正则表达式
为何产生:
1、处理文本成为计算机常见的工作之一;
2、对文本内容的搜索提取是一项比较复杂困难的工作
3、为了快速方便处理上述问题,正则表达式技术应运而生,并逐渐发展为一个被大众语言使用的独立技术
定义:
即高级文本匹配模式,提供了搜索,替代等功能。其本质是由一系列特殊符号和字符组成的字串,这个字串即是正则表达式。这个表达式描述了字符和字符的重复行为,可以匹配某类特征的字符串。
特点:
1、方便进行检索和修改;
2、支持语言众多
3、灵活多样
4、mongo正则类型,Django等框架作为URL匹配
使用:
python中有re模块,专门用来处理正则表达式
re.findall(pattern,string)
功能:使用正则表达式匹配字符串
参数:pattern 正则表达式
string 目标字符串
返回值:一个列表(匹配到的所有内容)
元字符:
即正则表达式中有特殊含义的字符
1、普通字符
元字符:ab
匹配规则:匹配相应的普通字符
>>> re.findall('ab','ab37748aabb3004jadab')
['ab', 'ab', 'ab']
2、或
元字符:ab|cd
匹配规则:匹配‘’|"两边任意字符
>>> re.findall('ab|77','ab37748aabb3004jadab77')
['ab', '77', 'ab', 'ab', '77']
*“|”两侧不要有没有用的空格,因为空格也会参与匹配
>>> re.findall('ab | 77','ab37748aabb3004jadab77')
[]
3、匹配单一字符:
元字符:'.'
匹配规则:匹配除了换行之外的任意字符
>>> re.findall('a.b','a b37748a3bb3004jadab77')
['a b', 'a3b']
4、匹配开始位置
元字符:^
匹配规则:匹配一个字符串的开始位置
>>> re.findall('^ab','ab37748a3bb3004jadab77')
['ab']
5、匹配结束位置
元字符:$
匹配规则:匹配目标字符串的结束位置
>>> re.findall('ab$','ab37748a3bb3 ab 004jad ab')
['ab']
6、匹配重复
元字符:*
匹配规则:匹配前面的正则表达式重复0次或者多次
>>> re.findall('ab*','ab37748abb3 a abbb 004jad abb')
['ab', 'abb', 'a', 'abbb', 'a', 'abb']
>>>注意a 的出现,是因为ab*可以匹配b为0,也就是匹配a
7、匹配重复
元字符:+
匹配规则:匹配前面的正则表达式,重复一次或者多次
ab+ -----------ab abb abbb
>>> re.findall('.*','ab37748abb3 a abbb 004jad abb')
['ab37748abb3 a abbb 004jad abb', '']
>>> re.findall('.+','ab37748abb3 a abbb 004jad abb')
['ab37748abb3 a abbb 004jad abb']
>>>
8、匹配重复:
元字符:?
匹配规则:匹配前面的正则表达式,重复0次或1次
>>> re.findall('ab?','ab37748abb3 a abbb 004jad abb')
['ab', 'ab', 'a', 'ab', 'a', 'ab']
>>>
9、匹配重复
元字符:{n}
匹配规则:匹配前面的正则表达式,指定的重复次数
>>> re.findall('ab{3}','ab37748abb3 a abbb 004jad abb')
['abbb']
>>> re.findall('ab{2}','ab37748abb3 a abbb 004jad abb')
['abb', 'abb', 'abb']
>>> re.findall('ab{1}','ab37748abb3 a abbb 004jad abb')
['ab', 'ab', 'ab', 'ab']
>>>
10、匹配重复
元字符:{m,n}
匹配规则:匹配前面的正则表达式重复m次到n次
>>> re.findall('ab{2,3}','ab37748abb3 a abbb 004jad abb')
['abb', 'abbb', 'abb']
>>>
11、匹配字符集合
元字符:[]
匹配规则:匹配括号范围内的任意一个字符
[a-z]
[A-Z]
[0-9]
[123A-Za-z]
>>> re.findall('[0-5a-zA-Z]','abZA96FM12z')
['a', 'b', 'Z', 'A', 'F', 'M', '1', '2', 'z']
>>>
12、匹配字符集合
元字符:{^...]
匹配规则:匹配除指定字符集外的任意字符
>>> re.findall('[^0-5a-zA-X]','abZA96FM12z')
['Z', '9', '6']
>>>
>>> re.findall('[^0-5a-dA-X]','abZA96FM12z')
['Z', '9', '6', 'z']
>>>
13、匹配任意(非)数字字符
元字符:\d \D
匹配规则:\d匹配任意数字字符 等价于[0-9]
\D 匹配任意非数字字符 等价于[^]
>>> re.findall('1\d','13388749920')
['13']
>>> re.findall('\d','13388749920')
['1', '3', '3', '8', '8', '7', '4', '9', '9', '2', '0']
>>> re.findall('2\d','13388749920')
['20']
>>> re.findall('1\d{10}','13388749920')
['13388749920']
>>> re.findall('1\d{5}','13388749920')
['133887']
>>>
14、匹配(非)普通字符(普通字符:数字、字母、下划线)
元字符:\ w \W
匹配规则:\w 匹配任意一个普通字符 [_0-9a-zA-Z]
\ W 匹配任意非普通字符[^_0-9a-zA-Z]
>>> re.findall('\w','hello_world')
['h', 'e', 'l', 'l', 'o', '_', 'w', 'o', 'r', 'l', 'd']
>>> re.findall('\w+','hello_world')
['hello_world']
>>> re.findall('\w+','hello_!world') ! 为非普通字符
['hello_', 'world']
>>> re.findall('\W+','hello_!world')
['!']
