在JMeter中如何设置参数化数据?
正式场景前的基准测试
在没有做业务混合场景之前,我们需要先做 Benchmark 测试,来确定一个登录业务能支持多少的业务量,这样就可以在业务混合场景中,根据场景中各业务的比例来确定登录的数据需要多少真实的数据。
summary + 125 in 00:00:04 = 31.0/s Avg: 28 Min: 0 Max: 869 Err: 0 (0.00%) Active: 1 Started: 1 Finished: 0 summary + 3404 in 00:00:30 = 113.2/s Avg: 31 Min: 0 Max: 361 Err: 0 (0.00%) Active: 6 Started: 6 Finished: 0 summary + 4444 in 00:00:30 = 148.4/s Avg: 57 Min: 0 Max: 623 Err: 10 (0.23%) Active: 11 Started: 11 Finished: 0
从上面的结果可以看到登录业务能达到的 TPS 是 113 左右,这里我们取整为 100,以方便后续的计算。
在测试工具中配置参数
下面我们从数据库中查询可以支持登录 5 分钟不重复的用户数据。根据前面的公式,我们需要 30000 条数据。
100x5mx60s=30000条
接下来连接数据库,取 30000 条数据,存放到文本中。
参数化配置在 JMeter 中的使用说明
我们将这些用户配置到测试工具的参数当中,这里以 JMeter 的 CSV Data Set Config 功能为例。配置如下:
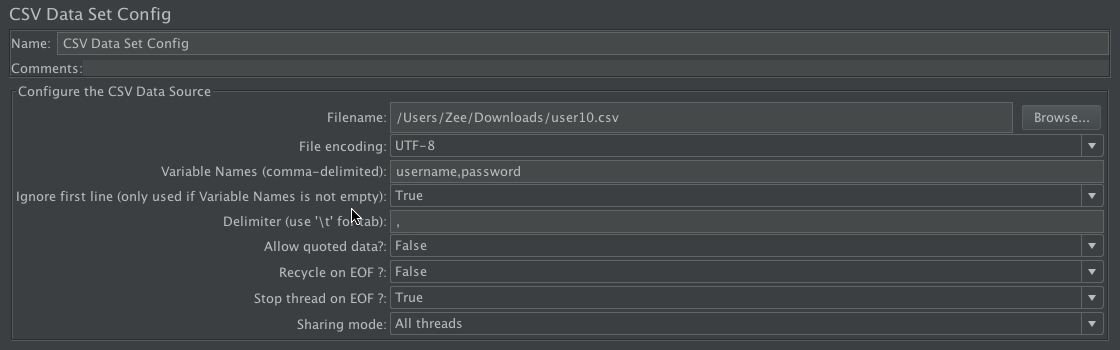
在 JMeter 的参数化配置中,有几个技术点,在这里说明一下。
“Allow quoted data?”这里有两个选择,分别是 False 和 True。它的含义为是否允许带引号的数据,比如说在参数化文件中有这样的数据。
"username","password"
"test00001","test00001"
"test00002","test00002"
...................
"test30000","test30000"
如果有引号,这个选择必须是 True。如果设置为 False,那么我们在脚本中会看到如下的数据:
username=%22test00001%22password=%22test00001%22
由于设置为 False,JMeter 将(")转换为了 %22 的 URL 编码,很显然这个数据是错的。如果选择为 True,则显示如下:
username=test00001password=test00001
- Recycle on EOF? :这里有三个选择,False、True 和 Edit。前两个选择非常容易理解。False 是指在没有参数的时候不循环使用;True 是指在没有参数的时候循环使用。Edit 是指在没有参数的时候会根据定义的内容来调用函数或变量。
- Stop thread on EOF?:这里有三个选择,False、True 和 Edit。含义和上面一致。
- Sharing mode : 这里有四个选择,All threads、Current thread group、Current thread、Edit。Sharing mode 的前三个选择是比较容易理解的,参数是在所有线程中生效,在当前线程组生效,还是在当前线程中生效。但这里的 Edit 和前两个参数中的 Edit 相比,有不同的含义。这里选择了 Edit 之后,会出现一个输入框,就是说这里并不是给引用函数和参数使用的,而是要自己明确如何执行 Sharing mode。那如何来使用呢?
