

(二)爬虫之数据提取
通过Resquest或urllib2抓取下来的网页后,一般有三种方式进行数据提取:正则表达式、beautifulsoup和lxml,留下点学习心得,后面慢慢看。
1. 正则表达式
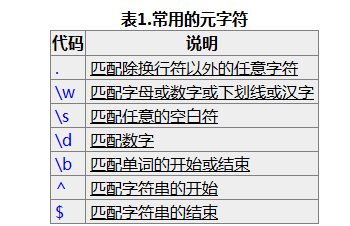
看完文档后理解正则表达式的基本概念就行,然后知道贪婪匹配和懒惰匹配的区别。实际运用过程中用的最多的就两种( .*?) 和 (d+) 分别用来匹配任意字符和数字,?表示懒惰匹配。
pattern=re.compile(string[,flag])
#以下为匹配所用函数
re.match(pattern, string[, flags])
re.search(pattern, string[, flags])
re.findall(pattern, string[, flags])
re.finditer(pattern, string[, flags])
#字符串处理
re.split(pattern, string[, maxsplit])
re.sub(pattern, repl, string[, count])
re.subn(pattern, repl, string[, count]
flags:参数flag是匹配模式,取值可以使用按位或运算符’|’表示同时生效,比如re.I | re.M
re.I(全拼:IGNORECASE): 忽略大小写(括号内是完整写法,下同)
re.M(全拼:MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
re.S(全拼:DOTALL): 点任意匹配模式,改变'.'的行为
re.L(全拼:LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
re.U(全拼:UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
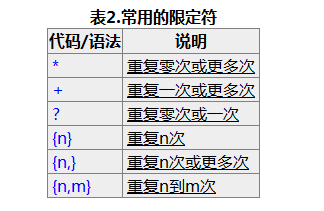
re.X(全拼:VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释
2.beautifulsoup
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment 。主要理解Tag,Tag与html中的tag相同,其有两个最重要的属性name和attribute, 分别通过tag.name和tag.attrs来调用。方法中应用最多的的就是fin() 和find_all()
find_all( name , attrs , recursive , text , **kwargs )
soup.find_all("a")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
find( name , attrs , recursive , text , **kwargs
soup.find("head").find("title")
# <title>The Dormouse's story</title>
3. lxml
3.1 lxml安装
lxml最麻烦的就是安装的时候容易现各种问题,如果pip install lxml 出现问题,推荐安装方法:
(1)安装wheel :pip install wheel
(2)下载与自己系统匹配的wheel(如下),注意别改下载文件的文件名,下载链接http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml

(3) 进入.whl所在的文件夹,执行命令:pip install 带后缀的完整文件名
3.2 lxml使用
关于lxml的使用,lxml可以用来处理xml(lxml.etree模块)和html(lxml.html模块)。处理html并进行元素提取时,先将抓取到的html字符窜转换成Html Element或者Element Tree,再利用Element的xpath或cssselect方法查找元素
lxml.html模块 https://lxml.de/lxmlhtml.html
lxml.etree模块 https://lxml.de/tutorial.html
(1)html转换:fromstring()
lxml.html模块中有五个方法进行转换,一般使用parse()和fromstring()两个方法。
parse(filename_url_or_file):参数为html文件名称或文件对象,返回ElementTree对象
fromstring(string): 参数为包含html文档的字符窜,返回HtmlElment对象
关于Element 和ElementTree的区别,参考:https://lxml.de/tutorial.html#the-fromstring-function
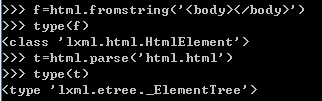
爬虫中多使用fromstring(),如下:
import lxml.html
tree=lxml.html.fromstring(html) #fromstring() 将string转换成HtmlElement,tostring()将HtmlElement转换成string
(2)元素匹配:lxml选择元素有几种不同的方法,有XPath选择器和类似beautiful soup 的 find()方法,CSS选择器等。
使用XPath匹配元素
参考:
xpath with lxml: https://lxml.de/xpathxslt.html
xpath解析html示例:https://gist.github.com/IanHopkinson/ad45831a2fb73f537a79
xpath语法:http://www.w3school.com.cn/xpath/xpath_syntax.asp
先了解下xpath的语法:




使用示例代码如下:


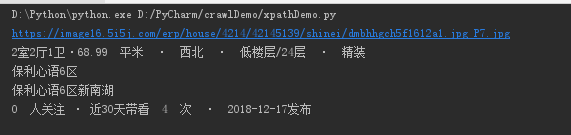
#coding: utf-8 from lxml import html html_string = """ <div class="listImg" onmousedown=""> <a href="/ershoufang/42145139.html" target="_blank"> <!--<img src="">--><img class="lazy" onerror="houseimgerror(this,0)" src="https://image16.5i5j.com/erp/house/4214/42145139/shinei/dmbhhgch5f1612a1.jpg_P7.jpg" title="保利心语六期,精装两房,户型方正超大阳台,东南朝向采光好" alt="保利心语六期,精装两房,户型方正超大阳台,东南朝向采光好"> </a> </div> <div class="listCon"> <h3 class="listTit"> <a href="/ershoufang/42145139.html" target="_blank" onmousedown="">保利心语六期,精装两房,户型方正超大阳台,东南朝向采光好</a> </h3> <div class="listX"> <!-- <p><i class="i_01"></i>4室2厅· 192.67平米· 南北 ·中层/11层 ·精装</p> --> <p><i class="i_01"></i>2室2厅1卫·68.99 平米 · 西北 · 低楼层/24层 · 精装</p> <p><i class="i_02"></i>保利心语6区<a href="/xiaoqu/398836.html" target="_blank">新南湖 </a> <!-- · 地铁10号线 --></p> <p><i class="i_03"></i>0 人关注 · 近30天带看 4 次 · 2018-12-17发布</p> <div class="jia"> <p class="redC"><strong>149</strong>万</p> <p>单价21597元/m²</p> </div> </div> <div class="listTag"><span>随时看</span></div> </div> """ tree = html.fromstring(html_string.decode('utf-8')) #转化为utf-8字符窜 img = tree.xpath('//div/a/img[@class="lazy"]')[0] #返回值为包含一个Element的list, 提取img element img_src = tree.xpath('//div/a/img[@class="lazy"]/@src')[0] #直接获取img标签的src属性 house_desc = tree.xpath('//div[@class="listX"]/p[1]/text()')[0] #提取第一个p element的文本内容 house_address = tree.xpath('//div[@class="listX"]/p[2]/text()')[0] #提取第二个p element的文本内容 adress_element = tree.xpath('//div[@class="listX"]/p[2]')[0] #提取第二个p element house_action = tree.xpath('//div[@class="listX"]/p[3]/text()')[0] #提取第三个p element的文本内容 print img.attrib['src'] #attrib为img的属性字典 print img_src print house_desc print house_address #只拿到了该标签包含的文本内容 print adress_element.text_content() #能拿到该标签及其子标签包含的所有文本 print house_action
执行结果如下:(注意查询条件中的'/text()'和element的text_content()之间的区别)
使用CSSSelector匹配元素:
使用cssselector选择器示例代码如下:
#coding: utf-8 from lxml import html html_string = """ <div class="listImg" onmousedown=""> <a href="/ershoufang/42145139.html" target="_blank"> <!--<img src="">--><img class="lazy" onerror="houseimgerror(this,0)" src="https://image16.5i5j.com/erp/house/4214/42145139/shinei/dmbhhgch5f1612a1.jpg_P7.jpg" title="保利心语六期,精装两房,户型方正超大阳台,东南朝向采光好" alt="保利心语六期,精装两房,户型方正超大阳台,东南朝向采光好"> </a> </div> <div class="listCon"> <h3 class="listTit"> <a href="/ershoufang/42145139.html" target="_blank" onmousedown="">保利心语六期,精装两房,户型方正超大阳台,东南朝向采光好</a> </h3> <div class="listX"> <!-- <p><i class="i_01"></i>4室2厅· 192.67平米· 南北 ·中层/11层 ·精装</p> --> <p><i class="i_01"></i>2室2厅1卫·68.99 平米 · 西北 · 低楼层/24层 · 精装</p> <p><i class="i_02"></i>保利心语6区<a href="/xiaoqu/398836.html" target="_blank">新南湖 </a> <!-- · 地铁10号线 --></p> <p><i class="i_03"></i>0 人关注 · 近30天带看 4 次 · 2018-12-17发布</p> <div class="jia"> <p class="redC"><strong>149</strong>万</p> <p>单价21597元/m²</p> </div> </div> <div class="listTag"><span>随时看</span></div> </div> """ tree = html.fromstring(html_string.decode('utf-8')) #转化为utf-8字符窜 img = tree.cssselect('img.lazy')[0] t = tree.cssselect('div.listX > p') #div下的所有p标签,t[0],t[1],t[2]依次为第一二三个p标签 p1 = tree.cssselect('div.listX > p:first-child')[0] #div下的第一个p标签 print img.attrib['src'] print t[0].text_content()
执行结果如下:

