
滴滴Booster移动APP质量优化框架 学习之旅
推荐阅读:
一、Booster简介
Booster是滴滴最近开源一个的移动应用质量优化框架项目,专门为移动应用而设计的简单易用、轻量级、功能强大且可扩展的质量优化工具包,其通过动态发现和加载机制提供可扩展的能力。不过目前优化的功能点不过。
Booster 主要由 Transformer 和 Task 组成,Transformer 主要用于对字节码进行扫描或修改(取决于 Transformer 的功能),Task 主要用于构建过程中的资源处理,为了满足特异的优化需求,Booster 提供了 Transformer SPI and VariantProcessor SPI允许开发者进行定制,以下是 Booster 的整体框架:
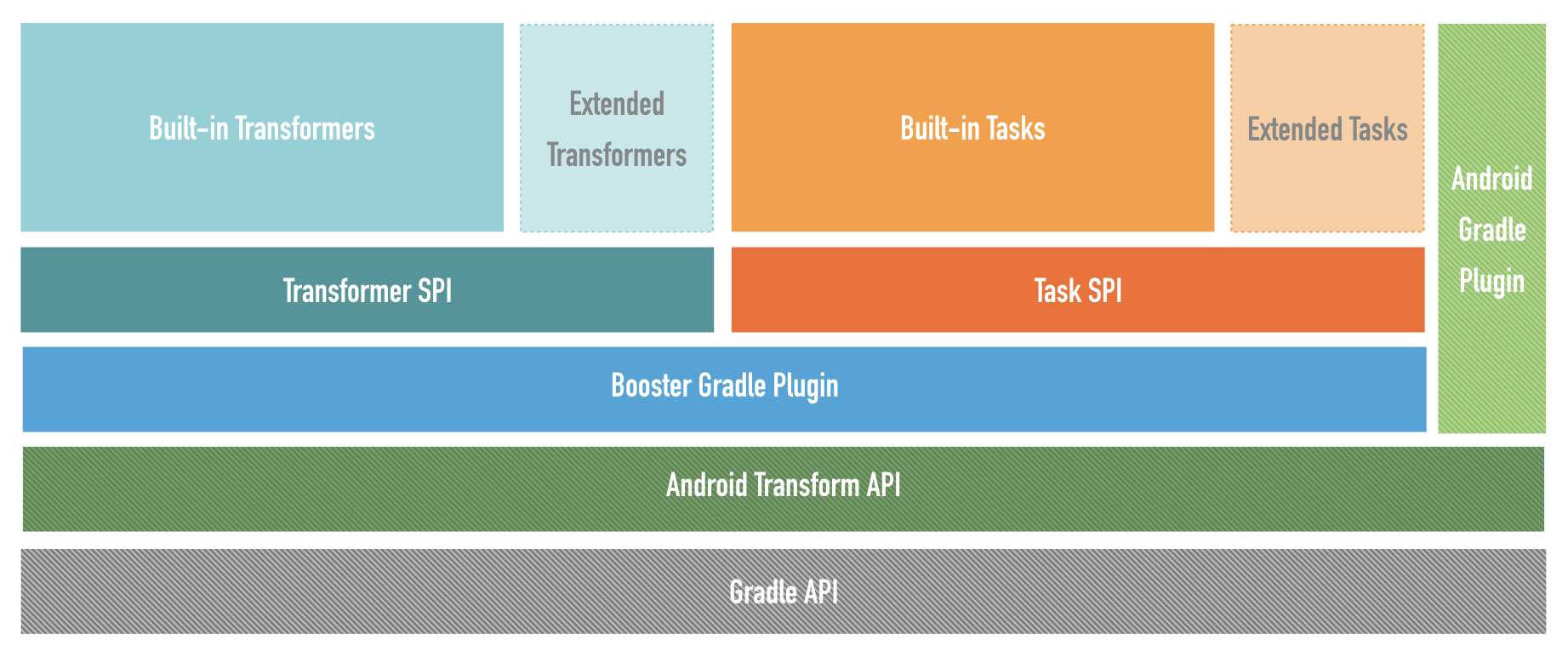
SPI带来的好处显而易见,不需要改动插件,只需要添加相关依赖,就可随意动态卸载和装载Transformer和VariantProcessor ,做到插件与Transformer和VariantProcessor
完全解耦。其实SPI化思想应用很广泛,比如美团外卖开源的WMRouter的路由节点装载、Glide中GlideModule的装载,不过相关配置信息保存早AndroidManifest文件中的元数据中。
二、目前Booster功能特性
1.动态加载模块
支持差异化的优化需求,Booster 实现了模块的动态加载,以便于开发者能在不使用配置的情况下选择使用指定的模块,详见:booster-task-all、booster-transform-all,也可以定制task和transform,然后设置classpath。
2.第三方类库注入
支持动态添加依赖或者注入某些类和库(比如插桩、无埋点统计等),详见:booster-transform-lint。
3.多线程优化
业务线众多的 APP 普遍存在线程过载的问题,而线程管理一直是开发者最头疼的问题之一,虽然可以通过制定严格的代码规范来归避此类问题发生而对于第三方 SDK 来说,代码规范则有些力不从心。为了彻底的解决这一问题,Booster 通过在编译期间修改字节码实现了全局线程池优化,并对线程进行重命名。详见:booster-transform-thread。
4.SharedPreferences 优化
SharedPreferences几乎无处不在,而在主线程中修改 SharedPreferences 会导致卡顿甚至 ANR,为了彻底的解决这一问题,Booster 对 APP 中的指令进行了全局的替换。详见:booster-transform-shared-preferences。
5.常量字段删除
无论是资源索引,还是其它常量字段,在编译完成后,就没有存在的价值了(反射除外),因此,Booster 将对资源索引字段访问的指令替换为常量指令,将其它常量字段从类中删除,一方面可以提升运行时性能,另一方面,还能减小包体积,资源索引(R)表面上看起来微不足道,实际上占用不少空间。
6.资源压缩
APP 的包体积也是一个非常重要的指标,在 APP 安装中,图片资源占了相当大的比例,通常情况下,图片质量降低 10%-20% 并不会影响视觉效果,因此,Booster 采用有损压缩来降低图片的大小,而且,图像尺寸越小,加载速度越快,占用内存越少。
Booster 提供了两种压缩方案:
1.pngquant 有损压缩(需要自行安装 pngquant 命令行工具)
2.cwebp 有损压缩(已内置)
7.性能检测
APP 的卡顿率是衡量应用运行时性能的一个重要指标,为了能提前发现潜在的卡顿问题,Booster 通过静态分析实现了性能检测,并生成可视化的报告帮助开发者定位问题所在,
其实现原理是通过分析所有的 class 文件,构建一个全局的 Call Graph, 然后从 Call Graph 中找出在主线程中调用的链路(Application、四大组件、View、Widget等相关的方法),然后再将这些链路以类为单位分别输出报告,详见:booster-transform-lint。
8.WebView 预加载
为了解决 WebView 初始化导致的卡顿问题,Booster 通过注入指令的方式,在主线程空闲时提前加载 WebView。
