

CS231N Assignment3 入门笔记(Q3 Transformer)
斯坦福2023年春季CS231N课程第三次作业(最后一次)解析、笔记与代码,作为初学者入门学习。
在这项作业中,将实现语言网络,并将其应用于 COCO 数据集上的图像标题。然后将训练生成对抗网络,生成与训练数据集相似的图像。最后,将学习自我监督学习,自动学习无标签数据集的视觉表示。
本作业的目标如下:
1.理解并实现 RNN 和 Transformer 网络。将它们与 CNN 网络相结合,为图像添加标题。
2.了解如何训练和实现生成对抗网络(GAN),以生成与数据集中的样本相似的图像。
3.了解如何利用自我监督学习技术来帮助完成图像分类任务。
Q3: Image Captioning with Transformers
The notebook Transformer_Captioning.ipynb will walk you through the implementation of a Transformer model and apply it to image captioning on COCO.
将指导您完成Transformer模型的实现,并将其应用于CoCo上的图像字幕。
# Transformer: Multi-Headed Attention
这里作业中直接给出了几种注意力机制,不太了解的可以先查阅一些博客熟悉一下背景和原理
例如:https://zhuanlan.zhihu.com/p/383675526
接下来先完成forward函数,注意不要用torch.permute的语法格式,应该更改为形如query = query.permute((0, 2, 1, 3))的形式
主要公式为:
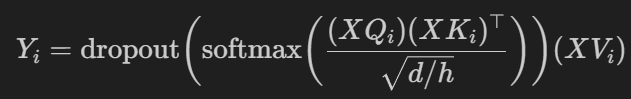
1 def forward(self, query, key, value, attn_mask=None): 2 """ 3 Calculate the masked attention output for the provided data, computing 4 all attention heads in parallel. 5 6 In the shape definitions below, N is the batch size, S is the source 7 sequence length, T is the target sequence length, and E is the embedding 8 dimension. 9 10 Inputs: 11 - query: Input data to be used as the query, of shape (N, S, E) 12 - key: Input data to be used as the key, of shape (N, T, E) 13 - value: Input data to be used as the value, of shape (N, T, E) 14 - attn_mask: Array of shape (S, T) where mask[i,j] == 0 indicates token 15 i in the source should not influence token j in the target. 16 17 Returns: 18 - output: Tensor of shape (N, S, E) giving the weighted combination of 19 data in value according to the attention weights calculated using key 20 and query. 21 """ 22 N, S, E = query.shape 23 N, T, E = value.shape 24 # Create a placeholder, to be overwritten by your code below. 25 output = torch.empty((N, S, E)) 26 ############################################################################ 27 # TODO: Implement multiheaded attention using the equations given in # 28 # Transformer_Captioning.ipynb. # 29 # A few hints: # 30 # 1) You'll want to split your shape from (N, T, E) into (N, T, H, E/H), # 31 # where H is the number of heads. # 32 # 2) The function torch.matmul allows you to do a batched matrix multiply.# 33 # For example, you can do (N, H, T, E/H) by (N, H, E/H, T) to yield a # 34 # shape (N, H, T, T). For more examples, see # 35 # https://pytorch.org/docs/stable/generated/torch.matmul.html # 36 # 3) For applying attn_mask, think how the scores should be modified to # 37 # prevent a value from influencing output. Specifically, the PyTorch # 38 # function masked_fill may come in handy. # 39 ############################################################################ 40 # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** 41 42 # self.n_head = num_heads # H 43 # self.emd_dim = embed_dim # E 44 # self.head_dim = self.emd_dim // self.n_head #E/H 45 46 query = self.query(query) 47 # (N, S, H, E/H) 48 query = query.view(N, S, self.n_head, self.head_dim) 49 # (N, H, S, E/H) 50 query = query.permute((0, 2, 1, 3)) 51 52 key = self.key(key) 53 # (N, T, H, E/H) 54 key = key.view(N, T, self.n_head, self.head_dim) 55 # (N, H, E/H, T) 56 key = key.permute((0, 2, 3, 1)) 57 58 value = self.value(value) 59 # (N, T, H, E/H) 60 value = value.view(N, T, self.n_head, self.head_dim) 61 # (N, H, T, E/H) 62 value = value.permute((0, 2, 1, 3)) 63 64 # Calculate attention weights 65 # 注意公式里的d,代码中是E,d/h即E/H,为self.head_dim 66 # (N, H, S, E/H)*(N, H, E/H, T) = (N, H, S, T) 67 score = torch.matmul(query, key)/math.sqrt(self.head_dim) 68 69 # 如果提供了注意力掩码(attn_mask),则修改得分以防止某些值影响输出。 