

python练手项目
为了练习python,将python练习册学习了一遍,记录下自己的答案,习题地址:https://github.com/Yixiaohan/show-me-the-code
第 0000 题: 将你的 QQ 头像(或者微博头像)右上角加上红色的数字,类似于微信未读信息数量那种提示效果。
(使用到PIL(pip install pillow)图像处理模块)


#coding:utf-8 #PIL模块图像处理文档 https://pillow.readthedocs.io/en/stable/reference/index.html from PIL import Image, ImageDraw, ImageFont import base64 #下载微信头像 # t='/9j/4AAQSkZJRgABAQEAAQABAAD/2wBDABQODxIPDRQSEBIXFRQYHjIhHhwcHj0sLiQySUBMS0dARkVQWnNiUFVtVkVGZIhlbXd7gYKBTmCNl4x9lnN+gXz/2wBDARUXFx4aHjshITt8U0ZTfHx8fHx8fHx8fHx8fHx8fHx8fHx8fHx8fHx8fHx8fHx8fHx8fHx8fHx8fHx8fHx8fHz/wAARCACEAIQDASIAAhEBAxEB/8QAGwAAAQUBAQAAAAAAAAAAAAAAAAEDBAUGAgf/xAA2EAABAwIEAwgBAQcFAAAAAAABAAIDBBEFEiExE0FRBhQiMlNhcZJCUhYjM4GRoeFEYoKxwf/EABkBAAMBAQEAAAAAAAAAAAAAAAABAgMEBf/EACMRAAICAgMAAgIDAAAAAAAAAAABAhEDEgQhMRNBFDJRYXH/2gAMAwEAAhEDEQA/ANb3Sn9CL6D2R3Sn9CL6FPIQAz3Sn9CL6BHdKf0IvoE8hADPdKf0IvoEd1pvQi+gXU0zIWZpHBo91VVGMC9oR/MIoznkjD0sjTUo3giH/ALgxUg3hh+gVCa6SUkvcb366JO8P1DnXPJVqcz5L+kX/Do/Sh+gXQp6U7Qw/QKibPpdpO10/HO6/mRRP5Ul66ouO603oRfQI7rTehF9AoMNY/mbgKbDUMk56qTox54T6F7pT+hF9AjulP6EX0KdulQbjPdKf0IvoPZHdKf0IvoE7dKgBnulP6EX0CE8hAHL3tjYXPIDRuSoseIwyE5b22uonaGR0dLGBs54BVOJjH47gN5ppWcubLKMqia1rg4AjZczSthjc95s1ouVTYRjEc9YaQnxFuZuu/VRe1VcQWUsbrfk7VFd0arJcNiHXYs+sn00iGzf/VFdKGkeL5F1BLwDqflTcJwxuJyZqhzuENGtBt/VXdM51Dd9gyricC1jtfdP8bQWs7mpGIdloGtJw+a0wF+C9w1+VTU0rh+7eMskRsQd/hJSt0y8nHUY7RdlrFJ4vMCDsU/HL7aW3Vc0ty5tmt0siqqnQQDKLuJsAFTOXTZ0i4jedzqpMUmxFlVUWD4vOwTPmjhvqGO1UxneKaQRVrAHO8j2Hwu/youysnGnBbel3TT5vC4/CkhU8TyCDfVWkUmaMFJo342XZav0YrqxtI0XF3O2CjUuK8c7Cw3sqnFqkT1ryHfu2DKNdPdMUTi14yXtZOujPLllb1ZsGuzAEbFCapb8Bt0KDtg3KKY1ilJ3yikib592/IWJq5jHG9j/AAuGhHO69CWc7RYAay9TSACYDxM/X/lUmZ5Me3ZiI5pYqhs8Ti2RhuCOSnVFXLVzmaUjO7U2CjvifDJkljcx3MOFl00XNgqREmJK7LGfdXmGVRghfwyA/LdvzZU08QMdr2PymIqySA2PLmk2XjVrolOlqaHFiXR8Z52Lxe9xvdd4lKZaiCc/xZYgZB1cNLobjEskfCa0u00CadHIXmSa5J5AbBP3wbbiqQrKl/DbcEa2J6paupdHUMcy12NuBbY9V0ItGj8RrbouayIxiKpa3M1ws8FNmUK2LrAe0X8CGeWSWWSTK7MBZoOxC1VbHHJTvbJba49ivPaCooIJWSNY5pa4O8RvqNlZVOPvrHcGnuXP0v0UdnRTp2i4hlDwDmH81zX1z4Y+Cx2UPFyFxTxlsbAeQS10YfC11rlv91R5CdS7KmxNjY6nmrfDoTM5gDbdVGpqN88gs0uP/S0dHSNpmW0LjuQiTOiGN5H/AEPtblaABoELtCg9EEIQgCg7WCIYeC5rS/MMptqFjmNvrutZ2xv3OLpnWVYcrTYXKuJzz9OJfAM7/J78ymDPE8WMRNuacxQuaImfjluVBbIQHDqEpIqEbVkxk8bPIzKPhOGUukBEoNzbXRQo5g2FzTvySwyMEbw8AncpbMr40TWvcDlD28+afhnDIyxzmG/U6KrjezhuzDUbIY5nCJcBmCewniSLM0NDK4Bsxa466G4UykigpJQIxc/qvuqDiNEINhmT1DUObO0XJYTaxQmv4Injk16bKJ4cL3NvZS4mNeQCNOY6qvpnEaHL8qfACHDXmqR5r6ZcxsaxoDGho6ALtI3ylKsz2V4CEIQMEIQgCg7XNJw1pts8LJU7c5IW47RQcfCperRnWDY/LqVcTnyLsMWBkkjABPgFgoD6WeMAuieAedlosMj7y/jyC5YMrVaBoc+w2bp/NaLHt2d+Dj7Y02jCEEGxBB90i0WPT0xkFOYsz9+IOSoCw5ywC59llJUyJw1dJnCE5BBJUSiKIZnnYKXh9CypqZKepcYHhpsTyI6qLM6ICn0NOXSN6+ZO93YxghdGx8zHnK9h8wVhSQmEEuAJO5VxVk5ZfHGn6yxpMwYGnlzsrSlH7wdFXUuYCziNOQVrQjNIDqmzyquSZbjYJUIUHrghCEACEIQA1URiWF7CAQ4EWK8zqojBUSRnQscRovUViu1mHcCcVUbTlk83sU0ZzX2QcKxCOCF0cmh1IPVSxibG07hDd8ttAFniLqdSyiKPwix69VspuqNly5QhqkI17H1Mc8t3OZyclgEUNcamwI1LW32spT5I3+dgdcdNU3aIu8MbbbaLPVMzXLi/YjEQZDWuqIBuTZoFwLp+Rk1TJxpcrSRbMRrZdkkCzcrR7Dkm8r3Oy3A10NrJqKZEuTJ/qqO4RFGbtIvzPNPNc4vytJLc26ZEJdqbAA5VLZEWhtrApnHJ32iZG0E6ac9FdYazQuVNT6yAC9/cLSUsXChA2PNTIWGO2T/B9CEKD0gQhCABCEIAFX442M4VUGVocGsJF+vJWCqe0snDwafS+azf7oFLw88cLJRIQLc1zIXDdoTRersxSsmsqPdPQyNLdCRrqkwfCZ8WMvAc1vDAvm53Vi3spiTRcOjB6XRYnCyGJBY3Nxf+ifYQNQb8wnm9lcSuBmjABvupcHZOqdYzVQabfiU9iHibIgeAzxG4TjZG83DqPhUVc+WlrJqbMSI3ltzzXdHLK6RoLC/oEWRLE0qNXhbg+pYdwDzWlGyyuHOnY9pdAWi4K1TTdoKmRfGfqFQhCk6wQhCABCEIAFBxSmfWUckAAGYaHoVOQgTVnnlTgGJsJBpzIL7tcCo37P4i7/TFvu4hemJLA8k7JUUzG4RS1mGQuY1gu43cRzU/vdZ0ctEY2n8Qk4TP0hFlUZ8VdX/uXQqaw7XV9wmfpCBGwfiEWFGHxDBKytq3VLGtzO8w2spNDhVZC0B9NqDuHBbHK3oUqLInjU1TKWlpqu/jjyC/N11bsDgAHWXaEmGPFHH4CEIQaAhCEACEIQAIQhAAhCEACEIQAIQhAAhCEACEIQAIQhAAhCEAf//Z' # s = base64.b64decode(t); # with open('avatar.jpg','wb') as f: # f.write(s); #测试字体格式 # font2 = ImageFont.truetype('C:\\Windows\\Fonts\\simhei.ttf',20) # draw.text((0,0), u'ps软件啊', font=font2, fill=(235,177,58)) # im.save('avatar2.jpg','JPEG') def addNumber(image,number): im = Image.open(image) draw = ImageDraw.Draw(im) font = ImageFont.truetype('C:\\Windows\\Fonts\\simhei.ttf',45) #设置字体格式及大小 (C:\\Windows\\Fonts下存放windows相关的字体文件,这里采用黑体常规) draw.text((im.size[0]-35,0),str(number),font=font,fill=(255,0,0)) #在图上绘制数字5, (x,y)为绘制点坐标,font为字体,fill为颜色 im.save('avatar1.jpg','JPEG') #保存文件,第二个参数为文件格式 if __name__=='__main__': addNumber('avatar.jpg',5)
第 0001 题: 做为 Apple Store App 独立开发者,你要搞限时促销,为你的应用生成激活码(或者优惠券),使用 Python 如何生成 200 个激活码(或者优惠券)?