三、Booster框架实现原理
Booster以gradle插件形式实现,Transform,Task分别抽象为Transformer ,VariantProcessor,,支持Transformer SPI化 和VariantProcessor SPI化,供外部定制使用
,插件实现代码如下:
class BoosterPlugin : Plugin<Project> { override fun apply(project: Project) { when { project.plugins.hasPlugin("com.android.application") -> project.getAndroid<AppExtension>().let { android -> //注册Transform,spi 加载所有实现Transformer类 android.registerTransform(BoosterAppTransform()) project.afterEvaluate { //spi 加载所有实现VariantProcessor类,并迭代执行所有VariantProcessor ServiceLoader.load(VariantProcessor::class.java, javaClass.classLoader).toList().let { processors -> android.applicationVariants.forEach { variant -> processors.forEach { processor -> processor.process(variant) } } } } } project.plugins.hasPlugin("com.android.library") -> project.getAndroid<LibraryExtension>().let { android -> //注册Transform,spi 加载所有实现Transformer类,并迭代执行所有Transformer
android.registerTransform(BoosterLibTransform()) project.afterEvaluate { //spi 加载所有实现VariantProcessor类,并迭代执行所有VariantProcessor ServiceLoader.load(VariantProcessor::class.java, javaClass.classLoader).toList().let { processors -> android.libraryVariants.forEach { variant -> processors.forEach { processor -> processor.process(variant) } } } } } } } }
从插件源码中,显而易见可以找到VariantProcessor SPI化的地方,那Transformer SPI化的逻辑在哪里了? BoosterAppTransform和BoosterLibTransform都继承BoosterTransform,而BoosterTransform的Transform功能委托给BoosterTransformInvocation(支持增量和全量Transform),从其源码中轻易找到Transformer SPI化的逻辑,相关代码如下:
internal class BoosterTransformInvocation(private val delegate: TransformInvocation) : TransformInvocation, TransformContext, TransformListener, ArtifactManager { /* * Preload transformers as List to fix NoSuchElementException caused by ServiceLoader in parallel mode */ private val transformers = ServiceLoader.load(Transformer::class.java, javaClass.classLoader).toList()
