

记录常见性能瓶颈解析及调优方案
常见性能瓶颈解析及调优方案
在性能测试中,导致性能出现瓶颈的原因很多,但通过直观的监控图表现出来的样子,根据出现的频次,大概有如下几种:
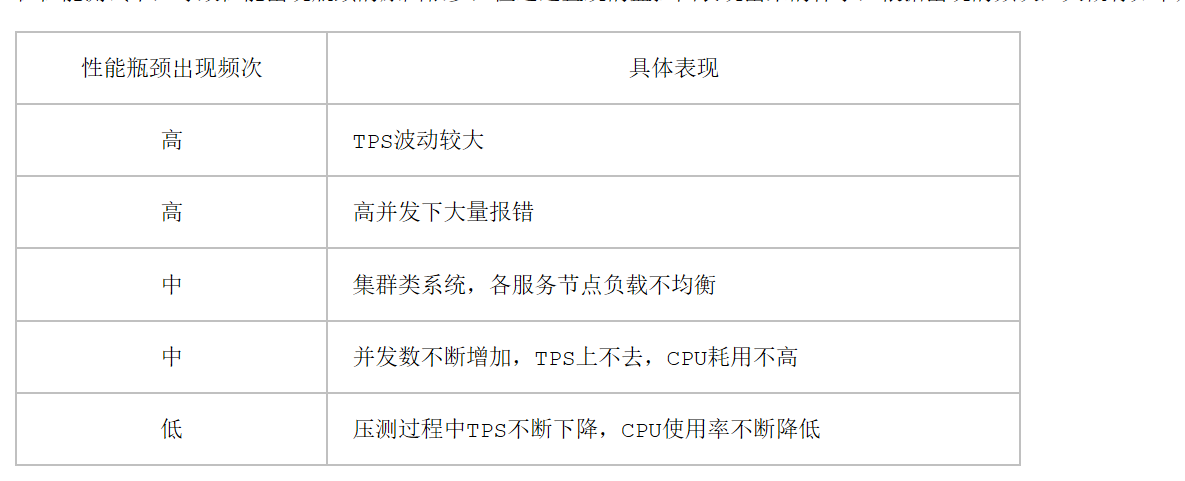
下面对常见的几种性能瓶颈原因进行解析,并说说常见的一些调优方案:
1、TPS波动较大
原因解析:出现TPS波动较大问题的原因一般有网络波动、其他服务资源竞争以及垃圾回收问题这三种。
性能测试环境一般都是在内网或者压测机和服务在同一网段,可通过监控网络的出入流量来排查;
其他服务资源竞争也可能造成这一问题,可以通过Top命令或服务梳理方式来排查在压测时是否有其他服务运行导致资源竞争;
垃圾回收问题相对来说是最常见的导致TPS波动的一种原因,可以通过GC监控命令来排查,命令如下:
1 # 实时打印到屏幕
2 jstat -gc PID 300 10
3 jstat -gcutil PID 300 10
4 # GC信息输出到文件
5 jstat -gc PID 1000 120 >>/path/gc.txt
6 jstat -gcutil PID 1000 120 >>/path/gc.txt
调优方案:
网络波动问题,可以让运维同事协助解决(比如切换网段或选择内网压测),或者等到网络较为稳定时候进行压测验证;
资源竞争问题:通过命令监控和服务梳理,找出压测时正在运行的其他服务,通过沟通协调停止该服务(或者换个没资源竞争的服务节点重新压测也可以);
垃圾回收问题:通过GC文件分析,如果发现有频繁的FGC,可以通过修改JVM的堆内存参数Xmx,然后再次压测验证(Xmx最大值不要超过服务节点内存的50%!)
2、高并发下大量报错
原因解析:出现该类问题,常见的原因有短连接导致的端口被完全占用以及线程池最大线程数配置较小及超时时间较短导致。
调优方案:
短连接问题:修改服务节点的tcp_tw_reuse参数为1,释放TIME_WAIT scoket用于新的连接;
线程池问题:修改服务节点中容器的server.xml文件中的配置参数,主要修改如下几个参数:
# 最大线程数,即服务端可以同时响应处理的最大请求数
maxThreads="200"
# Tomcat的最大连接线程数,即超过设定的阈值,Tomcat会关闭不再需要的socket线程
maxSpareThreads="200"
# 所有可用线程耗尽时,可放在请求等待队列中的请求数,超过该阈值的请求将不予处理,返回Connection refused错误
acceptCount="200"
# 等待超时的阈值,单位为毫秒,设置为0时表示永不超时
connectionTimeout="20000"
3、集群类系统,各服务节点负载不均衡
原因解析:出现这类问题的原因一般是SLB服务设置了会话保持,会导致请求只分发到其中一个节点。
调优方案:如果确认是如上原因,可通过修改SLB服务(F5/HA/Nginx)的会话保持参数为None,然后再次压测验证;
4、并发数不断增加,TPS上不去,CPU使用率较低
原因解析:出现该类问题,常见的原因有:SQL没有创建索引/SQL语句筛选条件不明确、代码中设有同步锁,高并发时出现锁等待;
调优方案:
SQL问题:没有索引就创建索引,SQL语句筛选条件不明确就优化SQL和业务逻辑;
同步锁问题:是否去掉同步锁,有时候不仅仅是技术问题,还涉及到业务逻辑的各种判断,是否去掉同步锁,建议和开发产品同事沟通确认;
5、压测过程中TPS不断下降,CPU使用率不断降低
原因解析:一般来说,出现这种问题的原因是因为线程block导致,当然不排除其他可能;
调优方案:如果是线程阻塞问题,修改线程策略,然后重新验证即可;
6、其他
除了上述的五种常见性能瓶颈,还有其他,比如:connection reset、服务重启、timeout等,当然,分析定位后,你会发现,我们常见的性能瓶颈,
导致其的原因大多都是因为参数配置、服务策略、阻塞及各种锁导致。。。
性能瓶颈分析参考准则:从上至下、从局部到整体!
以上分析及调优方案仅供参考,具体定位还需要根据日志监控等手段来分析调优。。。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· Qt个人项目总结 —— MySQL数据库查询与断言