#coding:utf-8 #Python 生成 200 个激活码(或者优惠券) import random import string chars = string.ascii_letters + string.digits #26个字母的大小写和数字组合 def generateCode(count,length): for x in range(count): code='' for y in range(length): code = code+random.choice(chars) yield code if __name__=="__main__": codes = generateCode(200,20) #print codes for code in codes: print code
第 0002 题: 将 0001 题生成的 200 个激活码(或者优惠券)保存到 MySQL 关系型数据库中。
#coding:utf-8 # 将200 个激活码(或者优惠券)保存到 MySQL 关系型数据库中 import random import string import MySQLdb chars = string.ascii_letters + string.digits #26个字母的大小写和数字组合 def generateCode(count,length): for x in range(count): code='' for y in range(length): code = code+random.choice(chars) yield code if __name__=="__main__": conn = MySQLdb.connect(host='127.0.0.1',user='root',passwd='', db='mydb',charset='utf8',port=3306) cursor = conn.cursor() cursor.execute(""" CREATE TABLE IF NOT EXISTS code_table( id INT PRIMARY KEY AUTO_INCREMENT NOT NULL, code VARCHAR(64) NOT NULL); """) codes = generateCode(200,20) #print codes for code in codes: cursor.execute("""INSERT INTO code_table(code) VALUES('%s');"""%code) conn.commit() conn.close()
第 0003 题: 将 0001 题生成的 200 个激活码(或者优惠券)保存到 Redis 非关系型数据库中。
#coding:utf-8 #将200 个激活码(或者优惠券)保存到 Redis 非关系型数据库中 import random import string import redis chars = string.ascii_letters + string.digits #26个字母的大小写和数字组合 def generateCode(count,length): for x in range(count): code='' for y in range(length): code = code+random.choice(chars) yield code if __name__=="__main__": pool = redis.ConnectionPool(host='127.0.0.1',port=6379) r = redis.Redis(connection_pool=pool) pipe = r.pipeline(transaction=False) codes = generateCode(200,20) for code in codes: pipe.lpush('code_list',code) pipe.execute()
第 0004 题: 任一个英文的纯文本文件,统计其中的单词出现的个数。
#coding:utf-8 # 任一个英文的纯文本文件,统计其中的单词出现的个数 from collections import Counter import string punctuations = string.punctuation + string.whitespace #标点符号和空格(换行,制表符等) def countWords(file): with open(file,'r') as f: lines = f.readlines() words_list=[] for line in lines: words = line.split() words = [word.strip(punctuations).lower() for word in words] #去除掉单词开头或结尾的标点符号及空格,换行等 words_list.extend(words) counter_dict = Counter(words_list) #返回一个字典,键为单词,值为出现次数 return counter_dict if __name__ =='__main__': counter_dict = countWords('The zen of python.txt') for key,value in counter_dict.items(): print "%s : %s"%(key,value)
The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!
第 0005 题: 你有一个目录,装了很多照片,把它们的尺寸变成都不大于 iPhone5 分辨率的大小。
#coding:utf-8 #你有一个目录,装了很多照片,把它们的尺寸变成都不大于 iPhone5 分辨率的大小。 import os from PIL import Image def thumbnailImage(path): files = os.listdir(path) images = [os.path.join(path,file) for file in files if file.endswith('.jpg') ] # 找到jpg文件,并构造其路径 print images for image in images: name,ext = os.path.splitext(image) #得到文件名 image = Image.open(image) image.thumbnail((1136,640)) # iphone分辨率为1136*640,按给定的像素值进行缩放, image.save(name+'.thumbnail.jpg','JPEG') if __name__=="__main__": path = "D:\\Python\\myprogram\\0005\\images" #用反斜线转义路径 thumbnailImage(path)
第 0006 题: 你有一个目录,放了你一个月的日记,都是 txt,为了避免分词的问题,假设内容都是英文,请统计出你认为每篇日记最重要的词。
#coding:utf-8 #你有一个目录,放了你一个月的日记,都是 txt,为了避免分词的问题,假设内容都是英文,请统计出你认为每篇日记最重要的词。 from collections import Counter import os import string punctuations = string.punctuation + string.whitespace #标点符号和空格(换行,制表符等) ignored_words=['the','what','how','where','why','him','she','her','they','them','and'] #这里根据单词出现频率来判断重要性 def judgeWord(counter_dict): sort_list = sorted(counter_dict.items(),key=lambda x:x[1],reverse=True) #按单词出现次数从大到小进行排序 for i in range(10): #从出现次数最多的10个单词中选择,不然返回第十一个 word= sort_list[i][0] if len(word)>2 and word not in ignored_words: #只包含两个或一个字符的单词忽略 return sort_list[i] return sort_list[10] def countWords(file): with open(file,'r') as f: words =f.read().split() words_list = [word.strip(punctuations).lower() for word in words] #去除掉单词开头或结尾的标点符号及空格,换行等 counter_dict = Counter(words_list) word = judgeWord(counter_dict) return word if __name__=="__main__": path="D:\\Python\\myprogram\\0006\\diaries" files = os.listdir(path) txt_files = [os.path.join(path,file) for file in files if file.endswith('.txt')] #print txt_files for txt_file in txt_files: word = countWords(txt_file) print "%s %s"%(os.path.basename(txt_file),word)
第 0007 题: 有个目录,里面是你自己写过的程序,统计一下你写过多少行代码。包括空行和注释,但是要分别列出来。
#coding:utf-8 #有个目录,里面是你自己写过的程序,统计一下你写过多少行代码。包括空行和注释,但是要分别列出来。 import os def countCodes(file): code=0 comment=0 blank_line=0 with open(file,'r') as f: lines = f.readlines() i=0 print len(lines) while i< len(lines): line = lines[i].strip() if len(line)==0: #判断是否为空行 blank_line += 1 elif line.startswith('#'): #判断是否为#开头的单行注释 comment += 1 elif line.startswith('"""'): #判断是否为"""开头的多行注释 flag=True if line.count('"""')==2: #判断是否出现这种注释: """注释内容""" flag=False else: i = i+1 comment +=1 while flag and i<len(lines): comment += 1 newline = lines[i].strip() if newline.endswith('"""'): flag=False else: i = i+1 elif line.startswith("'''"): #判断是否为'''开头的多行注释 flag=True if line.count("'''")==2: flag=False else: i = i+1 comment +=1 while flag and i<len(lines): comment += 1 newline = lines[i].strip() if newline.endswith("'''"): flag=False else: i = i+1 else: code += 1 i = i+1 return [code,comment,blank_line] if __name__=="__main__": path="D:\\PyCharm\\tianmaoCrawl" files = os.listdir(path) py_files = [os.path.join(path,file) for file in files if file.endswith('.py')] counts = {'code':0,'comment':0,'blank_line':0} for file in py_files: results = countCodes(file) print results counts['code'] = counts['code']+results[0] counts['comment'] = counts['comment']+results[1] counts['blank_line'] = counts['blank_line']+results[2] print counts
第 0008 题: 一个HTML文件,找出里面的正文。
第 0009 题: 一个HTML文件,找出里面的链接。
分别用lxml模块和BeautifulSoup模块提取了链接属性和文本内容,代码如下:
#coding:utf-8 import requests from lxml import html from bs4 import BeautifulSoup #下载一个html文件 # response = requests.get("https://www.cnblogs.com/silence-cho/p/9786069.html") # print type(response.text) # with open('python.html','w') as f: # f.write(response.text.encode('utf-8')) #使用lxml模块 with open('python.html','r') as f: html_file = f.read().decode('utf-8') tree = html.fromstring(html_file) a_tags = tree.xpath('//a[@href]') #找到a标签,打印href属性 for a_tag in a_tags: if a_tag.attrib.has_key('href'): print a_tag.attrib['href'] text = tree.text_content().encode('gbk',errors='ignore') #提取文本内容,写入文本文件 with open('text2.txt','w') as f: f.write(text) #也可以使用Beautiful模块 # soup = BeautifulSoup(html_file,'lxml') # a_tags = soup.find_all('a') # for a_tag in a_tags: # if a_tag.has_attr('href'): # print a_tag.attrs['href'] # text = soup.get_text().encode('gbk',errors='ignore') #使用get_text()方法 # with open('text1.txt','w') as f: # f.write(text) # strings = soup.strings #使用strings属性 # with open('string.txt','w') as f: # for string in strings: #strings 为generator类型,包含拿到的所有文本 # f.write(string.encode('gbk',errors='ignore'))
第 0010 题: 使用 Python 生成类似于下图中的字母验证码图片

#coding:utf-8 #第 0010 题: 使用 Python 生成类似于下图中的字母验证码图片 from PIL import Image, ImageDraw, ImageFont,ImageFilter import string import random letters = string.letters def getRanColor(): return (random.randint(64,255),random.randint(64,255),random.randint(64,255)) #数值越大,颜色越浅 def getRanColor2(): return (random.randint(32,127),random.randint(32,127),random.randint(0,127)) def getRanChar(): return random.choice(letters) size= (240,60) #图片大小为240*60 im = Image.new('RGBA',size,(255,255,255)) #背景为白色 draw = ImageDraw.Draw(im) font = ImageFont.truetype('C:\\Windows\\Fonts\\CENTURY.TTF',48) #背景填充点 for x in range(size[0]): for y in range(size[1]): draw.point((x,y),fill=getRanColor()) # x = random.randint(0, 236) # y = random.randint(0, 56) # draw.arc((x, y, x+4, y+4), 0, 90, fill=getRanColor()) #绘制弧线 for i in range(4): letter = getRanChar() #print letter x1 = 10+i*size[0]/4 draw.text((x1,2),letter,fill=getRanColor2(),font=font) # text = ' '.join(random.sample(letters,4)) #用空格拼接起来 # text_width,text_height = font.getsize(text) # x1 = (size[0]-text_width)/2 # y1 = (size[1]-text_height)/10 #除以2时字母总是靠下面? # draw.text((x1,y1),text,fill=getRanColor2(),font=font) im.filter(ImageFilter.BLUR) #模糊处理 im.save('captcha.png','PNG')
第 0011 题: 敏感词文本文件 filtered_words.txt,里面的内容为以下内容,当用户输入敏感词语时,则打印出 Freedom,否则打印出 Human Rights。
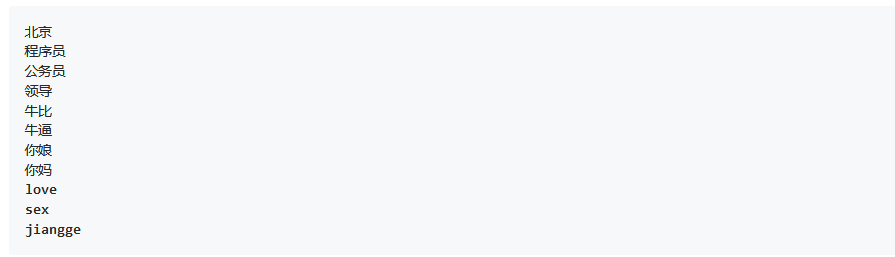
#coding:utf-8 def filterWords(word): with open('filtered_words.txt','r') as f: lines = f.readlines() words = [line.strip().decode('utf-8').encode('gbk') for line in lines] #filtered_words文件编码格式为utf-8,用户输入的为gbk格式 print words if word in words: print "Freedom" else: print "Human Rights" if __name__=="__main__": word = raw_input(u"请输入:".encode('gbk')) #windows命令行为gbk编码 filterWords(word)
第 0012 题: 敏感词文本文件 filtered_words.txt,里面的内容 和 0011题一样,当用户输入敏感词语,则用 星号 * 替换,例如当用户输入「北京是个好城市」,则变成「**是个好城市」。
#coding:utf-8 #第 0012 题: 敏感词文本文件 filtered_words.txt,里面的内容 和 0011题一样,当用户输入敏感词语,则用 星号 * 替换,例如当用户输入「北京是个好城市」,则变成「**是个好城市」。 def filterWords(sentence): with open('filtered_words.txt','r') as f: lines = f.readlines() words = [line.strip().decode('utf-8').encode('gbk') for line in lines] #filtered_words文件编码格式为utf-8,用户输入的为gbk格式 #print words for item in words: if item in sentence: print item,len(item) sentence = sentence.replace(item,"*"*len(item)) print sentence if __name__=="__main__": sentence = raw_input(u"请输入:".encode('gbk')) #windows命令行为gbk编码 filterWords(sentence)
第 0013 题: 用 Python 写一个爬图片的程序,爬 这个链接里的日本妹子图片 :-)
#coding:utf-8 #用Python 写一个爬图片的程序,爬取图片url="http://tieba.baidu.com/p/2166231880" import requests from lxml import html import hashlib def getName(url): m = hashlib.md5() m.update(url) name = m.hexdigest()+'.jpg' return name response = requests.get(url="http://tieba.baidu.com/p/2166231880",headers={"User-Agent":"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0"}) tree = html.fromstring(response.text) div_tags = tree.xpath("//div[@id='j_p_postlist']/div") #print tags image_urls = [] for tag in div_tags: url = tag.xpath(".//img[@class='BDE_Image']/@src") #匹配img标签的src属性 if url: image_urls.extend(url) for url in image_urls: im_name = getName(url) #对url进行hash摘要计算,拿到不同的图片名字 print im_name im = requests.get(url=url,headers={"User-Agent":"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0"}) with open(im_name,'wb') as f: f.write(im.content) #response.content为返回的bytes数据
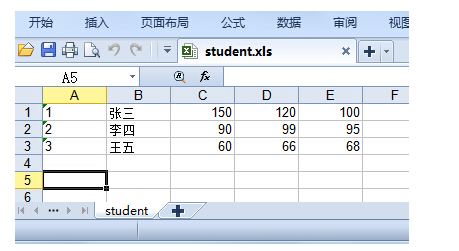
第 0014 题: 纯文本文件 student.txt为学生信息, 里面的内容(包括花括号)如下所示:
{ "1":["张三",150,120,100], "2":["李四",90,99,95], "3":["王五",60,66,68] }
请将上述内容写到 student.xls 文件中,如下图所示:
阅读资料 腾讯游戏开发 XML 和 Excel 内容相互转换
#coding:utf-8 #第 0014 题: 纯文本文件 student.txt为学生信息, 里面的内容(包括花括号)如下所示: # { # "1":["张三",150,120,100], # "2":["李四",90,99,95], # "3":["王五",60,66,68] # } #请将上述内容写到 student.xls 文件中 #python 操控excel模块(xlrd,xlwt,xlutils),其中读取xlrd, 写入xlwt import json import xlwt from collections import OrderedDict with open("students.txt",'r') as f: data = f.read() data_dict = json.loads(data,object_pairs_hook=OrderedDict) #设置object_pairs_hook=OrderedDict 反序列化时,记住解析的顺序,返回的为有序字典 #print type(data_dict) workbook = xlwt.Workbook() #写入数据应该为unicode,否则需设置编码格式,如book = Workbook(encoding='utf-8') sheet1 = workbook.add_sheet('Sheet 1',cell_overwrite_ok=True) #添加一张sheet表,设置cell_overwrite_ok=True,不然对单元格重复操作会报错 for i,(key,value) in enumerate(data_dict.items()): sheet1.write(i,0,key) #在单元格写入,(0,0)表示第一行第一列的单元格 for index,val in enumerate(value,1): sheet1.write(i,index,val) workbook.save("students.xls")
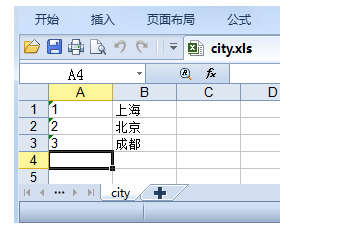
第 0015 题: 纯文本文件 city.txt为城市信息, 里面的内容(包括花括号)如下所示:
{ "1" : "上海", "2" : "北京", "3" : "成都" }
请将上述内容写到 city.xls 文件中,如下图所示:
#coding:utf-8 import json import xlwt from collections import OrderedDict with open("city.txt",'r') as f: data = f.read() ordata = json.loads(data,object_pairs_hook=OrderedDict) workbook = xlwt.Workbook() sheet1 = workbook.add_sheet("city",cell_overwrite_ok=True) for i,(key,value) in enumerate(ordata.items()): sheet1.write(i,0,key) sheet1.write(i,1,value) workbook.save("city.xls")
第 0016 题: 纯文本文件 numbers.txt, 里面的内容(包括方括号)如下所示:
[
[1, 82, 65535],
[20, 90, 13],
[26, 809, 1024]
]
请将上述内容写到 numbers.xls 文件中,如下图所示:

#coding:utf-8 import json import xlwt with open("numbers.txt",'r') as f: data = f.read() data_list = json.loads(data) #print data_list workbook = xlwt.Workbook() sheet1 = workbook.add_sheet("numbers",cell_overwrite_ok=True) for row,item in enumerate(data_list): for col, number in enumerate(item): sheet1.write(row,col,number) workbook.save("numbers.xls")
第 0017 题: 将 第 0014 题中的 student.xls 文件中的内容写到 student.xml 文件中,如
下所示:
<?xml version="1.0" encoding="UTF-8"?> <root> <students> <!-- 学生信息表 "id" : [名字, 数学, 语文, 英文] --> { "1" : ["张三", 150, 120, 100], "2" : ["李四", 90, 99, 95], "3" : ["王五", 60, 66, 68] } </students> </root>
#coding:utf-8 from xml.etree import ElementTree as ET from collections import OrderedDict import json import xlrd wb = xlrd.open_workbook("students.xls") students = wb.sheet_by_index(0) data=OrderedDict() for row in range(students.nrows): data[students.cell_value(row,0)]=[] for col in range(1,students.ncols): data[students.cell_value(row,0)].append(students.cell_value(row,col)) title=u""" <!-- 学生信息表 "id" : [名字, 数学, 语文, 英文] --> """ text_list = ['<?xml version="1.0" encoding="UTF-8"?>\n'] #第一行无法通过属性设置 root = ET.Element("root") students = ET.SubElement(root,"students") students.tail='\n' students.text=title+json.dumps(data,ensure_ascii=False).replace("],","],\n")+u"\n" xml_str = ET.tostring(root,encoding="utf-8") #输出字符窜编码格式 text_list.append(xml_str) with open("students.xml","w") as xf: xf.write("".join(text_list)) # tree = ET.ElementTree(root) # tree.write("students.xml") #转换txt文件到xml # with open("students.txt",'r') as f: # data = f.read() # text =["""<?xml version="1.0" encoding="UTF-8"?> # <root> # <students> # <!-- # 学生信息表 # "id" : [名字, 数学, 语文, 英文] # --> # """] # text.append(data) # text.append("""</students> # </root>""") # with open("students.xml","w") as xf: # xf.write("".join(text))
第 0018 题: 将 第 0015 题中的 city.xls 文件中的内容写到 city.xml 文件中,如下所示:
<?xmlversion="1.0" encoding="UTF-8"?> <root> <cities> <!-- 城市信息 --> { "1" : "上海", "2" : "北京", "3" : "成都" } </cities> </root>
#coding:utf-8 import xlrd from xml.etree import ElementTree as ET from collections import OrderedDict import json data = OrderedDict() wb = xlrd.open_workbook("city.xls") sheet = wb.sheet_by_index(0) for row in range(sheet.nrows): data[sheet.cell_value(row,0)]=sheet.cell_value(row,1) text_list = ['<?xmlversion="1.0" encoding="UTF-8"?>\n'] root = ET.Element("root") city = ET.SubElement(root,"cities") city.tail = "\n" title =u""" <!-- 城市信息 --> """ city.text =title+json.dumps(data,ensure_ascii=False, indent=2)+u"\n" #indent=2,使输出的数据换行显示,有两个空格缩进 text_list.append(ET.tostring(root,encoding="utf-8")) text = "".join(text_list) print text with open("city.xml","w") as xf: xf.write(text)