//迭代回调onPostTransform
override fun onPostTransform(context: TransformContext) = transformers.forEach { it.onPostTransform(this) } ... }
内置Transformer的子类只有AsmTransformer,这里又对ClassTransformer进行SPI化
@AutoService(Transformer::class) class AsmTransformer : Transformer { /* * Preload transformers as List to fix NoSuchElementException caused by ServiceLoader in parallel mode */ private val transformers = ServiceLoader.load(ClassTransformer::class.java, javaClass.classLoader).toList()
//迭代回调onPostTransform
override fun onPostTransform(context: TransformContext) { transformers.forEach { it.onPostTransform(context) } } ... }
ps:AutoService 自动生成MEATA_INF配置文件
所有这里定制Transformer,可以两种方式:
一、自定义Transformer ,使用AutoService注解该类
二、自定义ClassTransformer,由AsmTransformer 递归回调ClassTransformer的onPostTransform,使用AutoService注解该类
官方内置Transformer 定制,倾向使用第二种方式,比如:booster-transform-thread,booster-transform-lint等。
四、定制Transformer 实践
在官方文档中添加内置的Transformer 和task时,是在Root Project中添加依赖classpath,classpath一般是添加buildscript本身需要运行的东西,buildScript是用来加载gradle脚本自身需要使用的资源,可以声明的资源包括依赖项、第三方插件、maven仓库地址等。而app/lib中的gradle中dependencies 中添加的使应用程序所需要的依赖包,也就是项目运行所需要的东西。
在以前一直以为用final 和static修饰的字段都是常量,其实不然,常量(或者说是常量变量)仅可能为简单类型或者String类型,是被一个常量表达式初始化,并且必须为final的,在Java语言规范(§4.12.4)中,对于常量有着明确的定义。
这里实现打印所有类的final 和static修饰的字段的Transformer,新建一个java libModule,实现Transformer关键代码如下:
override fun transform(context: TransformContext, klass: ClassNode): ClassNode { klass.printConstantFields() return klass } private fun ClassNode.printConstantFields() { fields.map { it as FieldNode }.filter { 0 != (Opcodes.ACC_STATIC and it.access) && 0 != (Opcodes.ACC_FINAL and it.access) //&& it.value != null }.forEach { // fields.remove(it) logger.println("field: `$name.${it.name} : ${it.desc}` = ${it.valueAsString()}") } }
FieldNode代表字段Node,value字段的值只能为基本类型和String,那么字段为引用类型,其value值为什么了?
在AppModule中定义User定义如下:

发布定制Transformer的module,再配置Root project 的classpath,进行打包后,查看Transformer报告如下:

由此可以判断类中字段为常量的依据为:
//it为FieldNode
0 != (ACC_STATIC and it.access) && 0 != (ACC_FINAL and it.access) && it.value != null
五、内置Transformers、tasks分析
分析完了Booster框架Spi原理后,接下来依次分析内置Transformers、tasks,从简单的入手
Transformer其实是对字节码进行修改,新增,删除等操作,在上车之前需要了解ASM,Java字节码指令集。这里简单介绍下本文用到的ASM知识点。
MethodNode中大多数属性和方法都和ClassNode类似,其中最主要的属性就是InsnList了,InsnList是一个双向链表对象,包含了存储方法
的字节指令序,每条指令对应一个AbstractInsnNode(代表字节码指令的抽象)。MethodInsnNode是继承AbstractInsnNode代表一次方法调用,
关键属性定义如下:
public class MethodInsnNode extends AbstractInsnNode { //方法所在的类 public String owner; //方法名 public String name; //方法的形参和返回值类型描述 如:(Ljava/lang/Thread;Ljava/lang/String;)Ljava/lang/Thread;
public String desc; //方法是否定义在接口中
public boolean itf;
}
booster-transform-shared-preferences
我们都知道shared-preferences的commit的操作(有返回值),有可能阻塞ui线程。Booster对没有用到返回值的commit操作放到异步线程中去,对应Transformer实现如下:
override fun transform(context: TransformContext, klass: ClassNode): ClassNode { if (klass.name == SHADOW_EDITOR) { return klass } //遍历ClassNode中opcode为INVOKEINTERFACE和owner为android/content/SharedPreferences$Editor的methodNodes klass.methods.forEach { method -> //遍历methodNode筛选出MethodInsnNode
method.instructions?.iterator()?.asIterable()?.filterIsInstance(MethodInsnNode::class.java)?.filter { it.opcode == Opcodes.INVOKEINTERFACE && it.owner == SHARED_PREFERENCES_EDITOR }?.forEach { invoke -> when ("${invoke.name}${invoke.desc}") { "commit()Z" -> if (Opcodes.POP == invoke.next?.opcode) { // if the return value of commit() does not used // use asynchronous commit() instead invoke.optimize(klass, method) method.instructions.remove(invoke.next) } "apply()V" -> invoke.optimize(klass, method) } } } return klass } private fun MethodInsnNode.optimize(klass: ClassNode, method: MethodNode) { logger.println(" * ${this.owner}.${this.name}${this.desc} => $SHADOW_EDITOR.apply(L$SHARED_PREFERENCES_EDITOR;)V: ${klass.name}.${method.name}${method.desc}") this.itf = false this.owner = SHADOW_EDITOR this.name = "apply" this.opcode = Opcodes.INVOKESTATIC this.desc = "(L$SHARED_PREFERENCES_EDITOR;)V" }
