
pytorch基础学习(一)
在炼丹师的路上越走越远,开始入手pytorch框架的学习,越炼越熟吧。。。
1. 张量的创建和操作
创建为初始化矩阵,并初始化
a = torch.empty(5, 3) #创建一个5*3的未初始化矩阵 nn.init.zeros_(a) #初始化a为0 nn.init.constant_(a, 3) # 初始化a为3 nn.init.uniform_(a) #初始化为uniform分布
随机数矩阵
torch.rand(5, 3) # 5*3 , [0, 1)的随机数
torch.rand_like(m) #创建和m的size一样的随机数矩阵 torch.rand(3, 3) # 5*3 , mean=0, variance=1,的正态分布 torch.randint(1, 10, (3,3)) #3*3的整数矩阵(1-10之间)
tensor类型和形状
a = torch.Tensor([1, 2, 3]) #通过列表创建Tensor
a = torch.eye(3,4) #对角矩形
a = torch.ones(3,4)
b = torch.ones_like(a) #创建和a一样size a = torch.zeros(5, 3, dtype = torch.long) a.dtype #查看数据类型 32位浮点型:torch.Float (默认的就是这种类型, float32) 64位整型:torch.Long (int64 ) 32位整型:torch.Int (int32) 16位整型:torch.Short (int16) 64位浮点型:torch.Double (float64) a.size() h, w = torch.Size([5, 3]) #5*3维 ,h=5, w=3 a.view(3, 5) #将a进行reshape成3*5的矩阵 a.view(-1, 15) # -1表示自动计算, 即转变为1*15
tensor和numpy(array)的相互转换
b = a.numpy() #Tensor转numpy c = np.ones((3,3)) d = torch.from_numpy(c) #numpy 转tensor
2. 张量的操作
索引: 支持numpy的常用索引和切片操作
加法:和numpy类似的广播原则
索引操作 y = torch.rand(5,3) y[1:, 2] 切片和索引 y[y>0.5] 花式索引 加法操作(和numpy一样的广播原则) result = x+y reslut = torch.add(x, y) y.add_(x) #直接对y的值进行修改, (以_结尾的方法会直接在原地修改变量, 如x.copy_(y), x.t_()会修改x.) result = torch.empty(5,3) torch.add(x, y, out=result) #这里的result必须先定义 对于一个元素的张量,可以直接通过x.item()拿到元素值 x = torch.ones(3,4) y = torch.sum(x) print(y.item(0)) #得到整数12.0
cuda Tensor: pytorch 支持Gpu操作,可以在Gpu上创建tensor,通过to()方法可以在cpu和Gpu上间转换tensor
if torch.cuda.is_available(): device = torch.device("cuda") y = torch.ones_like(x, device=device) #直接在Gpu上创建tensor x = x.to(device) #从cpu上转移到gpu z = x+y print(z.to("cpu", torch.double)) #转回到cpu,并改变数据类型
3. 自动求导(Autograd)
在pytorch搭建的神经网络中,Tensor 和Function为最主要的两个类,一起组成了一个无环图。 在前向传播时,Function操作tensor的值,而进行反向传播时,需要计算function的导数来更新参数tensor, pytorch为我们自动实现了求导。每一个tensor都有一个requires_grad属性,若tensor.requires_grad=True, 则无环图会记录对该tensor的所有操作,当进行backward时,pytorch就会自动计算其导数值,并保存在tensor的grad属性中。
x = torch.ones(2, 2, requires_grad=True) #设置requires_grad=True, backward时会计算导数 y = x+2 属性值 y.requirs_grad 是否autograd, 会自动继承x的requires_grad y.grad 导数或梯度值 y.grad_fn 对x的操作function,grad_fn=<AddBackward0> tensor.detach() 将tensor从计算历史(无环图)中脱离出来? with torch.no_grad(): 从计算历史(无环图)中脱离, backward时不求导 with torch.set_grad_enabled(phase == 'train'): (phase == 'train')为True时求导 tensor.backward() #反向传播, 计算梯度,如果tensor只包含一个数时,backward不需要参数, 否则需要指明参数
backward:
#out为标量,所以backward时不带参数 x = torch.ones(2, 2, requires_grad=True) y = x+2 z = y*y*3 out = z.mean() out.backward() print(x.grad) #tensor([[4.5000, 4.5000],[4.5000, 4.5000]]) print(y.grad) #None
backward计算过程如下:

#y不为为标量,backward时需要带参数 x = torch.ones(2, 2, requires_grad=True) y = 2*x+2 y.backward(torch.tensor([[1,1],[1,1]], dtype=torch.float)) #可以理解为tensor([1, 1, 1, 1]) * dy/dx print(x.grad) # tensor([[2.,2.],[2.,2.]]) #y不为为标量,backward时需要带参数 x = torch.ones(2, 2, requires_grad=True) y = 2*x+2 y.backward(torch.tensor([[1,0.1],[1,0.1]], dtype=torch.float)) #可以理解为tensor([1, 0.1, 1, 0.1]) * dy/dx print(x.grad) # tensor([[2.0000,0.2000],[2.0000,0.2000]])
4. 神经网络(Neutral Networks)
训练神经网络的典型步骤如下:
定义神经网络(权重参数)
在数据集上进行迭代
前向传播,神经网络逐层计算输入的数据
计算loss(神经网络的计算值和正确值的距离)
计算梯度,反向传递到神经网络中,更新神经网络的权重(weight = weight - learning_rate * gradient)
4.1 定义神经网络
定义一个神经网络,需要继承torch.nn.Module, 并实现初始化方法和前向传播。下面代码为AlexNet的实现(通过三种方式定义网络结构):