第 0019 题: 将 第 0016 题中的 numbers.xls 文件中的内容写到 numbers.xml 文件中,如下所示:
<?xml version="1.0" encoding="UTF-8"?> <root> <numbers> <!-- 数字信息 --> [ [1, 82, 65535], [20, 90, 13], [26, 809, 1024] ] </numbers> </root>
#coding:utf-8 from xml.etree import ElementTree as ET import json import xlrd wb = xlrd.open_workbook("numbers.xls") sheet = wb.sheet_by_index(0) data=[] for row in range(sheet.nrows): rd=[] for col in range(sheet.ncols): rd.append(sheet.cell_value(row,col)) data.append(rd) text_list=['<?xml version="1.0" encoding="UTF-8"?>\n'] root = ET.Element("root") numbers = ET.SubElement(root,"numbers") numbers.tail = "\n" title=u""" <!-- 数字信息 --> """ numbers.text = title+json.dumps(data).replace("],","],\n")+u"\n" text_list.append(ET.tostring(root,encoding="utf-8")) with open("numbers.xml","w") as xf: xf.write("".join(text_list))
第 0020 题: 登陆中国联通网上营业厅 后选择「自助服务」 --> 「详单查询」,然后选择你要查询的时间段,点击「查询」按钮,查询结果页面的最下方,点击「导出」,就会生成类似于 2014年10月01日~2014年10月31日通话详单.xls 文件。写代码,对每月通话时间做个统计。
#coding:utf-8 import xlrd import re import time def calPhoneTime(data): hour,minute,second=0,0,0 match = re.findall(u"(\d+)",data) if len(match)==3: hour =int(match[0]) minute = int(match[1]) second = int(match[2]) elif len(match)==2: minute = int(match[0]) second = int(match[1]) else: second = int(match[0]) return hour,minute,second #下面匹配方式也可以 # for row in range(1,sheet.nrows): # data = sheet.cell_value(row,3) # match = re.findall(u"(\d+时){0,1}(\d+分){0,1}(\d+秒)",data)[0] # if match[0] and match[0].endswith(u"时"): # h = int(match[0].strip(u"时")) # hour = hour+h # if match[1] and match[1].endswith(u"分"): # m = int(match[1].strip(u"分")) # minute = minute+m # if match[2] and match[2].endswith(u"秒"): # s = int(match[2].strip(u"秒")) # second = second+s # print hour,minute,second def formatTime(hour,minute,second): if second>=60: m,second=divmod(second,60) minute = minute+m if minute>=60: h,minute=divmod(minute,60) hour = hour+h return "%s hour %s minute %s second"%(hour,minute,second) if __name__=="__main__": hour,minute,second=0,0,0 wb = xlrd.open_workbook(u"2018年12月语音通信.xls") #必须进行unicode,不然会报错,相当于:unicode("2018年12月语音通信.xls","utf-8") sheet = wb.sheet_by_index(0) start_time = time.mktime(time.strptime("2018-12-01","%Y-%m-%d")) #mktime返回浮点数,便于比较大小 end_time = time.mktime(time.strptime("2019-01-01","%Y-%m-%d")) for row in range(1,sheet.nrows): this_time = time.mktime(time.strptime(sheet.cell_value(row,2),"%Y-%m-%d %H:%M:%S")) if start_time<this_time and this_time<end_time: h,m,s = calPhoneTime(sheet.cell_value(row,3)) hour = hour+h minute = minute+m second = second+s phone_time = formatTime(hour,minute,second) print phone_time
第 0021 题: 通常,登陆某个网站或者 APP,需要使用用户名和密码。密码是如何加密后存储起来的呢?请使用 Python 对密码加密。
#coding:utf-8 import hmac import os import hashlib m_dict={"md5":hashlib.md5,"sha1":hashlib.sha1,"sha256":hashlib.sha256} def encrypt_passwd(password, salt=None): algo = "sha256" if salt==None: salt = os.urandom(8) #8个字节的随机数 if isinstance(password, unicode): password = password.encode('UTF-8') m = m_dict[algo] hash = hmac.new(salt,password,m).digest() return "%s$%s$%s"%(algo,salt,hash) def check_passwd(user_passwd,encrypt_passwd): algo,salt,hash = encrypt_passwd.split("$") m = m_dict[algo] return hash==hmac.new(salt,user_passwd,m).digest() if __name__=="__main__": old_passwd = raw_input("input password: ") encrypt_passwd = encrypt_passwd(old_passwd) new_passwd = raw_input("input password again: ") result = check_passwd(new_passwd,encrypt_passwd) print result #参考代码 # import os # from hashlib import sha256 # from hmac import HMAC # def encrypt_password(password, salt=None): # """Hash password on the fly.""" # if salt is None: # salt = os.urandom(8) # 64 bits. # assert 8 == len(salt) # assert isinstance(salt, str) # if isinstance(password, unicode): # password = password.encode('UTF-8') # assert isinstance(password, str) # result = password # for i in xrange(10): # result = HMAC(result, salt, sha256).digest() # return salt + result # hashed = encrypt_password('secret password') # def validate_password(hashed, input_password): # return hashed == encrypt_password(input_password, salt=hashed[:8]) # assert validate_password(hashed, 'secret password')
第 0022 题: iPhone 6、iPhone 6 Plus 早已上市开卖。请查看你写得 第 0005 题的代码是否可以复用。
见第0005题
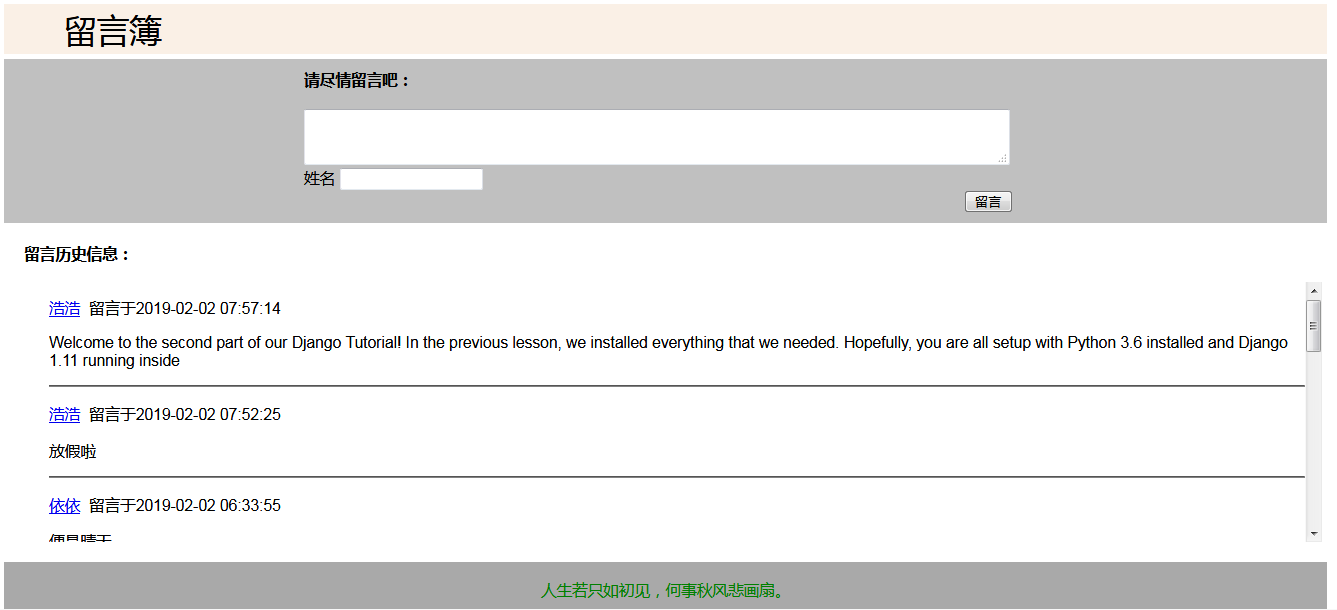
第 0023 题: 使用 Python 的 Web 框架,做一个 Web 版本 留言簿 应用。

使用django+mysql实现,代码和效果如下:
url路由和视图函数
"""MessageBoard URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/1.10/topics/http/urls/ Examples: Function views 1. Add an import: from my_app import views 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home') Class-based views 1. Add an import: from other_app.views import Home 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home') Including another URLconf 1. Import the include() function: from django.conf.urls import url, include 2. Add a URL to urlpatterns: url(r'^blog/', include('blog.urls')) """ from django.conf.urls import url from django.contrib import admin from MessageBox import views urlpatterns = [ url(r'^admin/', admin.site.urls), url(r"^index/", views.index) ]
#coding:utf-8 from django.shortcuts import render,HttpResponse,redirect from models import Message,UserInfo import json # Create your views here. def index(request): if request.method=="POST": username = request.POST.get("username") content = request.POST.get("content") users = UserInfo.objects.filter(username=username) if (not content) or (not username): return redirect("/index/") if not users: user = UserInfo.objects.create(username=username) else: user = users[0] message_obj = Message.objects.create(user=user,content=content) message={"create_time":message_obj.create_time.strftime("%Y-%m-%d %H:%M:%S")} #auto_now_add时间必须格式化后才能用json处理 #print message return HttpResponse(json.dumps(message)) messages = Message.objects.all().order_by("-nid")[0:10] #逆序排列,使最新的留言的排在最前面 return render(request,"index.html",locals())
数据模型:(注意数据库中文乱码问题)
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'blog', 'USER': 'root', 'PASSWORD': '', 'HOST': '', 'PORT': '', 'CHARSET':'utf8', 'COLLATION':'utf8_general_ci', #注意有中文时设置该utf8格式,同时建立数据库时:CREATE DATABASE mydb DEFAULT CHARACTER SET utf8 COLLATION utf8_general_ci; } }
#coding:utf-8 from __future__ import unicode_literals from django.db import models from django.contrib.auth.models import AbstractUser # Create your models here. class UserInfo(AbstractUser): def __str__(self): return self.username class Meta: verbose_name="用户" verbose_name_plural=verbose_name class Message(models.Model): nid = models.AutoField(primary_key=True) content=models.CharField(max_length=512) user = models.ForeignKey(to='UserInfo') create_time = models.DateTimeField(auto_now_add=True) def __str__(self): return self.nid class Meta: verbose_name="留言内容" verbose_name_plural=verbose_name
前端模板和样式
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>留言板</title> <link rel="stylesheet" type="text/css" href="/statics/css/layout.css"> </head> <body> <div id="header">留言簿</div> <div id="mbox"> <form> {% csrf_token %} <label><strong>请尽情留言吧:</strong></label><br/><br/> <textarea name="content" id="content"></textarea><br/> <label for="username">姓名</label> <input type="text" name="username" id="username"/> </form> <div id="bt"><button onclick="leaveMessage();">留言</button></div> </div> <div id="mcontent"> {% if messages %} <label><strong>留言历史信息:</strong></label><br/><br/> <div id="detail"> {% for message in messages %} <p><a href='#'>{{ message.user.username }}</a> 留言于<span>{{ message.create_time|date:"Y-m-d H:i:s" }}</span></p> <p>{{ message.content }}</p> <hr/> {% endfor %} </div> {% endif %} </div> <div id="footer"> <p>人生若只如初见,何事秋风悲画扇。</p> </div> <script type="text/javascript" src="/statics/js/jquery-3.3.1.js"></script> <script> function leaveMessage(){ var username = $("#username").val(); var content = $("#content").val(); $.ajax({ url:'/index/', method:"post", data:{username:username, content:content, csrfmiddlewaretoken: '{{ csrf_token }}'}, dataType:'json', success:function (data) { //console.log(data); $("#username").val(''); $("#content").val(''); var mes = "<p><a href='#'>"+username+"</a> 留言于<span>"+data.create_time+"</span></p>\n" + " <p>"+content+"</p>\n" + " <hr/>\n"; $("#detail").prepend(mes); } }); }; </script> </body> </html>
body{ margin:10px; font-size: 13px; ine-height: 1.2em; font-family: Helvetica Neue,Helvetica,PingFang SC,Hiragino Sans GB,Microsoft YaHei,Noto Sans CJK SC,WenQuanYi Micro Hei,Arial,sans-serif; } #header{ height:40px; padding:5px; padding-left: 60px; background-color:linen; font-size: 2.5em; } #mbox{ margin-top: 5px; background-color:silver; font-size:1.2em; padding:10px 300px; } #mbox textarea{ width: 700px; height:50px; } #mbox #bt{ padding-left: 660px; } #mcontent{ width:100%; font-size:1.2em; padding:20px; } #detail{ height:260px; overflow: auto; padding-left: 25px; margin-right: 25px; } #footer{ text-align: center; font-size: 1.2em; color: green; background-color: darkgrey; height:50px; padding-top: 2px; }
实现效果:
第 0024 题: 使用 Python 的 Web 框架,做一个 Web 版本 TodoList 应用。

使用django+mysql+bootstrap实现,代码和效果如下:
url路由和视图函数:
from django.conf.urls import url from django.contrib import admin from PlanList import views urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^todoList/', views.todoList), url(r'^addTask/', views.addTask), url(r'^login/', views.login), url(r'^logout/', views.logout), url(r'^register/', views.register), url(r'^deleteTask/(\d+)', views.deleteTask), url(r'^editTask/(\d+)', views.editTask), ]
#coding:utf-8 from django.contrib import auth from django.shortcuts import render,redirect import forms from .models import Task,User from pagination import Pagination # Create your views here. def login(request): result={'status': 0, 'msg': ''} if request.method=="POST": username = request.POST.get('username') passwd = request.POST.get('password') user = auth.authenticate(username=username,password=passwd) if user: auth.login(request,user) return redirect('/todoList/') else: result['msg'] = '用户名或密码错误!' result['status'] = 1 return render(request, 'login.html', {'result': result}) return render(request,'login.html',{'result': result}) def logout(request): auth.logout(request) return redirect('/login/') def register(request): result = {'status': 0, 'msg': ''} if request.method=="POST": form_obj = forms.UserForm(request.POST) if form_obj.is_valid(): form_obj.cleaned_data.pop('confirmPassword') User.objects.create_user(**form_obj.cleaned_data) return redirect('/login/') else: result['status'] = 1 result['msg'] = form_obj.errors return render(request, 'register.html', locals()) form_obj = forms.UserForm() return render(request,'register.html',locals()) def todoList(request): if not request.user.id: return redirect('/login/') title = request.GET.get('search', '') sort = request.GET.get('sort','') if sort=='': sort='deadline' tasks = Task.objects.filter(user_id=request.user.id).filter(title__contains=title).order_by(sort) current_page = int(request.GET.get('page', 1)) # 当前页码数 params = request.GET # get提交的参数 base_url = request.path # url路径 all_count = tasks.count() # 总数 pagination = Pagination(current_page, all_count, base_url, params, per_page_num=3, pager_count=3) tasks_list = tasks[pagination.start:pagination.end] return render(request,'list.html',locals()) def addTask(request): if request.method=='POST': taskForm = forms.TaskForm(request.POST) if taskForm.is_valid(): #print taskForm.cleaned_data Task.objects.create(user=request.user,**taskForm.cleaned_data) return render(request, 'pop.html') # 返回一个空页面(在其中关闭当前页面,并调用父页面的函数) taskForm = forms.TaskForm() return render(request,'addTask.html',locals()) def deleteTask(request,id): Task.objects.get(id=id).delete() return redirect('/todoList/') def editTask(request,id): if request.method=="POST": title = request.POST.get('title') content = request.POST.get('content') deadline = request.POST.get('deadline') Task.objects.filter(id=id).update(title=title,content=content,deadline=deadline) return redirect('/todoList/') task = Task.objects.get(id=id) return render(request, 'editTask.html', locals())
#coding:utf-8 from django import forms from django.core.exceptions import ValidationError import models class TaskForm(forms.Form): title = forms.CharField( label='任务标题', max_length=64, widget=forms.widgets.TextInput(attrs={'class':'form-control'}) ) content = forms.CharField( label='详细内容', widget=forms.widgets.Textarea(attrs={'class': 'form-control'}) ) deadline = forms.DateTimeField() #不作为前端模板使用(改用datetimepicker插件),后端数据处理时使用 class UserForm(forms.Form): username = forms.CharField( max_length=16, label='用户名', error_messages={ 'max_length':'用户名最长16位', 'required':'用户名不能为空', }, widget=forms.widgets.TextInput( attrs={'class':'form-control'} ), ) password = forms.CharField( min_length=6, label='密码', error_messages={ 'min_length':'密码至少6位', 'required':'密码不能为空', }, widget=forms.widgets.PasswordInput( attrs={'class':'form-control'}, ), ) confirmPassword = forms.CharField( min_length=6, label='确认密码', error_messages={ 'min_length':'确认密码至少6位', 'required':'确认密码不能为空', }, widget=forms.widgets.PasswordInput( attrs={'class':'form-control'}, ), ) phone = forms.CharField( label='手机号', max_length=11, widget=forms.widgets.TextInput( attrs={'class':'form-control'}, ), error_messages={ 'invalid':'手机号格式不正确', 'max_length': '手机号最长11位', 'required':'手机号不能为空', }, ) #重写用户名钩子函数,验证用户名是否已经存在 def clean_username(self): username = self.cleaned_data.get('username') is_exist = models.User.objects.filter(username=username) if is_exist: self.add_error('username',ValidationError('用户名已注册')) else: return username #重写邮箱钩子函数,验证邮箱是否已经存在 def clean_phone(self): phone = self.cleaned_data.get('phone') is_exist = models.User.objects.filter(phone=phone) if is_exist: self.add_error('phone',ValidationError('手机号已被注册')) else: return phone #重写form全局钩子函数,判断两次密码一致 def clean(self): password = self.cleaned_data.get('password') confirmPassword = self.cleaned_data.get('confirmPassword') if confirmPassword and password != confirmPassword: self.add_error('confirmPassword', ValidationError('两次密码不一致')) else: return self.cleaned_data #重写后必须返回cleaned_data数据
#coding:utf-8 class Pagination(object): def __init__(self, current_page, all_count, base_url,params, per_page_num=8, pager_count=11, ): """ 封装分页相关数据 :param current_page: 当前页 :param all_count: 数据库中的数据总条数 :param per_page_num: 每页显示的数据条数 :param base_url: 分页中显示的URL前缀 :param params: url中提交过来的数据 :param pager_count: 最多显示的页码个数 """ try: current_page = int(current_page) except Exception as e: current_page = 1 if current_page < 1: current_page = 1 self.current_page = current_page self.all_count = all_count self.per_page_num = per_page_num self.base_url = base_url # 总页码 all_pager, tmp = divmod(all_count, per_page_num) if tmp: all_pager += 1 self.all_pager = all_pager self.pager_count = pager_count # 最多显示页码数 self.pager_count_half = int((pager_count - 1) / 2) import copy params = copy.deepcopy(params) params._mutable = True self.params = params # self.params : {"page":77,"title":"python","nid":1} @property def start(self): return (self.current_page - 1) * self.per_page_num @property def end(self): return self.current_page * self.per_page_num def page_html(self): # 如果总页码 < 11个: if self.all_pager <= self.pager_count: pager_start = 1 pager_end = self.all_pager + 1 # 总页码 > 11 else: # 当前页如果<=页面上最多显示(11-1)/2个页码 if self.current_page <= self.pager_count_half: pager_start = 1 pager_end = self.pager_count + 1 # 当前页大于5 else: # 页码翻到最后 if (self.current_page + self.pager_count_half) > self.all_pager: pager_start = self.all_pager - self.pager_count + 1 pager_end = self.all_pager + 1 else: pager_start = self.current_page - self.pager_count_half pager_end = self.current_page + self.pager_count_half + 1 page_html_list = [] self.params["page"] = 1 first_page =u'<li><a href="%s?%s">首页</a></li>' % (self.base_url, self.params.urlencode(),) #有汉字,不用u'',会报错? page_html_list.append(first_page) if self.current_page <= 1: prev_page = u'<li class="disabled"><a href="#">上一页</a></li>' else: self.params["page"] = self.current_page - 1 prev_page = u'<li><a href="%s?%s">上一页</a></li>' % (self.base_url, self.params.urlencode(),) page_html_list.append(prev_page) for i in range(pager_start, pager_end): # self.params : {"page":77,"title":"python","nid":1} self.params["page"] = i # {"page":72,"title":"python","nid":1} if i == self.current_page: temp = '<li class="active"><a href="%s?%s">%s</a></li>' % (self.base_url, self.params.urlencode(), i,) else: temp = '<li><a href="%s?%s">%s</a></li>' % (self.base_url, self.params.urlencode(), i,) page_html_list.append(temp) if self.current_page >= self.all_pager: next_page = u'<li class="disabled"><a href="#">下一页</a></li>' else: self.params["page"] = self.current_page + 1 next_page =u'<li><a href="%s?%s">下一页</a></li>' % (self.base_url, self.params.urlencode(),) page_html_list.append(next_page) self.params["page"] = self.all_pager last_page =u'<li><a href="%s?%s">尾页</a></li>' % (self.base_url, self.params.urlencode(),) page_html_list.append(last_page) return ''.join(page_html_list)
数据模型:
#coding:utf-8 from __future__ import unicode_literals from django.db import models from django.contrib.auth.models import AbstractUser # Create your models here. class User(AbstractUser): phone = models.CharField(max_length=11) def __str__(self): return self.username class Meta: verbose_name = '用户' verbose_name_plural=verbose_name class Task(models.Model): title = models.CharField(max_length=64) user = models.ForeignKey(to='User') create_date = models.DateTimeField(auto_now_add=True) content = models.TextField() deadline = models.DateTimeField() def __str__(self): return self.title class Meta: verbose_name = '任务' verbose_name_plural=verbose_name
""" Django settings for ToDoList project. Generated by 'django-admin startproject' using Django 1.10.8. For more information on this file, see https://docs.djangoproject.com/en/1.10/topics/settings/ For the full list of settings and their values, see https://docs.djangoproject.com/en/1.10/ref/settings/ """ import os # Build paths inside the project like this: os.path.join(BASE_DIR, ...) BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # Quick-start development settings - unsuitable for production # See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/ # SECURITY WARNING: keep the secret key used in production secret! SECRET_KEY = '5%v3hfy*+thu-in&f__ypd43y1lw&poky&+-=8=es4!mrnp=pa' # SECURITY WARNING: don't run with debug turned on in production! DEBUG = True ALLOWED_HOSTS = [] # Application definition INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'PlanList.apps.PlanlistConfig', ] MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] ROOT_URLCONF = 'ToDoList.urls' TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [os.path.join(BASE_DIR, 'templates')] , 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ] WSGI_APPLICATION = 'ToDoList.wsgi.application' # Database # https://docs.djangoproject.com/en/1.10/ref/settings/#databases # DATABASES = { # 'default': { # 'ENGINE': 'django.db.backends.sqlite3', # 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), # } # } DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME':'planList', 'USER':'root', 'PASSWORD':'', 'HOST':'', 'PORT':'', 'CHARSET':'utf8', 'COLLATION':'utf8_general_ci', } } # Password validation # https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators AUTH_PASSWORD_VALIDATORS = [ { 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', }, { 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', }, { 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', }, { 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', }, ] # Internationalization # https://docs.djangoproject.com/en/1.10/topics/i18n/ LANGUAGE_CODE = 'en-us' TIME_ZONE = 'UTC' USE_I18N = True USE_L10N = True USE_TZ = True # Static files (CSS, JavaScript, Images) # https://docs.djangoproject.com/en/1.10/howto/static-files/ STATIC_URL = '/static/' STATICFILES_DIRS = [os.path.join(BASE_DIR,'static')] AUTH_USER_MODEL = 'PlanList.User'
前端模板和样式:
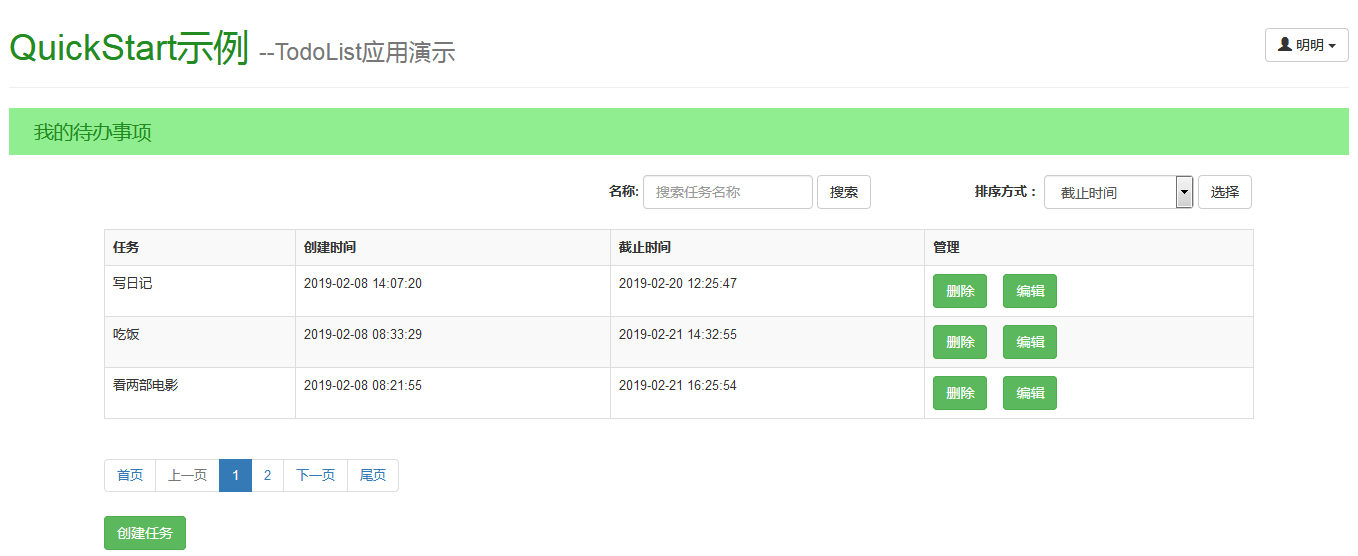
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>ToDoList</title> <link rel="stylesheet" type="text/css" href="/static/bootstrap/css/bootstrap.min.css"> <style> body{ margin:10px; font-size: 13px; ine-height: 1.2em; font-family: Helvetica Neue,Helvetica,PingFang SC,Hiragino Sans GB,Microsoft YaHei,Noto Sans CJK SC,WenQuanYi Micro Hei,Arial,sans-serif; } .page-header h1{ color:forestgreen; } #task{ padding: 10px 25px; font-size:1.5em; background-color:lightgreen; color:forestgreen; } form{ padding-left: 580px; margin: 20px; } #sort{ margin-left: 100px; } #taskTable{ margin:10px 95px 10px 95px; } </style> </head> <body> <div class="dropdown pull-right"> <button class="btn btn-default dropdown-toggle" type="button" id="dropdownMenu1" data-toggle="dropdown" aria-haspopup="true" aria-expanded="true"> <span class="glyphicon glyphicon-user"></span> {{ request.user.username }} <span class="caret"></span> </button> <ul class="dropdown-menu" aria-labelledby="dropdownMenu1"> <li><a href="/logout/">退出</a></li> </ul> </div> <div class="page-header"> <h1>QuickStart示例 <small>--TodoList应用演示</small></h1> </div> <div id="task">我的待办事项</div> <form class="form-inline"> <div class="form-group"> <label for="taskName">名称:</label> <input type="text" class="form-control" id="taskName" name="search" placeholder="搜索任务名称"> </div> <button type="submit" class="btn btn-default">搜索</button> <label id="sort">排序方式:</label> <div class="form-group"> <select class="form-control" style="width:150px;" name="sort"> <option value="create_date">创建时间</option> <option value="deadline" selected="selected">截止时间</option> </select> </div> <button type="submit" class="btn btn-default">选择</button> </form> <div id="taskTable"> <div> <table class="table table-bordered table-striped"> <tr> <th>任务</th> <th>创建时间</th> <th>截止时间</th> <th>管理</th> </tr> {% for task in tasks_list %} <tr> <td>{{ task.title }}</td> <td>{{ task.create_date|date:"Y-m-d H:i:s" }}</td> <td>{{ task.deadline|date:"Y-m-d H:i:s" }}</td> <td><a href="/deleteTask/{{ task.id }}"><button type="button" class='btn btn-success'>删除</button></a> <a href="/editTask/{{ task.id }}"><button type="button" class='btn btn-success'>编辑</button></a> </td> </tr> {% endfor %} </table> </div> <div> <!