举例来说,假设我们有 Thread Group 1-5 五个线程组,但是参数化文件只想在 Thread Group 1、3、5 中使用,不想在线程组 2、4 中使用,那么很显然前面的几个选项都达不到目的,这时我们就可以选择 Edit 选项,在这里输入SharedWithThreadGroup1and3and5。而在其他的线程组中配置其他参数化文件。
也就是说同样的一个变量名,在线程组 1/3/5 中取了一组数据,在线程组 2/4 中取了另一组数据。
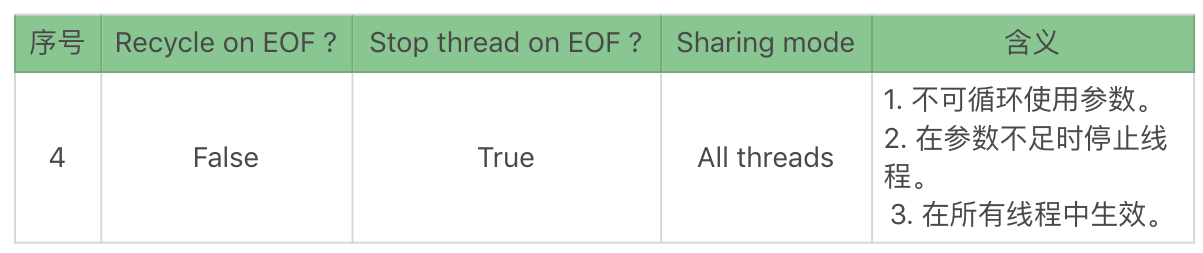
这是一个完全合情合理的组合!
真实场景下的 JMeter 参数配置和执行结果
根据以上的描述,我们先用 10 个用户来测试下,将 Stop thread on EOF?改为 True,将Recycle on EOF?改为 False,其他不变。同时将线程组中配置为 1 个线程循环 11 次。这样设置的目的是为了看在数据不足时,是否可以根据规则停掉线程组。如下所示:
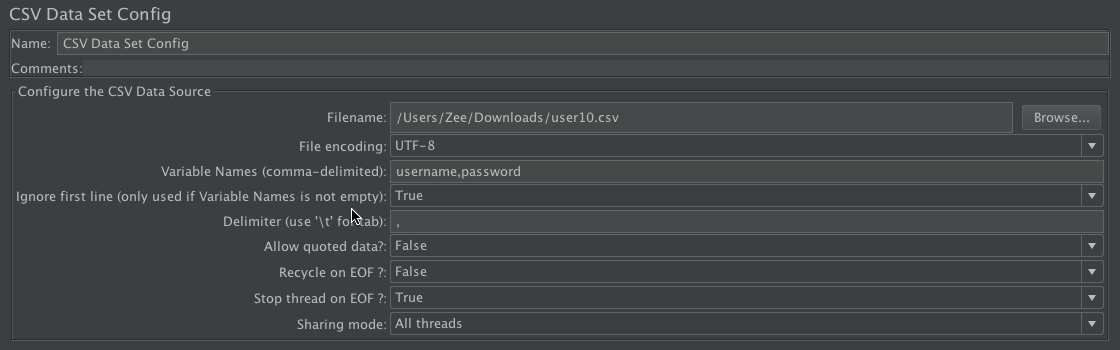
线程组配置如下:
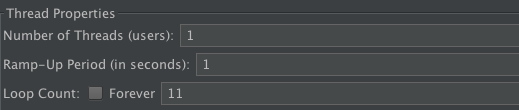
执行之后,我们会在日志中看到如下信息:
2019-09-05 22:56:30,171 INFO o.a.j.t.JMeterThread: Stop Thread seen for thread Thread Group 1 1-1, reason: org.apache.jorphan.util.JMeterStopThreadException: End of file:/Users/Zee/Downloads/user10.csv detected for CSV DataSet:CSV Data Set Config configured with stopThread:true, recycle:false
可以看到在参数用完又不可循环使用参数的情况下,JMeter 主动停止了线程。
总结
通过今天的内容,我们对性能测试中的参数化做了一次解析,在执行性能测试时,我们需要根据实际的业务场景选择不同的数据量和参数设置组合。
不同的压力工具在参数化的实现逻辑上也会不同,但是参数化必须依赖业务逻辑,而不是工具中能做到什么功能。
所以在参数化之前,我们必须分析真实业务逻辑中如何使用数据,再在工具中选择相对应的组合参数的方式去实现。
分析业务场景;
罗列出需要参数化的数据及相对应的关系;
将参数化数据从数据库中取出或设计对应的生成规则;
合理地将参数化数据保存在不同的文件中;
在压力工具中设置相应的参数组合关系,以便实现模拟真实场景。
通过以上步骤,我们就可以合理的参数化数据,模拟出真实场景。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号