

postgresql分析函数
参考:https://blog.csdn.net/haohaizijhz/article/details/83340814
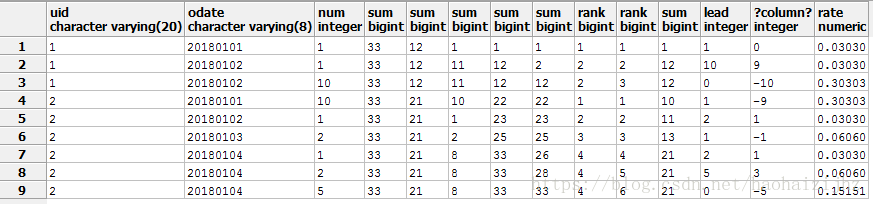
SELECT uid, odate, num, sum(num) over (), sum(num) over (partition by uid), sum(num) over (partition by uid,odate), sum(num) over (order by uid,odate), sum(num) over (order by uid,odate,num), rank() over (partition by uid order by odate), rank() over (partition by uid order by odate,num), sum(num) over (partition by uid order by odate), lead(num,1,0) OVER (partition by uid order by odate), -num+lead(num,1,0) OVER (partition by uid order by odate), 1.0*num/sum(num) over() rate FROM dev."order";
SELECT name, course, score,
sum(score) over (order by course rows between unbounded preceding and current row),
sum(score) over (order by course range between unbounded preceding and current row)
FROM dev.score;
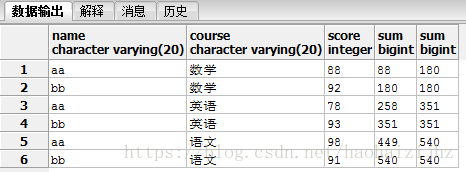
ORDER BY子句:分析函数中ORDER BY的存在将添加一个默认的开窗子句,这意味着计算中所使用的行的集合是当前分区中当前行和前面所有行;没有ORDER BY时,默认的窗口是全部的分区。
脚踏实地,仰望星空。