#coding:utf-8 #pytorch implementation of AlexNet import torch.nn as nn import torch.nn.functional as F import torch class AlexNet(nn.Module): def __init__(self): # image size 227*227 super(AlexNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2,2)), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False), # when ceil_mode is False, floor will be used to calculate the shape, else ceil nn.Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False), nn.Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), nn.ReLU(inplace=True), nn.Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) # self.avgpool = nn.AdaptiveAvgPool2d(output_size=(6,6)) #使输出的形状变成6*6 self.classifier=nn.Sequential( nn.Dropout(p=0.5), nn.Linear(in_features=9216, out_features=4096, bias=True), nn.ReLU(inplace=True), nn.Dropout(p=0.5), nn.Linear(in_features=4096, out_features=4096, bias=True), nn.ReLU(inplace=True), nn.Linear(in_features=4096, out_features=1000, bias=True) ) def forward(self, x): x = self.features(x) x = x.view(-1, 256*6*6) x = self.classifier(x) return x class AlexNet1(nn.Module): def __init__(self): super(AlexNet1, self).__init__() self.conv1 = nn.Sequential( nn.Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2)), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False), ) self.conv2 = nn.Sequential( nn.Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False), ) self.conv3 = nn.Sequential( nn.Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), nn.ReLU(inplace=True), ) self.conv4 = nn.Sequential( nn.Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), nn.ReLU(inplace=True), ) self.conv5 = nn.Sequential( nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) self.classifier=nn.Sequential( nn.Dropout(p=0.5), nn.Linear(in_features=9216, out_features=4096, bias=True), nn.ReLU(inplace=True), nn.Dropout(p=0.5), nn.Linear(in_features=4096, out_features=4096, bias=True), nn.ReLU(inplace=True), nn.Linear(in_features=4096, out_features=1000, bias=True) ) def forward(self, x): x = self.conv1(x) x = self.conv2(x) x = self.conv3(x) x = self.conv4(x) x = self.conv5(x) x = x.view(-1, 256*6*6) x = self.classifier(x) return x class AlexNet2(nn.Module): def __init__(self): super(AlexNet2, self).__init__() self.conv1 = nn.Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2,2)) self.relu1 = nn.ReLU(inplace=True) self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) # when ceil_mode is False, floor will be used to calculate the shape, else ceil self.conv2 = nn.Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) self.relu2 = nn.ReLU(inplace=True) self.pool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) self.conv3 = nn.Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) self.relu3 = nn.ReLU(inplace=True) self.conv4 = nn.Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) self.relu4 = nn.ReLU(inplace=True) self.conv5 = nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) self.relu5 = nn.ReLU(inplace=True) self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) self.dropout = nn.Dropout(p=0.5) self.linear1 = nn.Linear(in_features=9216, out_features=4096, bias=True) self.relu6 = nn.ReLU(inplace=True) self.linear2 = nn.Linear(in_features=4096, out_features=4096, bias=True) self.relu7 = nn.ReLU(inplace=True) self.linear3 = nn.Linear(in_features=4096, out_features=1000, bias=True) def forward(self, x): x = self.pool1(self.relu1(self.conv1(x))) x = self.pool2(self.relu2(self.conv2(x))) x = self.relu3(self.conv3(x)) x = self.relu4(self.conv4(x)) x = self.pool5(self.relu5(self.conv5(x))) x = x.view(-1, 256*6*6) x = self.dropout(x) x = self.dropout(self.relu6(self.linear1(x))) x = self.relu7(self.linear2(x)) x = self.linear3(x) return x if __name__=="__main__": # net = AlexNet() # net = AlexNet1() net = AlexNet2() input = torch.randn(1,3,227,227) #torch中net输入为四维的: batch_size*channel*W*H output = net(input) print(output)
