs如下:

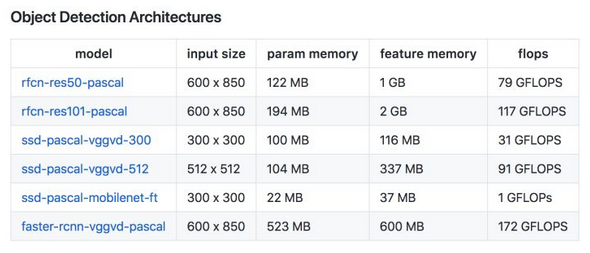
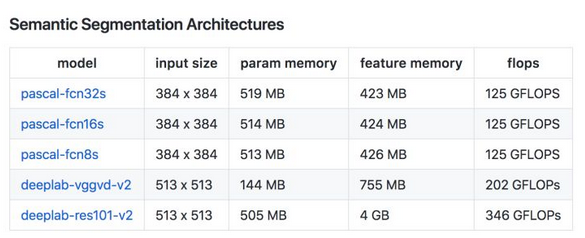
最后还有一张模型运算量(FLOPs), 参数大小(圆圈的面积),表现效果(Accuracy)的关系图如下:

参考:https://www.zhihu.com/question/65305385
https://zhuanlan.zhihu.com/p/67009992

 浙公网安备 33010602011771号
浙公网安备 33010602011771号