
(四)爬虫之动态网页
对于网页上的有些内容,需要进行一定的交互操作,才能拿到相应的数据,例如常见的ajax请求等。为了抓取ajax请求的结果,可以通过ajax请求的url,抓取返回结果,也可以利用Selenium模块来模拟网页ajax。简单记录下一段学习过程。
1.问题分析
如下面我爱我家的网页中(https://wh.5i5j.com/ershoufang/),当在搜索框中输入“保”时,后台会自动发送ajax请求,拿到所有包含“保”字的小区名字。
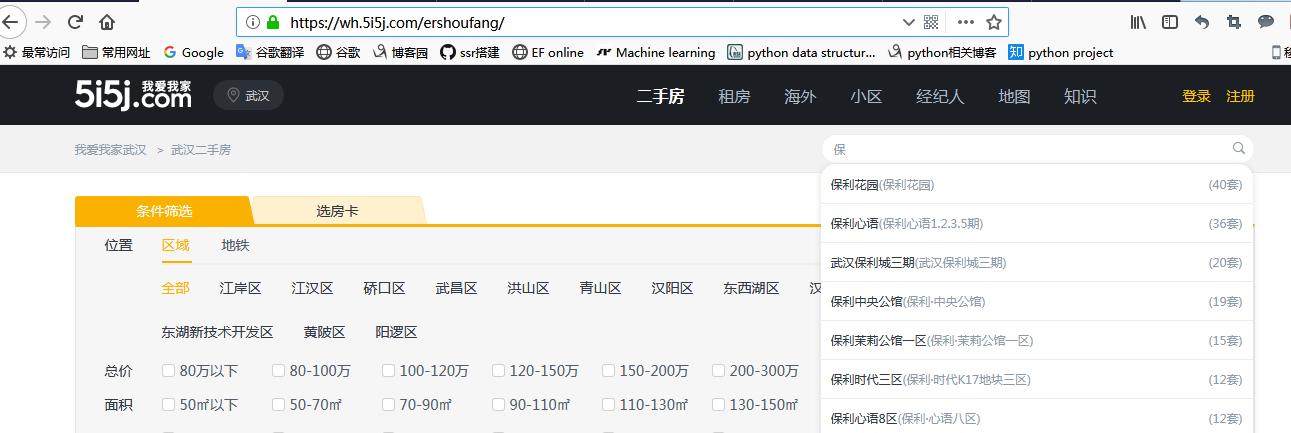
通过network分析可以看到ajax请求的返回一个json对象:
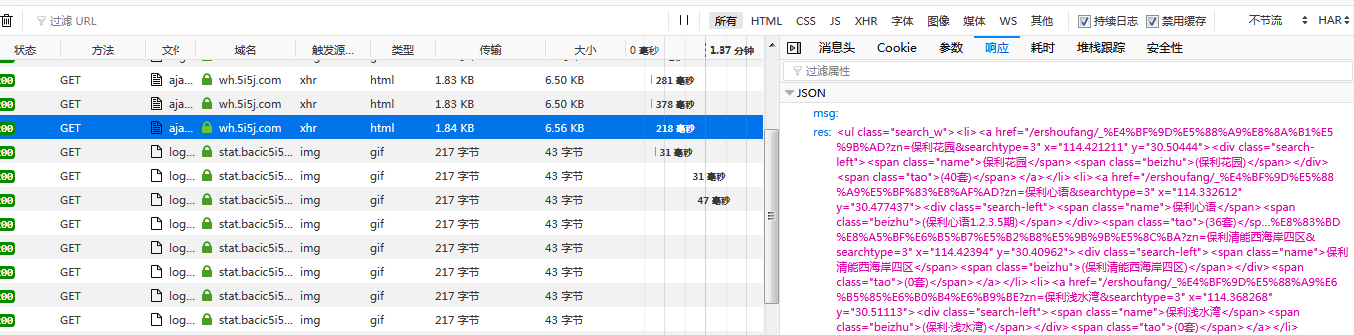
2. 抓取数据
2.1 利用requests
构造ajax请求的url,利用ajax请求,分析拿到的json数据,代码如下:
#coding:utf-8 import requests import json from lxml import html url="https://wh.5i5j.com/ajaxsearch?status=ershoufang&keywords=%s"%(u'恒') response = requests.get(url,headers={'User-Agent':"Mozilla/5.0 (Windows NT 6.1; r…) Gecko/20100101 Firefox/64.0"}) html_string = json.loads(response.text)['res'] tree = html.fromstring(html_string) li_tags=tree.getchildren() house_info={} for tag in li_tags: name = tag.xpath('.//div/span[@class="name"]/text()')[0] count = tag.xpath('.//span[@class="tao"]/text()')[0] print name,count house_info[name]=count # print house_info
2.2 利用selenium
selenium可以模拟浏览器的行为,因此可以用来作为爬虫使用(但速度较慢),模拟浏览器访问网站。
安装selenium:pip install selenium
(下载浏览器驱动:第一次使用selenium时,可能会报错selenium.common.exceptions.WebDriverException,这是因为需要下载模拟的浏览器的驱动,下载地址https://github.com/SeleniumHQ/selenium/tree/master/py#drivers)
selenium的使用参考:http://www.aneasystone.com/archives/2018/02/python-selenium-spider.html
使用selenium抓取上面数据的代码如下:
from selenium import webdriver driver = webdriver.Firefox(executable_path='D:\\Python\\geckodriver.exe') #路径为下载的浏览器驱动保存路径 driver.get('https://wh.5i5j.com/zufang/') #打开网页 kw = driver.find_element_by_id("zufang") #找到搜索框 kw.send_keys(u"万") #搜索框中输入文字 “万” # button = driver.find_element_by_class_name("btn-search") # button.click() driver.implicitly_wait(30) #隐式等待30秒,浏览器查找每个元素时,若未找到会等待30s,30s还未找到时报错 li_tags = driver.find_elements_by_css_selector('ul.search_w li') #注意此处是find_elements, 复数查找多个element for li_tag in li_tags: name = li_tag.find_element_by_class_name('name').text count = li_tag.find_element_by_class_name('tao').text print name, count
上面代码中,由于ajax请求执行完成需要时间,driver.implicitly_wait(30)让浏览器隐式等待30秒,即浏览器查找每个元素时,若未找到会等待30s,30s后还未找到时会报错。
关于selenium的等待有显示等待和隐式等待。(区别参考:https://www.cnblogs.com/dsy-sun/articles/6594866.html)
显示等待:明确说明等待某个元素出现或条件成立时,如下面代码:
newWebDriverWait(driver,15).until(
ExpectedConditions.presenceOfElementLocated(By.cssSelector("css locator")));
隐式等待:全局的,对所有元素都有效,找不到该元素时会等待设定时间,如上面的driver.implicitly_wait(30)