4.2 定义loss函数
pytorch中常用的loss函数有:
nn.L1Loss()
nn.L1Loss(): 取预测值和真实值差的绝对值,最后平均数 x = torch.tensor([[1,1],[2,2]], dtype=torch.float) #计算loss时需要float类型 y = torch.tensor([[3,3],[4,4]], dtype=torch.float) criterion = nn.L1Loss() loss = criterion(x, y) #(|3-1|+|3-1|+|4-2|+|4-2|)/4=2.0 print(loss.item()) # 2.0
nn.SmoothL1Loss(size_average=None, reduce=True,reduction='mean')
#reduce为False时, 返回向量, 返回整个bacth的每一个loss
# reduce 默认为True, 返回标量, size_average为True时返回batch_loss的平均值, 为False时返回batch_loss的和(size_average废弃,由reduction取代)
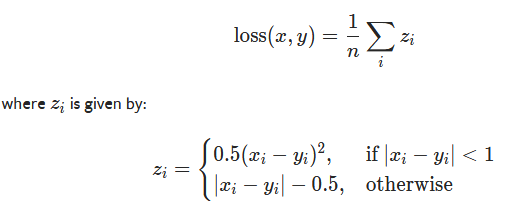
nn.SmoothL1Loss(): 在(-1, 1)范围内是平方loss(L2 loss), 其他范围内是L1 loss x = torch.tensor([[1,1],[2,2]], dtype=torch.float) #计算loss时需要float类型 y = torch.tensor([[1.5,1.5],[4,4]], dtype=torch.float) criterion = nn.SmoothL1Loss() loss = criterion(x, y) #(((1.5-1)**2)/2+((1.5-1)**2)/2+|4-2|-0.5+|4-2|-0.5)/4=2.0 print(loss.item()) # 0.8125
nn.MSELoss()

nn.MSELoss(): 平方loss(L2 loss), 最后平均数 x = torch.tensor([[1,1],[2,2]], dtype=torch.float) #计算loss时需要float类型 y = torch.tensor([[3,3],[4,4]], dtype=torch.float) criterion = nn.MSELoss() loss = criterion(x, y) #((3-1)**2+(3-1)**2+(4-2)**2+4-2)**2)/4=4.0 print(loss.item()) # 4
nn.NLLLoss() : 负对数似然损失函数(Negative Log Likelihood)
和CrossEntropyLoss()的唯一区别是,不会对输入值进行softmax计算。(因此model计算输出时,最后一层需要加上LogSoftmax)
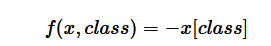
(假如x=[1, 2, 3], class=0; 则f=x[0]=1)
nn.NLLLoss() : 负对数似然损失函数(Negative Log Likelihood) input = torch.randn(3, 5, requires_grad=True) target = torch.empty(3, dtype=torch.long).random_(5) #必须是torch.long类型 criterion = nn.NLLLoss() loss = criterion(nn.LogSoftmax(dim=1)(input), target) print(loss.item())
nn.CrossEntropyLoss() 交叉熵函数
nn.LogSoftmax()和nn.NLLLoss()结合体:会对输入值使用softmax,再进行计算(因此model计算输出时不需要进行softmax)
(参考: https://www.cnblogs.com/marsggbo/p/10401215.html)
loss = nn.CrossEntropyLoss() #input = torch.randn(3, 5, requires_grad=True) #target = torch.empty(3, dtype=torch.long).random_(5) #必须是torch.long类型 loss = nn.CrossEntropyLoss() input = torch.tensor([[-0.7678, 0.2773, -0.9249, 1.4503, 0.5256], [-0.8529, -1.4283, -0.3284, 1.8608, -0.3206], [ 0.1201, -0.7239, 0.6798, -0.8335, -2.1710]], requires_grad=True) target = torch.tensor([0, 0, 1], dtype=torch.long) #必须是torch.long类型, 且input中每一行对应的target中的一个数字(不是one-hot) output = loss(input, target) print(output.item()) #nn.LogSoftmax()和nn.NLLLoss()分开计算如下: input = torch.tensor([[-0.7678, 0.2773, -0.9249, 1.4503, 0.5256], [-0.8529, -1.4283, -0.3284, 1.8608, -0.3206], [ 0.1201, -0.7239, 0.6798, -0.8335, -2.1710]], requires_grad=True) target = torch.tensor([0, 0, 1], dtype=torch.long) #必须是torch.long类型 sft = nn.LogSoftmax(dim=1)(input) nls = nn.NLLLoss()(sft, target)
numpy实现交叉熵函数
def label_encoder(target, nclass): label = np.zeros((target.shape[0],nclass)) for i in range(target.shape[0]): label[i][target[i]]=1 print(label) return label def cross_entropy_loss(pred, target): target = label_encoder(target, pred.shape[1]) #one-hot编码 pred_exp = np.exp(pred) pred_sft = pred_exp/(np.sum(pred_exp, axis=1)[:,None]) print(np.log(pred_sft)) loss = -np.sum(np.log(pred_sft)*target)/pred.shape[0] #取一个batch的平均值 print(loss) return loss if __name__=="__main__": input = np.array([[-0.7678, 0.2773, -0.9249, 1.4503, 0.5256], [-0.8529, -1.4283, -0.3284, 1.8608, -0.3206], [ 0.1201, -0.7239, 0.6798, -0.8335, -2.1710]]) target = np.array([0, 0, 1]) loss = cross_entropy_loss(input,target)