>>>
15、匹配(非)空字符:
元字符:\s \S
匹配规则:\s 匹配任意空字符 【\n\t\r】存在,但看不见 \r:表示回车
\n表示换行
\t:表示Table
\S 匹配任意非空字符
>>> re.findall('\s','helle world\r\n\t')
[' ', '\r', '\n', '\t']
>>>
>>> re.findall('[A-Z]\S*','hello Wold ni China S ##') *匹配0或多个
['Wold', 'China', 'S']
>>> re.findall('[A-Z]\S+','hello Wold ni China S ##') +匹配1或多个
['Wold', 'China']
>>>
>>> re.findall('[A-Z]\S','hello Wold ni China S ##') 因为S后面是空格,\S匹配非空字符
['Wo', 'Ch']
>>>
>>> re.findall('[A-Z]','hello Wold ni China S ##')
['W', 'C', 'S']
>>>
16、匹配起止位置
元字符:\A \Z
匹配规则:\A 匹配开始位置
\Z 匹配结束位置
绝对匹配 \Aabc\Z-------------abc(且字符串只是abc)
>>> re.findall('\A/\w+/\w+\Z','/car/byd')
['/car/byd']
>>>
17、匹配(非)单词边界位置
元字符:\b \B
匹配规则:\b 匹配单词的边界
\B 匹配非单词的边界
单词边界:数字、字母、下划线和其他字符的交接位置为单词的边界
>>> re.findall(r"\Bis\b","This is china") 注意此次有r,作为转移符
['is']
>>> re.findall(r"\bis\b","This is china")
['is']
>>> re.findall(r"is\b","This is china")
['is', 'is']
>>>
总结:
匹配单一一个字符:a . \d \D \W \w \s \S [...] [^...]
匹配重复性:*匹配0次或多次
+匹配1次或多次
?匹配0次或1 次
{N} 匹配n次
{m,n}匹配m到n次
匹配某个位置:^ & \A \Z \b \B
其他:| () \
转义字符
正则表达式特殊符号:
. * ? $ ''" '' [] {} () \^
如果想匹配特殊符号则加转义
>>> re.findall("\"\.\"",'this is a "."')
['"."']
r(raw 原生字符串,不进行转义)

贪婪和非贪婪
正则表达式默认的重复匹配模式:
贪婪模式(尽快多的向后匹配)
>>> re.findall("bc*",'thbcccccccs')
['bccccccc']
>>> re.findall("bc+",'thbcccccccs')
['bccccccc']
>>> re.findall("bc?",'thbcccccccs') 0次或1次
['bc']
>>> re.findall("bc{2,5}",'thbcccccccs')
['bccccc']
* +?{m,n}
非贪婪模式(尽可能少的匹配内容,满足正则表达式含义即可)
* +?{m,n} 在这4个字符后,加上?就可以
>>> re.findall("bc*?",'thbcccccccs')
['b']
>>> re.findall("bc+?",'thbcccccccs')
['bc']
>>> re.findall("bc{2,5}?",'thbcccccccs')
['bcc']
>>> re.findall("bc??",'thbcccccccs')
['b']
>>>
正则表达式分组
使用()可以为一个正则表达式建立一个子组,子组可以看做内部的整体
子组的作用:
1、增加子组后,对正则表达式整体的匹配内容没有影响
>>> re.findall("aa(fc)",'thaafcccccccs')
['fc']
>>> re.findall("ax(fc)",'thaafcccccccs')
[]
>>>
2、子组可以改变重复元字符的重复行为
>>> re.findall("aa(fc)*",'thaafcccccccs')
['fc']
>>> re.findall("aafc*",'thaafcccccccs')
['aafccccccc']
>>>
3、子组在某些操作中,可以对子组匹配内容单独提取
子组的注意事项
1、每个正则表达式可以有多个子组,由外到内,由左到右
2、子组通常不要交叉
捕获组和非捕获组(命名组和非命名组)
子组命名格式
(?P<name>abc)
1、很多编程接口可以直接通过名字获取子组匹配内容
2、捕获组中的正则表达式可以通过名字重复调用
(?P=name)
>>> re.search('(?P<dog>ab)cdef(?P=dog)','abcdefabcx').group()
'abcdefab'
>>>
re模块
compile(pattern ,flags=0)
功能:获取正则表达式对象
参数:pattern:正则表达式
flags:功能标志位,提供更丰富的匹配
返回值:正则表达式对象
obj.findall(string,pos,endpos)
功能:通过正则表达式匹配字符串
参数:string 目标字符串
pos 目标字符串的匹配开始位置
endpos 目标字符串的结束位置
返回值: 匹配到的所有内容以列表返回
*如果正则表达式有子组,则只显示子组匹配内容
import re
pattern=r'ab'
#获取正则表达式
obj=re.compile(pattern)
l=obj.findall('abcdeabdabab')
print(l)
结果
yangrui@ubuntu:~/day9$ python3 re1.py ['ab', 'ab', 'ab', 'ab']
import re
pattern=r'ab'
#获取正则表达式
obj=re.compile(pattern)
l=obj.findall('abcdeabdabab',6,10)
print(l)
结果
yangrui@ubuntu:~/day9$ python3 re1.py ['ab']
obj.split(string)
功能:按照正则表达式切割目标字符串
参数;目标字符串
pattern=r'\s+'
#获取正则表达式
obj=re.compile(pattern)
l=obj.split('hello world hello bj !')