--分页标签--> <nav aria-label="Page navigation"> <ul class="pagination">{{ pagination.page_html|safe }}</ul> </nav> </div> <button class="btn btn-success" onclick="createTask();">创建任务</button> </div> <hr/> <script type="text/javascript" src="/static/jquery-3.3.1.js"></script> <script type="text/javascript" src="/static/bootstrap/js/bootstrap.min.js"></script> <script> window.opener=null; function createTask(){ window.open("/addTask/","","width=800,height=600,top=100,left=100"); } function refresh(){ window.location.href='/todoList/'; } </script> </body> </html>
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>登陆</title> <link rel="stylesheet" type="text/css" href="/static/bootstrap/css/bootstrap.min.css"> </head> <body> <h3 style="margin-top: 150px; text-align: center">欢迎登陆我的任务列表</h3> <br/><br/> <form class="form-horizontal" action="/login/" method="post"> {% csrf_token %} <div class="form-group"> <label for="inputUsername" class="col-sm-4 control-label">用户名</label> <div class="col-sm-4"> <input type="text" class="form-control" id="inputUsername" placeholder="Username" name="username"> </div> </div> <div class="form-group"> <label for="inputPassword" class="col-sm-4 control-label">密码</label> <div class="col-sm-4"> <input type="password" class="form-control" id="inputPassword" placeholder="Password" name="password"> </div> </div> <div class="form-group has-error"> <div class="col-sm-offset-4 col-sm-8"> {% if result.status %} <span class="help-block">{{ result.msg }}</span> {% endif %} </div> </div> <div class="form-group"> <div class="col-sm-offset-5"> <button type="submit" style="margin-left: 30px;" class="btn btn-info">登陆</button> <a class="btn btn-info" style="margin-left: 20px;" href="/register/">注册</a> </div> </div> </form> </body> </html>
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>注册</title> <link rel="stylesheet" type="text/css" href="/static/bootstrap/css/bootstrap.min.css"> </head> <body> <div class="container"> <h3 style="margin-top: 100px; text-align: center">注册我的任务列表</h3> <br/><br/> <div class="row"> <div class="col-md-6 col-md-offset-3 "> <form class="form-horizontal" action="/register/" method="post" enctype="multipart/form-data"> {% csrf_token %} <div class="form-group"> <label for="{{ form_obj.username.id_for_label }}" class="col-sm-2 control-label">{{ form_obj.username.label }}</label> <div class="col-sm-8"> {{ form_obj.username }} <div class="has-error"> <span class="help-block">{{ form_obj.username.errors.0 }}</span> </div> </div> </div> <div class="form-group"> <label for="{{ form_obj.password.id_for_label }}" class="col-sm-2 control-label">{{ form_obj.password.label }}</label> <div class="col-sm-8"> {{ form_obj.password }} <div class="has-error"> <span class="help-block">{{ form_obj.password.errors.0 }}</span> </div> </div> </div> <div class="form-group"> <label for="{{ form_obj.confirmPassword.id_for_label }}" class="col-sm-2 control-label">{{ form_obj.confirmPassword.label }}</label> <div class="col-sm-8"> {{ form_obj.confirmPassword }} <div class="has-error"> <span class="help-block">{{ form_obj.confirmPassword.errors.0 }}</span> </div> </div> </div> <div class="form-group"> <label for="{{ form_obj.phone.id_for_label }}" class="col-sm-2 control-label">{{ form_obj.phone.label }}</label> <div class="col-sm-8"> {{ form_obj.phone }} <div class="has-error"> <span class="help-block">{{ form_obj.phone.errors.0 }}</span> </div> </div> </div> <div class="form-group has-error"> <div class="col-sm-offset-4 col-sm-8"> {% if result.status %} <span class="help-block">{{ result.msg }}</span> {% endif %} </div> </div> <div class="form-group"> <div class="col-sm-offset-4 col-sm-4"> <button type="submit" class="btn btn-info">注册</button> <a class="btn btn-info" style="margin-left: 20px;" href="/login/">登陆</a> </div> </div> </form> </div> </div> </div> </body> </html>
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>添加任务</title> <link rel="stylesheet" type="text/css" href="/static/bootstrap/css/bootstrap.min.css"> <link rel="stylesheet" type="text/css" href="/static/datetimepicker/bootstrap-datetimepicker.min.css"> </head> <body> <h4 style="margin-top: 60px; text-align: center">添加任务</h4> <br/> <div class="container"> <div class="row" > <div class="col-md-6 col-md-offset-3 "> <form class="form-horizontal" method="post"> {% csrf_token %} <div class="form-group"> <label for="{{ taskForm.title.id_for_label }}" class="col-sm-2 control-label">{{ taskForm.title.label }}</label> <div class="col-sm-8"> {{ taskForm.title }} </div> </div> <div class="form-group"> <label for="{{ taskForm.content.id_for_label }}" class="col-sm-2 control-label">{{ taskForm.content.label }}</label> <div class="col-sm-8"> {{ taskForm.content }} </div> </div> <div class="form-group"> <label for="datetimepicker" class="col-sm-2 control-label">截止日期</label> <div class="col-sm-8"> <div class='input-group'> <input type='text' class="form-control" id='datetimepicker' name="deadline" placeholder="截止日期"/> <span class="input-group-addon"> <span class="glyphicon glyphicon-calendar"></span> </span> </div> </div> </div> <div class="form-group"> <div class="col-sm-offset-8 col-sm-4"> <button type="submit" class="btn btn-info" id="submit">提交</button> </div> </div> </form> </div> </div> </div> <script type="text/javascript" src="/static/jquery-3.3.1.js"></script> <script type="text/javascript" src="/static/bootstrap/js/bootstrap.min.js"></script> <script src="/static/datetimepicker/bootstrap-datetimepicker.min.js"></script> <script src="/static/datetimepicker/bootstrap-datetimepicker.zh-CN.js"></script> <script> //日历插件, 官网地址:https://eonasdan.github.io/bootstrap-datetimepicker/ $('#datetimepicker').datetimepicker({ minView: "hour", //设置小时视图 language: "zh-CN", sideBySide: true, // 同时选择日期和时间,月视图可以里不用设 format: 'yyyy-mm-dd hh:ii:ss', //设置日期显示格式 startDate: new Date(), //设置开始时间,早于此刻的日期不能选择 bootcssVer: 3, //显示向左,向右的箭头 autoclose: true, //选择日期后自动关闭 todayHighlight: true, todayBtn: true, }).on('changeDate', change_date); function change_date(e) { window.choose_date = e.date.format("yyyy-MM-dd hh:mm:ss"); //location.href = "/order_list/?order_date=" + window.choose_date; }; Date.prototype.format = function(fmt){ var o = { "M+" : this.getMonth()+1, //月份 "d+" : this.getDate(), //日 "h+" : this.getHours(), //小时 "m+" : this.getMinutes(), //分 "s+" : this.getSeconds(), //秒 "q+" : Math.floor((this.getMonth()+3)/3), //季度 "S" : this.getMilliseconds() //毫秒 }; if(/(y+)/.test(fmt)) fmt=fmt.replace(RegExp.$1, (this.getFullYear()+"").substr(4 - RegExp.$1.length)); for(var k in o) if(new RegExp("("+ k +")").test(fmt)) fmt = fmt.replace(RegExp.$1, (RegExp.$1.length==1) ? (o[k]) : (("00"+ o[k]).substr((""+ o[k]).length))); return fmt; } </script> </body> </html>