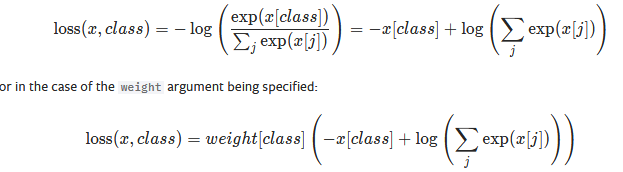
nn.BCELoss() 二分类时的交叉熵(Bianry cross entropy),
nn.CrossEntropyLoss()的特例,即分类限定为二分类,label必须为0,1; 模型输出最后一层需要用sigmoid函数
criterion = nn.BCELoss() input = torch.randn(5, 1, requires_grad=True) target = torch.empty(5,1).random_(2) pre = nn.Sigmoid()(input) loss = criterion(pre, target) print(loss.item())
nn.BCEWithLogitsLoss(): 将nn.sigmoid()和nn.BCELoss()结合
criterion = nn.BCEWithLogitsLoss() input = torch.randn(5, 1, requires_grad=True) target = torch.empty(5,1).random_(2) loss = criterion(input, target) print(loss.item())
4.3 定义优化器
通过loss函数计算出网络的预测值和真实值之间的loss后,loss.backward()能将梯度反向传播,需要根据梯度来更新网络的权重系数。优化器能帮我们实现权重系数的更新。
不采用优化器:
#不用优化器,更新系数
criterion = nn.CrossEntropyLoss() input = torch.randn(5, 2, requires_grad=True) target = torch.empty(5,1).random_(2) pre = net(input) loss = criterion(pre, target) net.zero_grad() loss.backward() learing_rate=0.01 for f in net.parameters(): f.data.sub_(f.grad.data*learing_rate) #更新系数
采用优化器:
#采用优化器,更新系数 import torch.optim as optim optimizer = optim.SGD(net.parameters(), lr=0.01) criterion = nn.CrossEntropyLoss() input = torch.randn(5, 2, requires_grad=True) target = torch.empty(5,1).random_(2) optimizer.zero_grad() pre = net(input) loss = criterion(pre, target) loss.backward() optimizer.step() #更新系数
4.4 定义DataLoader
进行网络训练时,可以一次性导入所有数据(BGD,batch gradient descent), 可以一次导入一条数据(SGD, stochastic gradient descent),还可以一次导入部分数据(MBGD, Mini-batch gradient descent), 目前MBGD为较为常用的方法。而且一般情况,无特殊说明时,论文里面提及SGD,都指代的时MGBD的方式进行数据导入和网络训练。
采用pytorch自带的数据集:
#采用pytorch自带的数据集 import torchvision import torchvision.transform as transforms transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5)) ] ) trainset = torchvision.datasets.CIFAR10(root="./data", train=True, download=True, transform = transform) #下载数据集 trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2) #每一个mini-batch,导入4条数据
采用自定义的数据集:
class RandomDataset(Dataset): def __init__(self, size, length): self.len = length self.data = torch.randn(length, size) def __getitem__(self, index): return self.data[index] def __len__(self): return self.len rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size), batch_size=batch_size, shuffle=True)
class MyDataset(Dataset): def __init__(self, root_dir, annotations_file, transform=None): self.root_dir = root_dir self.annotations_file = annotations_file self.transform = transform if not os.path.isfile(self.annotations_file): print(self.annotations_file + 'does not exist!') self.file_info = pd.read_csv(annotations_file, index_col=0) self.size = len(self.file_info) def __len__(self): return self.size def __getitem__(self, idx): image_path = self.file_info['path'][idx] if not os.path.isfile(image_path): print(image_path + ' does not exist!') return None image = Image.open(image_path).convert('RGB') label_species = int(self.file_info.iloc[idx]['species']) sample = {'image': image, 'species': label_species} if self.transform: sample['image'] = self.transform(image) return sample train_transforms = transforms.Compose([transforms.Resize((600, 600)), transforms.RandomCrop(500), transforms.RandomHorizontalFlip(), transforms.ToTensor(), ]) val_transforms = transforms.Compose([transforms.Resize((500, 500)), transforms.ToTensor() ]) train_dataset = MyDataset(root_dir= ROOT_DIR + TRAIN_DIR, annotations_file= TRAIN_ANNO, transform=train_transforms) test_dataset = MyDataset(root_dir= ROOT_DIR + VAL_DIR, annotations_file= VAL_ANNO, transform=val_transforms) train_loader = DataLoader(dataset=train_dataset, batch_size=8, shuffle=True) test_loader = DataLoader(dataset=test_dataset)
