58同城南京品牌公馆数据爬取
做一个租房信息的网站,要爬取58同城上南京品牌公馆的房源信息,因为数字被重新编码了,折腾了一天,记录一下整个过程,留着后面使用。
1,网页分析和字体文件反爬
简单看了下url(https://nj.58.com/pinpaigongyu/pn/1/),比较简单,替换下网址中页码数,就可以一直翻页并进行爬取。分析了下源代码需要爬取的信息,如下图所示,有一些怪异的汉字,刚开始以为是编码问题,后来看了下爬取下来的网页,发现是数字被替换了,应该是有特殊的字体文件。

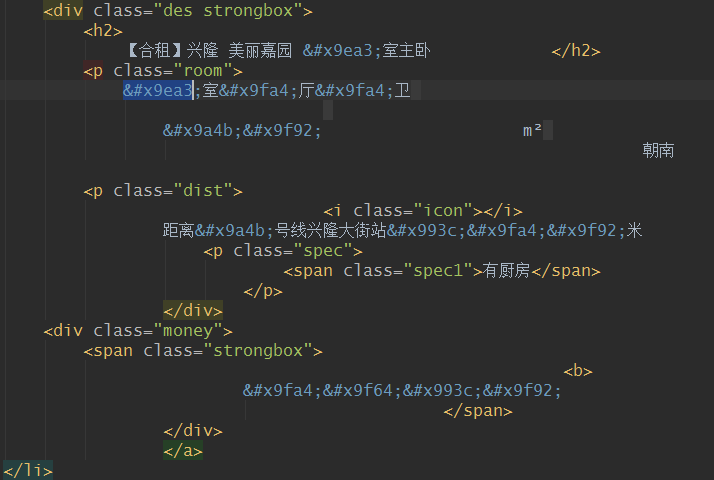
在script标签中找了一会,发现了下面的js代码,看到font-face和fangchan-secret,应该就是相应的字体文件,base64后面的内容即为base64加密后的字体文件信息,可以进行正则匹配提取,然后解码写入字体文件,相应代码如下。

import requests
import re
from fontTools.ttLib import TTFont
#下载字体文件
url="https://nj.58.com/pinpaigongyu/pn/{page}/" response = requests.get(url=url.format(page=1),headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'}) font_base64 = re.findall("base64,(AA.*AAAA)", response.text)[0] # 找到base64编码的字体格式文件 font = base64.b64decode(font_base64) with open('58font2.ttf', 'wb') as tf: tf.write(font)
font_object = TTFont('58font2.ttf')
font_object.saveXML('58font2.xml')
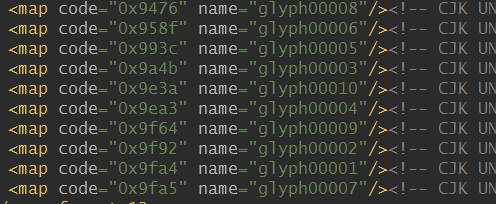
利用FontCreator查看了下保存的字体文件58font2.ttf,信息如下,共十一个对应表,第一个为空,不起作用,后面分别是数字和对应的字体编码。

然后看了下58font2.xml的内容,如下所示,结合上面的图,可以发现相应的对应关系如下: uni9476(0x9476)和glyph00008都对应着数字7,即对每一个glyph0000x对应数字x-1
因此只需要将下载的网页中的 (麣室龤厅龤卫 )乱码内容替换为相应的数字即可,需要运用到fontTools模块,具体步骤如下:
1,利用fontTools模块解析出对应的编码转换表(convert_dict数据如下:{40611: 'glyph00004', 40804: 'glyph00009', 40869: 'glyph00010'......},其中40611即为0x9ea3对应的十进制数)
2,将麣等十个字体编码进行拼接,组成一个正则pattern,对下载的网页进行匹配搜索
3,将匹配到的字体编码,通过编码转换表替换成数字。
对应代码如下:
def convertNumber(html_page): base_fonts = ['uni9FA4', 'uni9F92', 'uni9A4B', 'uni9EA3', 'uni993C', 'uni958F', 'uni9FA5', 'uni9476', 'uni9F64', 'uni9E3A'] base_fonts2 = ['&#x' + x[3:].lower() + ';' for x in base_fonts] # 构造成 鸺 的形式 pattern = '(' + '|'.join(base_fonts2) + ')' #拼接上面十个字体编码 font_base64 = re.findall("base64,(AA.*AAAA)", response.text)[0] # 找到base64编码的字体格式文件 font = base64.b64decode(font_base64) with open('58font2.ttf', 'wb') as tf: tf.write(font) onlinefont = TTFont('58font2.ttf') convert_dict = onlinefont['cmap'].tables[0].ttFont.tables['cmap'].tables[0].cmap # convert_dict数据如下:{40611: 'glyph00004', 40804: 'glyph00009', 40869: 'glyph00010', 39499: 'glyph00003' new_page = re.sub(pattern, lambda x: getNumber(x.group(),convert_dict), html_page) return new_page def getNumber(g,convert_dict): key = int(g[3:7], 16) # '麣',截取后四位十六进制数字,转换为十进制数,即为上面字典convert_dict中的键 number = int(convert_dict[key][-2:]) - 1 # glyph00009代表数字8, glyph00008代表数字7,依次类推 return str(number)
2,爬取网页
字体文件弄清楚后剩下的内容就很简单了,注意下爬取时两次间隔时间,必须大于5秒,否则会要求手势验证码。另外对于爬虫停止爬取的条件,我设置了匹配不到爬取信息和网页页码数小于600,最后发现实际上只有170页。爬取数据并存入数据库,完整代码如下:


#coding:utf-8 import requests from lxml import html import csv import re from fontTools.ttLib import TTFont import base64 import MySQLdb import time from download import get_user_agent def download(url,headers=None,cookies=None,proxies=None,num_retries=3): #支持user-agent和proxy #proxies = {"http": "http://10.10.1.10:3128", "https": "http://10.10.1.10:1080",} response=requests.get(url,headers=headers,cookies=cookies,proxies=proxies) if response.status_code and 500<=response.status_code<600: # 出现服务器端错误时重试三次 if num_retries > 0: response = download(url,user_agent,proxies,num_retries-1) return response def convertNumber(html_page): base_fonts = ['uni9FA4', 'uni9F92', 'uni9A4B', 'uni9EA3', 'uni993C', 'uni958F', 'uni9FA5', 'uni9476', 'uni9F64', 'uni9E3A'] base_fonts2 = ['&#x' + x[3:].lower() + ';' for x in base_fonts] # 构造成 鸺 的形式 pattern = '(' + '|'.join(base_fonts2) + ')' font_base64 = re.findall("base64,(AA.*AAAA)", response.text)[0] # 找到base64编码的字体格式文件 font = base64.b64decode(font_base64) with open('58font2.ttf', 'wb') as tf: tf.write(font) onlinefont = TTFont('58font2.ttf') convert_dict = onlinefont['cmap'].tables[0].ttFont.tables['cmap'].tables[0].cmap # convert_dict数据如下:{40611: 'glyph00004', 40804: 'glyph00009', 40869: 'glyph00010', 39499: 'glyph00003' new_page = re.sub(pattern, lambda x: getNumber(x.group(),convert_dict), html_page) return new_page def getNumber(g,convert_dict): key = int(g[3:7], 16) # '麣',截取后四位十六进制数字,转换为十进制数,即为上面字典convert_dict中的键 number = int(convert_dict[key][-2:]) - 1 # glyph00009代表数字8, glyph00008代表数字7,依次类推 return str(number) def getLocation(title): desc = title.split() if u'寓' in desc[0]or u'社区' in desc[0]: location = desc[0].strip(u'【整租】【合租】')+desc[2] else: location=desc[1] return location def getAveragePrice(price): price_range = price.split('-') if len(price_range)==2: average_price = (int(price_range[0])+int(price_range[1]))/2 else: average_price=price return average_price if __name__ == '__main__': conn = MySQLdb.connect(host='localhost',user='root',passwd='',db='renthouse',charset='utf8',port=3306) #不要写成utf-8 cursor = conn.cursor() cursor.execute("""CREATE TABLE IF NOT EXISTS 58house( id INT PRIMARY KEY AUTO_INCREMENT NOT NULL, title VARCHAR(128) NOT NULL, location VARCHAR(128) NOT NULL, room VARCHAR(128) NOT NULL , price VARCHAR(64) NOT NULL , average_price VARCHAR(64) NOT NULL , url VARCHAR(768) NOT NULL);""") conn.commit() seed_url = "https://nj.58.com/pinpaigongyu/pn/{page}/" page = 0 flag=True while flag: try: user_agent = get_user_agent() headers={"User_Agent":user_agent} page = page+1 current_url=seed_url.format(page=page) print current_url response = download(url=current_url,headers=headers) new_page = convertNumber(response.text) tree = html.fromstring(new_page) li_tags = tree.xpath('//ul[@class="list"]/li') #print li_tags if (not li_tags) or page>600: print page flag=False for li_tag in li_tags: title = li_tag.xpath('.//div[@class="des strongbox"]/h2/text()')[0].strip() room = li_tag.xpath('.//p[@class="room"]/text()')[0].replace('\r\n', '').replace(r' ', '') price = li_tag.xpath('.//div[@class="money"]//b/text()')[0].strip().replace('\r\n', '').replace(r' ', '') url = li_tag.xpath('./a[@href]')[0].attrib['href'].strip() location = getLocation(title) average_price = getAveragePrice(price) cursor.execute("""INSERT INTO 58house(title,location,room,price,average_price,url) VALUES('%s','%s','%s','%s','%s','%s');"""%(title,location,room,price,average_price,url)) conn.commit() except Exception as e: print "download page %s error: %s"%(page,e) time.sleep(5) # 停顿时间小于5s时会要求图形验证码 conn.close()
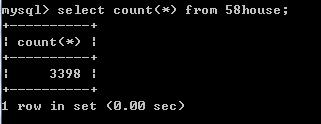
十多分钟后就爬取完毕了,总共170页,爬取第171页时失败,数据库中共存入了3398条数据。