大家可能对这些字节码操作的逻辑看不懂,没关系,可以借助AndroidStudio查看字节码指令对照下,就秒懂了,编写如下图代码,查看Kotin 的ByteCode如图:

对照上图,调用1比调用2多了条POP指令,所以多了条Opcodes.POP == invoke.next?.opcode过滤条件,调用1比调用3多了POP指令,所以修改invoke后,需要从method的instructions中删除invoke.next。
查看Booster把不用到返回值的commit操作放到异步线程中去,具体实现如下:
public class ShadowEditor { public static void apply(final SharedPreferences.Editor editor) { if (Looper.myLooper() == Looper.getMainLooper()) { AsyncTask.SERIAL_EXECUTOR.execute(new Runnable() { @Override public void run() { editor.commit(); } }); } else { editor.commit(); } } }
Editor.apply本来就是异步的,不需要出处理,只把在主线程中调用不使用返回值的Editor.commit操作放到AsyncTask的SERIAL_EXECUTOR线程池中异步调用。
booster-transform-shrink
该transform的作用使删除应用包中多余的常量(基本类型和String);无论是资源索引,还是其它常量字段,在编译完成后,就没有存在的价值了(反射除外),因此,Booster 将对资源索引字段访问的指令替换为常量指令,将其它常量字段从类中删除,一方面可以提升运行时性能,另一方面,还能减小包体积,资源索引(R)表面上看起来微不足道,实际上占用不少空间。
有人可能对常量在编译完成后,没有存在的价值了(反射除外),不太理解,可以使用常量,查看其字节码,见下图:

在字节码并没有看到引用User类中常量的信息,而是直接使用了常量的值,所以类中的常量字段在编译后,就没有价值了。就可以删除了,当然反射该常量字段时,就不能删除了。该transform shrink的主要逻辑实现步骤如下:
1.读取符号列表symbolList,步骤6用到
2.读取白名单,支持类和常量字段粒度。
3.考虑三方库需要保留的常量
4.删除多余R类
5.删除常量
6.用常量替换资源索引
1.读取符号列表
在编译和打包过中会生成一些中间辅助文件,符号列表文件就是其中之一,如下图:
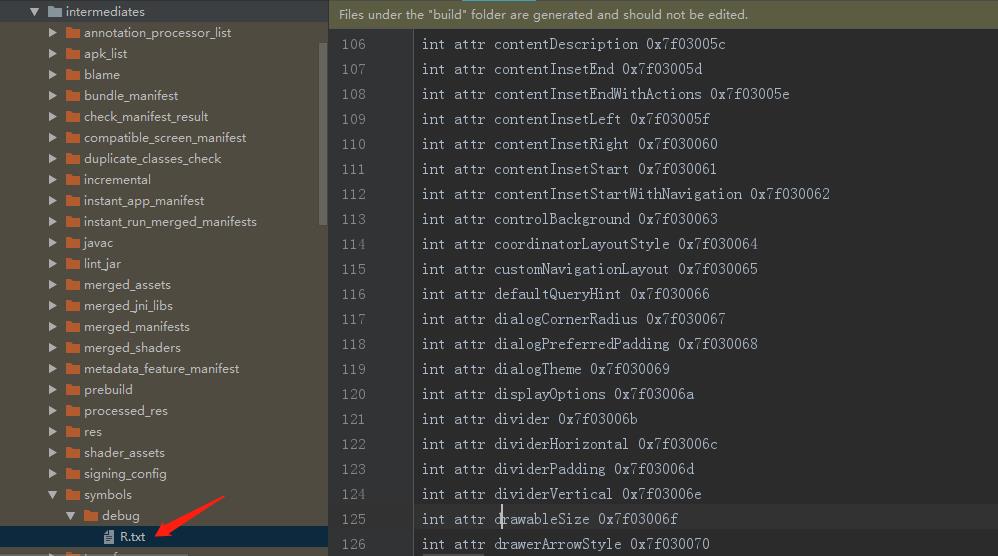
符号列表文件路径为
符号列表文件保存了App和Lib模块的所有R类merged后的所有字段信息,格式如下
dataType type name value //int id always 0x7f08001c //int[] styleable ActionBar { 0x7f030031, 0x7f030033,....} dateType: int和 int[] 两种,资源名对应的值得类型,dimen,anim的值等都为int类型,自定义控件的styleable为int[] type: dimen、anim、id等资源类型 name: 资源名 value: 资源名对应的值
2.读取白名单,支持类和常量字段粒度
当应用程序想要使用常量字段名(比如反射)和和保留类的所有常量字段时,需要字段名和类名添加到白名单中。
3.考虑三方库需要保留的常量
这里考虑了com.android.support.constraint包、GreenDao
我们现在会倾向使用ConstrainLayout减少布局层级,有可能会使用到Group和Barrier,这两个组件有个constraint_referenced_ids属性,根据该属性的值获取id名数组,然后根据id名值知道id的值,这个过程会设计到反射和Resource.getIdentifier,需要把这些id名添加到保留字段集合中,若存在需要保留字段,就需保留其R.$id类,添加白名单,避免该R.$id类被删除。
从Android Studio 3.0开始,google默认开启了aapt2作为资源编译的编译器,aapt2的出现,为资源的增量编译提供;aapt2将原先的资源编译打包过程拆分成了两部分,即编译和链接,这样就能很好的提升资源的编译性能,比如只有一个资源文件发送改变时,你只需要重新编译改变的文件,然后将其与其他未改变的资源进行链接即可。编译后的产物路径,如下图:

编译后的产物都是.flat文件,Booster只需要从layout编译产物中搜索constraint_referenced_ids,有意思的是进行搜索时,使用到Fork/Join框架,这是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。.flat文件的解析这里就不介绍了。
GreenDao中每一个Entity,插件会自动生成EntityDao,每一个Dao都有TABLENAME的常量,GreenDao初始化的时候会通过DataConfig反射获取各个Entity的TABLENAME常量,所以需要保留该常量字段。
4.删出多余R类文件
appModule、libModule,、三方库中R类会在中间产物目录/javac/下存有一个份R类的文件,如下图:
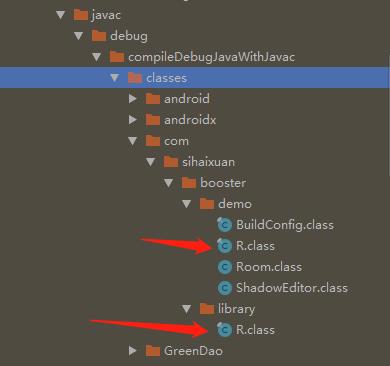
那么为什么能删除多余的R类文件了?当AppModule添加libModule,三方库的依赖时,会把libModule、三方库中R类merge到AppModule中的R类。我们验证下,在libModule中添加资源:
<string name="library_str">Library</string>
在中间产物目录/javac/下打开appModule的R类,搜索library_str,可以搜索得到。在打包生成的apk文件通过Jadx-gui查看appModule的R类同样可以搜索到library_str。
搜索冗余的R类文件的逻辑:
private fun TransformContext.findRedundantR(): List<Pair<File, String>> { return artifacts.get(JAVAC).map { classes -> val base = classes.toURI() classes.search { r -> r.name.startsWith("R") && r.name.endsWith(".class") && (r.name[1] == '$' || r.name.length == 7) }.map { r -> r to base.relativize(r.toURI()).path.substringBeforeLast(".class") } }.flatten().filter { it.second != appRStyleable // keep application's R$styleable.class }.filter { pair -> !ignores.any { it.matches(pair.second) } } }
为什么要过滤掉app的 R$styleable.文件了?
因为自定义的控件的styleable为int[]类型,比如:
public final class R$styleable {
public static final int[] ActionBar = new int[]{2130903089,...};
}
int[]类型非常量,前文已经知道AppModule R$styleable已经整合了libModule和三方库的R$styleable,所以需要保留app的 R$styleable.文件。
5.删除常量
在前文定制transform时,已经知道常量的条件为
//it为FieldNode 0 != (ACC_STATIC and it.access) && 0 != (ACC_FINAL and it.access) && it.value != null
再过滤掉白名单就可以删除剩下删除字段了
6.用常量替换资源索引
我们都清楚libModule中R文件的静态变量并没有赋予final属性,即不是常量,用到资源的地方,就需要通过资源索引,可以查看libModule中有资源引用的类的字节码进行验证,如下图:

通过Jadx-guic查看libModule包名下Test类,如图:

第五步会把这些字段都删除了,不替换的话,显然程序会崩溃,在第一步获取的符号列表symbolList存有所有R类资源字段的相关信息,从符号列表中提取资源索引对应的值,LDC指令替换掉GETSTATIC指令。
待续!
参考资料:
ASM(六) 利用TreeApi 动态生成以及转换方法字节码
RecursiveTask和RecursiveAction的使用 以及java 8 并行流和顺序流
如果您对博主的更新内容持续感兴趣,请关注公众号!



 浙公网安备 33010602011771号
浙公网安备 33010602011771号