4.5 神经网络训练:
准备好数据集,定义好模型,loss函数,优化器,数据迭代器,便可以进行网络训练了。下面是一个简单的图片分类器,将图片分成三类:兔子,老鼠,鸡
A. 准备数据集的label文件:
import pandas as pd import os from PIL import Image # ROOTS = '../Dataset/' ROOTS = '/home/ai/project/data/project_I/Dataset/' PHASE = ['train', 'val'] SPECIES = ['rabbits', 'rats', 'chickens'] # [0,1,2] DATA_info = {'train': {'path': [], 'species': []}, 'val': {'path': [], 'species': []} } for p in PHASE: for s in SPECIES: DATA_DIR = ROOTS + p + '/' + s DATA_NAME = os.listdir(DATA_DIR) for item in DATA_NAME: try: img = Image.open(os.path.join(DATA_DIR, item)) except OSError: pass else: DATA_info[p]['path'].append(os.path.join(DATA_DIR, item)) if s == 'rabbits': DATA_info[p]['species'].append(0) elif s == 'rats': DATA_info[p]['species'].append(1) else: DATA_info[p]['species'].append(2) ANNOTATION = pd.DataFrame(DATA_info[p]) ANNOTATION.to_csv('Species_%s_annotation.csv' % p) print('Species_%s_annotation file is saved.' % p)
生成的label文件格式如下,包括图片路径,以及对应的分类(0,1, 2依次代表'rabbits', 'rats', 'chickens')

B. 定义网络结构:
可以自己搭建全新的网络结构, 也可以采用成熟的网络架构,如AlexNet,VGG,GoogleNet, Resnet等。下面分别展示了自定义和借用Resnet网络结构:
import torch.nn as nn import torchvision import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 3, 3) self.maxpool1 = nn.MaxPool2d(kernel_size=2) self.relu1 = nn.ReLU(inplace=True) self.conv2 = nn.Conv2d(3, 6, 3) self.maxpool2 = nn.MaxPool2d(kernel_size=2) self.relu2 = nn.ReLU(inplace=True) self.conv3 = nn.Conv2d(6,12,3) self.fc1 = nn.Linear(12 * 123 * 123, 150) self.relu3 = nn.ReLU(inplace=True) self.drop = nn.Dropout2d() self.fc2 = nn.Linear(150, 3) # self.softmax1 = nn.Softmax(dim=1) def forward(self, x): x = self.conv1(x) x = self.maxpool1(x) x = self.relu1(x) x = self.conv2(x) x = self.maxpool2(x) x = self.relu2(x) x =nn.ReLU(nn.MaxPool2d(self.conv3(x),kernel_size=3)) # print(x.shape) x = x.view(-1, 12 * 123 * 123) x = self.fc1(x) x = self.relu3(x) x = F.dropout(x, training=self.training) x_species = self.fc2(x) # x_species = self.softmax1(x_species) return x_species
import torch.nn as nn import torchvision import torch.nn.functional as F from torchvision import models class Net(nn.Module): def __init__(self, model): super(Net, self).__init__() # self.conv1 = nn.Conv2d(3, 64, 3, padding=1) # self.conv2 = nn.Conv2d(64, 64, 3, padding=1) # self.conv3 = nn.Conv2d(64, 128, 3, padding=1) # self.conv4 = nn.Conv2d(128, 128, 3, padding=1) # self.conv5 = nn.Conv2d(128, 256, 3, padding=1) # self.conv6 = nn.Conv2d(256, 256, 3, padding=1) # self.conv7 = nn.Conv2d(256, 256, 3, padding=1) self.resnet18_layer = nn.Sequential(*list(model.children())[:-1]) self.fc1 = nn.Linear(512 * 1 * 1, 150) self.relu3 = nn.ReLU(inplace=True) # self.drop = nn.Dropout2d() self.fc2 = nn.Linear(150, 3) self.softmax1 = nn.Softmax(dim=1) def forward(self, x): # x = F.relu(self.conv1(x)) # x = F.max_pool2d(F.relu(self.conv2(x)),2) # x = F.relu(self.conv3(x)) # x = F.max_pool2d(F.relu(self.conv4(x)),2) # x = F.relu(self.conv5(x)) # x = F.relu(self.conv6(x)) # x = F.max_pool2d(F.relu(self.conv7(x)),2) x = self.resnet18_layer(x) # x = F.dropout(x, self.training) #print(x.shape) x = x.view(-1, 512 * 1 * 1) x = self.fc1(x) x = self.relu3(x) # x = F.dropout(x, training=self.training) x_species = self.fc2(x) #x_species = self.softmax1(x_species) return x_species
C. 定义训练主函数:
训练网络时,可以对自定义的网络从头训练,也可以采用在ImageNet上预训练好的网络,进行finetune,这里采用预训练好的Resnet16.