70 # 这通过使用 PyTorch 的 masked_fill 函数实现, 71 # 其中对应于掩码位置的任何得分都被替换为一个非常小的值:float('-inf') 72 if attn_mask is not None: 73 score = score.masked_fill(attn_mask.view(1,1,*attn_mask.size())==0, float('-inf')) 74 75 # (N, H, S, T) 76 # 沿着最后一个维度(dim=-1)对注意力得分进行归一化,得到注意力权重 77 attention_weights = F.softmax(score , dim=-1) 78 # dropout 79 attention_weights = self.attn_drop(attention_weights) 80 81 # (N, H, S, T)*(N, H, T, E/H) = (N, H, S, E/H) 82 output = torch.matmul(attention_weights, value) 83 # (N, S, H, E/H) -> (N, S, E) 84 output = output.permute(0, 2, 1, 3).reshape(N, S, E) 85 output = self.proj(output) 86 87 # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** 88 ############################################################################ 89 # END OF YOUR CODE # 90 ############################################################################ 91 return output
# Positional Encoding
虽然transformer能够轻松地处理其输入的任何部分,但注意机制没有token顺序的概念。然而,对于许多任务(特别是自然语言处理),相对token顺序是非常重要的。为了恢复这一点,作者在单个单词标记的嵌入中添加了位置编码Positional Encoding。

编码结果类似于:
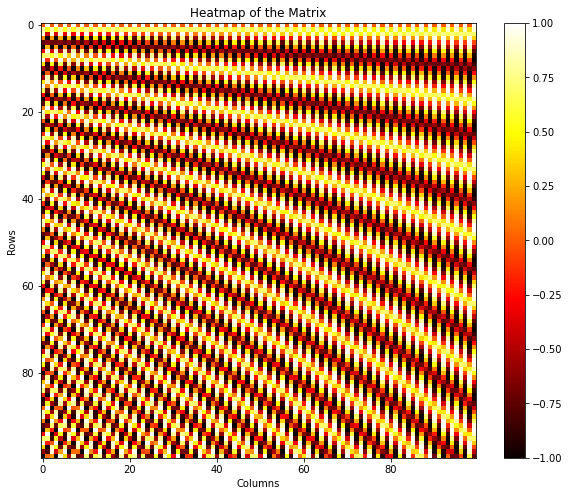
class PositionalEncoding(nn.Module): """ Encodes information about the positions of the tokens in the sequence. In this case, the layer has no learnable parameters, since it is a simple function of sines and cosines. """ def __init__(self, embed_dim, dropout=0.1, max_len=5000): """ Construct the PositionalEncoding layer. Inputs: - embed_dim: the size of the embed dimension - dropout: the dropout value - max_len: the maximum possible length of the incoming sequence """ super().__init__() self.dropout = nn.Dropout(p=dropout) assert embed_dim % 2 == 0 # Create an array with a "batch dimension" of 1 (which will broadcast # across all examples in the batch). pe = torch.zeros(1, max_len, embed_dim) # 使用torch.arange函数生成一个从0到max_len-1的序列。 # torch.arange的第一个参数是起始值(inclusive),第二个参数是结束值(exclusive) # 第三个参数是步长(默认为1)。 # dtype=torch.float表示生成的张量的数据类型为浮点型。 # .unsqueeze(1)将生成的张量在维度1上添加一个维度, # 将其形状从(max_len,)变为(max_len, 1)。 position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 这行代码使用torch.arange函数生成一个从0到embed_dim-1的序列, # 并且步长为2。然后,.float()将生成的张量转换为浮点型。 # (-math.log(10000.0) / embed_dim)计算出一个常数值。 # 最后,将序列乘以该常数值,并使用torch.exp对结果进行指数运算, # 得到一个包含位置编码的张量。 div_term = torch.exp(torch.arange(0, embed_dim, 2).float() * (-math.log(10000.0) / embed_dim)) # 2的倍数切片操作0::2和1::2 pe[:, :, 0::2] = torch.sin(position * div_term) pe[:, :, 1::2] = torch.cos(position * div_term) # Make sure the positional encodings will be saved with the model # parameters (mostly for completeness). self.register_buffer('pe', pe)
# Transformer for Image Captioning
完成forward函数