print(l)
yangrui@ubuntu:~/day9$ python3 re1.py
['hello', 'world', 'hello', 'bj', '!']
obj.sub(replacestr,string,max)
功能:替换正则表达式匹配到的内容
参数:replacestr 要替换的内容
string 目标字符串
max 最多替换几处
返回值:替换后字符串
import re
pattern=r'\s+'
#获取正则表达式
obj=re.compile(pattern)
s=obj.sub('##',"hello world come on !")
print(s)
yangrui@ubuntu:~/day9$ python3 re1.py
hello##world##come##on##!
import re
pattern=r'\s+'
#获取正则表达式
obj=re.compile(pattern)
s=obj.sub('##',"hello world come on !",3)
print(s)
yangrui@ubuntu:~/day9$ python3 re1.py
hello##world##come##on !
obj.subn(replacestr,string,count)
功能:替换正则表达式匹配到的内容
参数:replacestr 要替换的内容
string 目标字符串
count 最多替换几处
返回值:返回替换后的字符串和实际替换的个数
import re
pattern=r'\s+'
#获取正则表达式
obj=re.compile(pattern)
s=obj.subn('##',"hello world come on !")
print(s)
yangrui@ubuntu:~/day9$ python3 re1.py
('hello##world##come##on##!', 4) 4是替换的个数
obj.finditer(string)
功能:使用正则表达式匹配目标内容
参数:目标字符串
返回值:迭代对象,迭代的每个内容为一个match对象
import re
tt=re.finditer(r'\d+',\
'我爱你祖国,520我爱你00轻松气质,红梅2019')
for i in tt:
print(i.group())
yangrui@ubuntu:~/day9$ python3 re1.py
520
00
2019
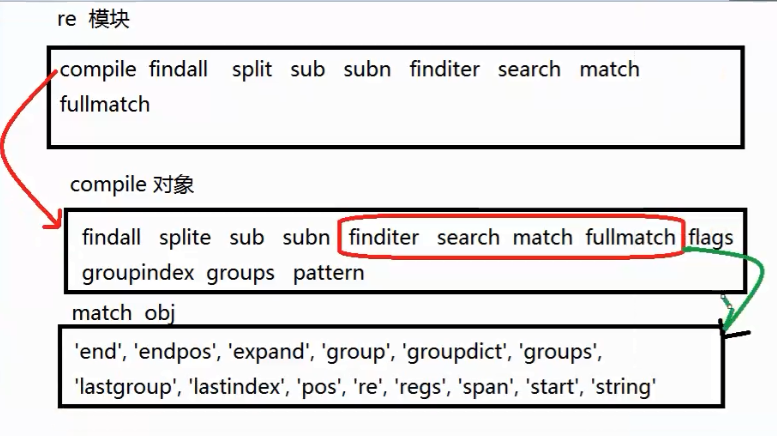
re.match(pattern,string)
功能:匹配一个匹配字符的开头
参数:目标字符串
返回值:如果匹配到返回 match obj
没有匹配到返回 None
特殊需求表达式
1 Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
3 InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
4 手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
5 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
6 国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
7 身份证号(15位、18位数字):^\d{15}|\d{18}$
8 短身份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$
9 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
10 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
11 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
12 日期格式:^\d{4}-\d{1,2}-\d{1,2}
13 一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
14 一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
15 钱的输入格式:
16 1.有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
17 2.这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
18 3.一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
19 4.这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
20 5.必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
21 6.这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
22 7.这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
23 8.1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
24 备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
25 xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
26 中文字符的正则表达式:[\u4e00-\u9fa5]
27 双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
28 空白行的正则表达式:\n\s*\r (可以用来删除空白行)
29 HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (网上流传的版本太糟糕,上面这个也仅仅能部分,对于复杂的嵌套标记依旧无能为力)
30 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
31 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
32 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
33 IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有用)
34 IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号