import os import matplotlib.pyplot as plt from torch.utils.data import DataLoader import torch from Species_Network import * from torchvision.transforms import transforms from PIL import Image import pandas as pd import random from torch import optim from torch.optim import lr_scheduler import copy ROOT_DIR = '../Dataset/' TRAIN_DIR = 'train/' VAL_DIR = 'val/' TRAIN_ANNO = 'Species_train_annotation.csv' VAL_ANNO = 'Species_val_annotation.csv' CLASSES = ['Mammals', 'Birds'] SPECIES = ['rabbits', 'rats', 'chickens'] class MyDataset(): def __init__(self, root_dir, annotations_file, transform=None): self.root_dir = root_dir self.annotations_file = annotations_file self.transform = transform if not os.path.isfile(self.annotations_file): print(self.annotations_file + 'does not exist!') self.file_info = pd.read_csv(annotations_file, index_col=0) self.size = len(self.file_info) def __len__(self): return self.size def __getitem__(self, idx): image_path = self.file_info['path'][idx] if not os.path.isfile(image_path): print(image_path + ' does not exist!') return None image = Image.open(image_path).convert('RGB') label_species = int(self.file_info.iloc[idx]['species']) sample = {'image': image, 'species': label_species} if self.transform: sample['image'] = self.transform(image) return sample train_transforms = transforms.Compose([transforms.Resize((500, 500)), transforms.RandomHorizontalFlip(), transforms.ToTensor(), ]) val_transforms = transforms.Compose([transforms.Resize((500, 500)), transforms.ToTensor() ]) train_dataset = MyDataset(root_dir= ROOT_DIR + TRAIN_DIR, annotations_file= TRAIN_ANNO, transform=train_transforms) test_dataset = MyDataset(root_dir= ROOT_DIR + VAL_DIR, annotations_file= VAL_ANNO, transform=val_transforms) train_loader = DataLoader(dataset=train_dataset, batch_size=128, shuffle=True) test_loader = DataLoader(dataset=test_dataset) data_loaders = {'train': train_loader, 'val': test_loader} device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(device) def visualize_dataset(): print(len(train_dataset)) idx = random.randint(0, len(train_dataset)) sample = train_loader.dataset[idx] print(idx, sample['image'].shape, SPECIES[sample['species']]) img = sample['image'] plt.imshow(transforms.ToPILImage()(img)) plt.show() visualize_dataset() def train_model(model, criterion, optimizer, scheduler, num_epochs=50): Loss_list = {'train': [], 'val': []} Accuracy_list_species = {'train': [], 'val': []} best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 for epoch in range(num_epochs): print('Epoch {}/{}'.format(epoch, num_epochs - 1)) print('-*' * 10) # Each epoch has a training and validation phase for phase in ['train', 'val']: if phase == 'train': model.train() else: model.eval() running_loss = 0.0 corrects_species = 0 for idx,data in enumerate(data_loaders[phase]): #print(phase+' processing: {}th batch.'.format(idx)) inputs = data['image'].to(device) labels_species = data['species'].to(device) optimizer.zero_grad() with torch.set_grad_enabled(phase == 'train'): x_species = model(inputs) x_species = x_species.view(-1,3) _, preds_species = torch.max(x_species, 1) loss = criterion(x_species, labels_species) if phase == 'train': loss.backward() optimizer.step() running_loss += loss.item() * inputs.size(0) corrects_species += torch.sum(preds_species == labels_species) epoch_loss = running_loss / len(data_loaders[phase].dataset) Loss_list[phase].append(epoch_loss) epoch_acc_species = corrects_species.double() / len(data_loaders[phase].dataset) epoch_acc = epoch_acc_species Accuracy_list_species[phase].append(100 * epoch_acc_species) print('{} Loss: {:.4f} Acc_species: {:.2%}'.format(phase, epoch_loss,epoch_acc_species)) if phase == 'val' and epoch_acc > best_acc: best_acc = epoch_acc_species best_model_wts = copy.deepcopy(model.state_dict()) print('Best val species Acc: {:.2%}'.format(best_acc)) model.load_state_dict(best_model_wts) torch.save(model.state_dict(), 'best_model.pt') print('Best val species Acc: {:.2%}'.format(best_acc)) return model, Loss_list,Accuracy_list_species network = Net().to(device) optimizer = optim.SGD(network.parameters(), lr=0.005, momentum=0.9, weight_decay=1e-6) #weight_decay:L2正则项惩罚 criterion = nn.CrossEntropyLoss() exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1) # Decay LR by a factor of 0.1 every 1 epochs model, Loss_list, Accuracy_list_species = train_model(network, criterion, optimizer, exp_lr_scheduler, num_epochs=100) x = range(0, 100) y1 = Loss_list["val"] y2 = Loss_list["train"] plt.plot(x, y1, color="r", linestyle="-", marker="o", linewidth=1, label="val") plt.plot(x, y2, color="b", linestyle="-", marker="o", linewidth=1, label="train") plt.legend() plt.title('train and val loss vs. epoches') plt.ylabel('loss') plt.savefig("train and val loss vs epoches.jpg") plt.close('all') # 关闭图 0 y5 = Accuracy_list_species["train"] y6 = Accuracy_list_species["val"] plt.plot(x, y5, color="r", linestyle="-", marker=".", linewidth=1, label="train") plt.plot(x, y6, color="b", linestyle="-", marker=".", linewidth=1, label="val") plt.legend() plt.title('train and val Species acc vs. epoches') plt.ylabel('Species accuracy') plt.savefig("train and val Species acc vs epoches.jpg") plt.close('all') ######################################## Visualization ################################## def visualize_model(model): model.eval() with torch.no_grad(): for i, data in enumerate(data_loaders['val']): inputs = data['image'] labels_species = data['species'].to(device) x_species = model(inputs.to(device)) x_species = x_species.view( -1,2) _, preds_species = torch.max(x_species, 1) print(inputs.shape) plt.imshow(transforms.ToPILImage()(inputs.squeeze(0))) plt.title('predicted species: {}\n ground-truth species:{}'.format(SPECIES[preds_species],SPECIES[labels_species])) plt.show() visualize_model(model)
import os import matplotlib.pyplot as plt from torch.utils.data import Dataset, DataLoader import torch from Spe_Network import * from torchvision.transforms import transforms from PIL import Image import pandas as pd import random from torch import optim from torch.optim import lr_scheduler import copy from torchvision import models import logging logging.basicConfig(level=logging.DEBUG, filename="train.log", filemode="a+") ROOT_DIR = '/home/ai/project/data/project_I/Dataset/' TRAIN_DIR = 'train/' VAL_DIR = 'val/' TRAIN_ANNO = 'Species_train_annotation.csv' VAL_ANNO = 'Species_val_annotation.csv' CLASSES = ['Mammals', 'Birds'] SPECIES = ['rabbits', 'rats', 'chickens'] class MyDataset(Dataset): def __init__(self, root_dir, annotations_file, transform=None): self.root_dir = root_dir self.annotations_file = annotations_file self.transform = transform if not os.path.isfile(self.annotations_file): print(self.annotations_file + 'does not exist!') self.file_info = pd.read_csv(annotations_file, index_col=0) self.size = len(self.file_info) def __len__(self): return self.size def __getitem__(self, idx): image_path = self.file_info['path'][idx] if not os.path.isfile(image_path): print(image_path + ' does not exist!') return None image = Image.open(image_path).convert('RGB') label_species = int(self.file_info.iloc[idx]['species']) sample = {'image': image, 'species': label_species} if self.transform: sample['image'] = self.transform(image) return sample train_transforms = transforms.Compose([transforms.Resize((600, 600)), transforms.RandomCrop(500), transforms.RandomHorizontalFlip(), transforms.ToTensor(), ]) val_transforms = transforms.Compose([transforms.Resize((500, 500)), transforms.ToTensor() ]) train_dataset = MyDataset(root_dir= ROOT_DIR + TRAIN_DIR, annotations_file= TRAIN_ANNO, transform=train_transforms) test_dataset = MyDataset(root_dir= ROOT_DIR + VAL_DIR, annotations_file= VAL_ANNO, transform=val_transforms) train_loader = DataLoader(dataset=train_dataset, batch_size=8, shuffle=True) test_loader = DataLoader(dataset=test_dataset) data_loaders = {'train': train_loader, 'val': test_loader} device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(device) def visualize_dataset(): print(len(train_dataset)) idx = random.randint(0, len(train_dataset)) sample = train_loader.dataset[idx] print(idx, sample['image'].shape, SPECIES[sample['species']]) img = sample['image'] plt.imshow(transforms.ToPILImage()(img)) plt.show() visualize_dataset() def train_model(model, criterion, optimizer, scheduler, num_epochs=50): Loss_list = {'train': [], 'val': []} Accuracy_list_species = {'train': [], 'val': []} best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 for epoch in range(num_epochs): print('Epoch {}/{}'.format(epoch, num_epochs - 1)) print('-*' * 10) # Each epoch has a training and validation phase for phase in ['train', 'val']: if phase == 'train': model.train() else: model.eval() running_loss = 0.0 corrects_species = 0 for idx,data in enumerate(data_loaders[phase]): #print(phase+' processing: {}th batch.'