class CaptioningTransformer(nn.Module): """ A CaptioningTransformer produces captions from image features using a Transformer decoder. The Transformer receives input vectors of size D, has a vocab size of V, works on sequences of length T, uses word vectors of dimension W, and operates on minibatches of size N. """ def __init__(self, word_to_idx, input_dim, wordvec_dim, num_heads=4, num_layers=2, max_length=50): """ Construct a new CaptioningTransformer instance. Inputs: - word_to_idx: A dictionary giving the vocabulary. It contains V entries. and maps each string to a unique integer in the range [0, V). - input_dim: Dimension D of input image feature vectors. - wordvec_dim: Dimension W of word vectors. - num_heads: Number of attention heads. - num_layers: Number of transformer layers. - max_length: Max possible sequence length. """ super().__init__() vocab_size = len(word_to_idx) # 词汇表的大小,即词汇表中唯一单词的数量。 self.vocab_size = vocab_size # 特殊标记索引 self._null = word_to_idx["<NULL>"] self._start = word_to_idx.get("<START>", None) self._end = word_to_idx.get("<END>", None) # 线性层 将输入的图像特征从input_dim维度投影到wordvec_dim维度。 self.visual_projection = nn.Linear(input_dim, wordvec_dim) # 嵌入层 将词汇表中的单词索引映射为wordvec_dim维度的词向量。 self.embedding = nn.Embedding(vocab_size, wordvec_dim, padding_idx=self._null) # 位置编码层 self.positional_encoding = PositionalEncoding(wordvec_dim, max_len=max_length) decoder_layer = TransformerDecoderLayer(input_dim=wordvec_dim, num_heads=num_heads) self.transformer = TransformerDecoder(decoder_layer, num_layers=num_layers) self.apply(self._init_weights) # 线性层 解码器的输出投影到词汇表大小的维度上。 self.output = nn.Linear(wordvec_dim, vocab_size) def _init_weights(self, module): """ Initialize the weights of the network. """ if isinstance(module, (nn.Linear, nn.Embedding)): module.weight.data.normal_(mean=0.0, std=0.02) if isinstance(module, nn.Linear) and module.bias is not None: module.bias.data.zero_() elif isinstance(module, nn.LayerNorm): module.bias.data.zero_() module.weight.data.fill_(1.0) def forward(self, features, captions): """ Given image features and caption tokens, return a distribution over the possible tokens for each timestep. Note that since the entire sequence of captions is provided all at once, we mask out future timesteps. Inputs: - features: image features, of shape (N, D) - captions: ground truth captions, of shape (N, T) Returns: - scores: score for each token at each timestep, of shape (N, T, V) """ N, T = captions.shape # Create a placeholder, to be overwritten by your code below. scores = torch.empty((N, T, self.vocab_size)) ############################################################################ # TODO: Implement the forward function for CaptionTransformer. # # A few hints: # # 1) You first have to embed your caption and add positional # # encoding. You then have to project the image features into the same # # dimensions. # features = self.visual_projection(features)[:, None, :] captions = self.positional_encoding(self.embedding(captions)) # 2) You have to prepare a mask (tgt_mask) for masking out the future # # timesteps in captions. torch.tril() function might help in preparing # # this mask. # tgt_mask = torch.tril(torch.ones((T, T))) # 3) Finally, apply the decoder features on the text & image embeddings # # along with the tgt_mask. Project the output to scores per token # decoder_out = self.transformer(tgt=captions, memory=features, tgt_mask=tgt_mask) # (N, T, W) scores = self.output(decoder_out) return scores
结果为
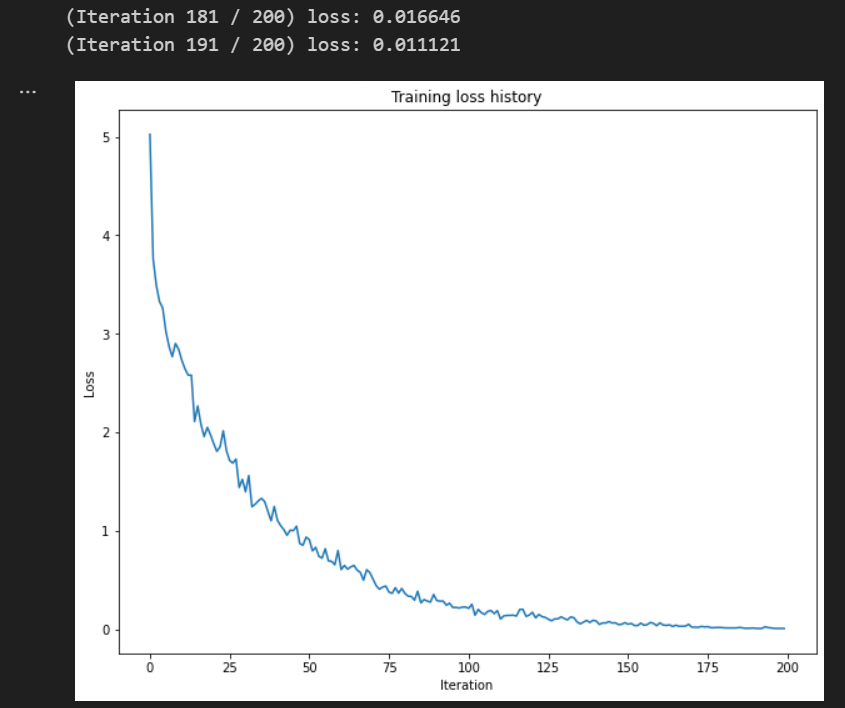
参考:https://github.com/Jaskanwal/stanford-CS231N-2023/blob/main/assignment3/cs231n