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>Title</title> </head> <body> <script> window.opener.refresh(); window.close(); </script> </body> </html>
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>编辑任务</title> <link rel="stylesheet" type="text/css" href="/static/bootstrap/css/bootstrap.min.css"> <link rel="stylesheet" type="text/css" href="/static/datetimepicker/bootstrap-datetimepicker.min.css"> </head> <body> <h3 style="margin-top: 160px; text-align: center">编辑任务</h3> <br/><br/> <div class="container"> <div class="row" > <div class="col-md-8 col-md-offset-2 "> <form class="form-horizontal" action="/editTask/{{ task.id }}/" method="post"> {% csrf_token %} <div class="form-group"> <label for="title" class="col-sm-2 control-label">任务标题</label> <div class="col-sm-8"> <input class="form-control" name="title" id="title" value="{{ task.title }}"/> </div> </div> <div class="form-group"> <label for="content" class="col-sm-2 control-label">详细内容</label> <div class="col-sm-8"> <textarea class="form-control" name='content' id="content">{{ task.content }}</textarea> </div> </div> <div class="form-group"> <label for="datetimepicker" class="col-sm-2 control-label">截止日期</label> <div class="col-sm-8"> <div class='input-group'> <input type='text' class="form-control" id='datetimepicker' name="deadline" value="{{ task.deadline|date:'Y-m-d H:i:s'}}" /> <span class="input-group-addon"> <span class="glyphicon glyphicon-calendar"></span> </span> </div> </div> </div> <div class="form-group"> <div class="col-sm-offset-9 col-sm-3"> <button type="submit" class="btn btn-info" id="submit">提交</button> </div> </div> </form> </div> </div> </div> <script type="text/javascript" src="/static/jquery-3.3.1.js"></script> <script type="text/javascript" src="/static/bootstrap/js/bootstrap.min.js"></script> <script src="/static/datetimepicker/bootstrap-datetimepicker.min.js"></script> <script src="/static/datetimepicker/bootstrap-datetimepicker.zh-CN.js"></script> <script> //日历插件, 官网地址:https://eonasdan.github.io/bootstrap-datetimepicker/ $('#datetimepicker').datetimepicker({ minView: "hour", //设置小时视图 language: "zh-CN", sideBySide: true, // 同时选择日期和时间,月视图可以里不用设 format: 'yyyy-mm-dd hh:ii:ss', //设置日期显示格式 startDate: new Date(), //设置开始时间,早于此刻的日期不能选择 bootcssVer: 3, //显示向左,向右的箭头 autoclose: true, //选择日期后自动关闭 todayHighlight: true, todayBtn: true, }).on('changeDate', change_date); function change_date(e) { window.choose_date = e.date.format("yyyy-MM-dd hh:mm:ss"); //location.href = "/order_list/?order_date=" + window.choose_date; }; Date.prototype.format = function(fmt){ var o = { "M+" : this.getMonth()+1, //月份 "d+" : this.getDate(), //日 "h+" : this.getHours(), //小时 "m+" : this.getMinutes(), //分 "s+" : this.getSeconds(), //秒 "q+" : Math.floor((this.getMonth()+3)/3), //季度 "S" : this.getMilliseconds() //毫秒 }; if(/(y+)/.test(fmt)) fmt=fmt.replace(RegExp.$1, (this.getFullYear()+"").substr(4 - RegExp.$1.length)); for(var k in o) if(new RegExp("("+ k +")").test(fmt)) fmt = fmt.replace(RegExp.$1, (RegExp.$1.length==1) ? (o[k]) : (("00"+ o[k]).substr((""+ o[k]).length))); return fmt; } </script> </body> </html>
实现效果:
第 0025 题: 使用 Python 实现:对着电脑吼一声,自动打开浏览器中的默认网站。
例如,对着笔记本电脑吼一声“百度”,浏览器自动打开百度首页。
关键字:Speech to Text
参考思路:
1:获取电脑录音-->WAV文件
python record wav
2:录音文件-->文本
STT: Speech to Text
STT API Google API
3:文本-->电脑命令
简单折腾了下,谷歌语音识别API调用时失败了。。。
1,获取电脑录音并保存为wav文件
#coding:utf-8 #pyaudio模块文档 http://people.csail.mit.edu/hubert/pyaudio/ #https://stackoverflow.com/questions/892199/detect-record-audio-in-python #https://www.cnblogs.com/hyb1/articles/3048756.html #录音,保存为wav格式文件 import pyaudio import wave from array import array from sys import byteorder from struct import pack CHUNK = 1024 FORMAT = pyaudio.paInt16 CHANNELS = 2 RATE = 44100 RECORD_SECONDS = 5 WAVE_OUTPUT_FILENAME = "output.wav" THRESHOLD=500 def is_silent(snd_data): "Returns 'True' if below the 'silent' threshold" return max(snd_data) < THRESHOLD def normalize(snd_data): "Average the volume out" MAXIMUM = 16384 times = float(MAXIMUM)/max(abs(i) for i in snd_data) r = array('h') for i in snd_data: r.append(int(i*times)) return r def trim(snd_data): "Trim the blank spots at the start and end" def _trim(snd_data): snd_started = False r = array('h') for i in snd_data: if not snd_started and abs(i)>THRESHOLD: snd_started = True r.append(i) elif snd_started: r.append(i) return r # Trim to the left snd_data = _trim(snd_data) # Trim to the right snd_data.reverse() snd_data = _trim(snd_data) snd_data.reverse() return snd_data def add_silence(snd_data, seconds): "Add silence to the start and end of 'snd_data' of length 'seconds' (float)" r = array('h', [0 for i in xrange(int(seconds*RATE))]) r.extend(snd_data) r.extend([0 for i in xrange(int(seconds*RATE))]) return r def record(): p = pyaudio.PyAudio() stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK) print("* recording") r = array("h") num_silent = 0 snd_started = False while True: snd_data = array("h",stream.read(CHUNK)) if byteorder=="big": snd_data.byteswap() r.extend(snd_data) silent = is_silent(snd_data) print silent if silent and snd_started: num_silent += 1 print num_silent elif not silent and not snd_started: snd_started = True if snd_started and num_silent > 30: break print("* done recording") sample_width = p.get_sample_size(FORMAT) stream.stop_stream() stream.close() p.terminate() r = normalize(r) r = trim(r) r = add_silence(r, 0.5) return sample_width, r # for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): # data = stream.read(CHUNK) # print type(data) # frames.append(data) if __name__=="__main__": print("please speak a word into the microphone") sample_width,data = record() data = pack('<' + ('h'*len(data)), *data) wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb') wf.setnchannels(CHANNELS) wf.setsampwidth(sample_width) wf.setframerate(RATE) wf.writeframes(data) wf.close()
2,调用谷歌语音识别API,返回403.。。。。,还有待研究
#coding:utf-8 #谷歌语音识别API,参考http://blog.laobubu.net/archivers/google-speech-api-pt2 #谷歌语音识别API官网教程:https://cloud.google.com/speech-to-text/docs/quickstart-protocol (得FQ) import requests response = requests.post(url="https://www.google.com/speech-api/v2/recognize?lang=en-us&key=AIzaSyAQgb", headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1", "Content-Type":"audio/x-flac; rate=16000"}, files={"file":open("hello.flac","rb",encoding="utf-8")} #key=AIzaSyAQgb,需要去google cloud注册申请,这个key已不能用 ) print(response)
3,文本转电脑命令
#coding:utf-8 #将文字转化为电脑命令 import os command ={"百度":"https://www.baidu.com","新浪":"https://www.sina.com","网易":"https://www.163.com/"} if __name__=="__main__": text = raw_input("please input: ") text_en = text.decode("gbk").encode("utf-8") if text_en in command: url = command[text_en] #windows命令行输入为gbk格式 else: url="https://www.baidu.com" os.system('"D:\\firefox\\firefox.exe" %s'%url) #火狐浏览器打开url #os.system('"C:\\Program Files\\Internet Explorer\\iexplore.exe" %s'%url) #ie浏览器