.format(idx)) inputs = data['image'].to(device) labels_species = data['species'].to(device) optimizer.zero_grad() with torch.set_grad_enabled(phase == 'train'): x_species = model(inputs) x_species = x_species.view(-1,3) _, preds_species = torch.max(x_species, 1) loss = criterion(x_species, labels_species) if phase == 'train': loss.backward() optimizer.step() running_loss += loss.item() * inputs.size(0) corrects_species += torch.sum(preds_species == labels_species) epoch_loss = running_loss / len(data_loaders[phase].dataset) Loss_list[phase].append(epoch_loss) epoch_acc_species = corrects_species.double() / len(data_loaders[phase].dataset) epoch_acc = epoch_acc_species Accuracy_list_species[phase].append(100 * epoch_acc_species) print('{} Loss: {:.4f} Acc_species: {:.2%}'.format(phase, epoch_loss,epoch_acc_species)) logging.info('{} Loss: {:.4f} Acc_species: {:.2%}'.format(phase, epoch_loss,epoch_acc_species)) if phase == 'val' and epoch_acc > best_acc: best_acc = epoch_acc_species best_model_wts = copy.deepcopy(model.state_dict()) print('Best val species Acc: {:.2%}'.format(best_acc)) logging.info('Best val species Acc: {:.2%}'.format(best_acc)) model.load_state_dict(best_model_wts) torch.save(model.state_dict(), 'best_model.pt') print('Best val species Acc: {:.2%}'.format(best_acc)) logging.info('Best val species Acc: {:.2%}'.format(best_acc)) return model, Loss_list,Accuracy_list_species # vgg16 = models.vgg16(pretrained=True) res18 = models.resnet18(pretrained=True) network = Net(res18).to(device) optimizer = optim.SGD(network.parameters(), lr=0.005, momentum=0.9, weight_decay=1e-4) #weight_decay:L2正则项惩罚 criterion = nn.CrossEntropyLoss() exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1) # Decay LR by a factor of 0.1 every 1 epochs model, Loss_list, Accuracy_list_species = train_model(network, criterion, optimizer, exp_lr_scheduler, num_epochs=100) # x = range(0, 100) # y1 = Loss_list["val"] # y2 = Loss_list["train"] # plt.plot(x, y1, color="r", linestyle="-", marker="o", linewidth=1, label="val") # plt.plot(x, y2, color="b", linestyle="-", marker="o", linewidth=1, label="train") # plt.legend() # plt.title('train and val loss vs. epoches') # plt.ylabel('loss') # plt.savefig("train and val loss vs epoches.jpg") # plt.close('all') # 关闭图 0 # y5 = Accuracy_list_species["train"] # y6 = Accuracy_list_species["val"] # plt.plot(x, y5, color="r", linestyle="-", marker=".", linewidth=1, label="train") # plt.plot(x, y6, color="b", linestyle="-", marker=".", linewidth=1, label="val") # plt.legend() # plt.title('train and val Species acc vs. epoches') # plt.ylabel('Species accuracy') # plt.savefig("train and val Species acc vs epoches.jpg") # plt.close('all') ######################################## Visualization ################################## def visualize_model(model): model.eval() with torch.no_grad(): for i, data in enumerate(data_loaders['val']): inputs = data['image'] labels_species = data['species'].to(device) x_species = model(inputs.to(device)) x_species = x_species.view( -1,2) _, preds_species = torch.max(x_species, 1) print(inputs.shape) plt.imshow(transforms.ToPILImage()(inputs.squeeze(0))) plt.title('predicted species: {}\n ground-truth species:{}'.format(SPECIES[preds_species],SPECIES[labels_species])) plt.show() # visualize_model(model)
4.6 多gpu训练
如果一台机器上有多张gpu卡,可以设置多个gpu同时训练, 官网示例代码如下:
# https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html # https://pytorch.org/tutorials/beginner/former_torchies/parallelism_tutorial.html import torch import torch.nn as nn from torch.utils.data import Dataset, DataLoader # Parameters and DataLoaders input_size = 5 output_size = 2 batch_size = 10 data_size = 1000 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") class RandomDataset(Dataset): def __init__(self, size, length): self.len = length self.data = torch.randn(length, size) def __getitem__(self, index): return self.data[index] def __len__(self): return self.len rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size), batch_size=batch_size, shuffle=True) class Model(nn.Module): # Our model def __init__(self, input_size, output_size): super(Model, self).__init__() self.fc = nn.Linear(input_size, output_size) def forward(self, input): output = self.fc(input) print("\tIn Model: input size", input.size(), "output size", output.size()) return output model = Model(input_size, output_size) if torch.cuda.device_count() > 1: print("Let's use", torch.cuda.device_count(), "GPUs!") # dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs model = nn.DataParallel(model) model.to(device) for data in rand_loader: input = data.to(device) output = model(input) print("Outside: input size", input.size(), "output_size", output.size())
https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html
参考:
https://github.com/Hong-Bo/hands-on-pytorch/blob/master/alex_net/alex_net.py
https://pytorch.org/tutorials/

