怎么理解TPS、QPS、RT、吞吐量这些性能指标?
通常我们都从两个层面定义性能场景的需求指标:业务指标和技术指标。
我在这里借用大神的一张示意图以便你理解业务指标和性能指标之间的关系。
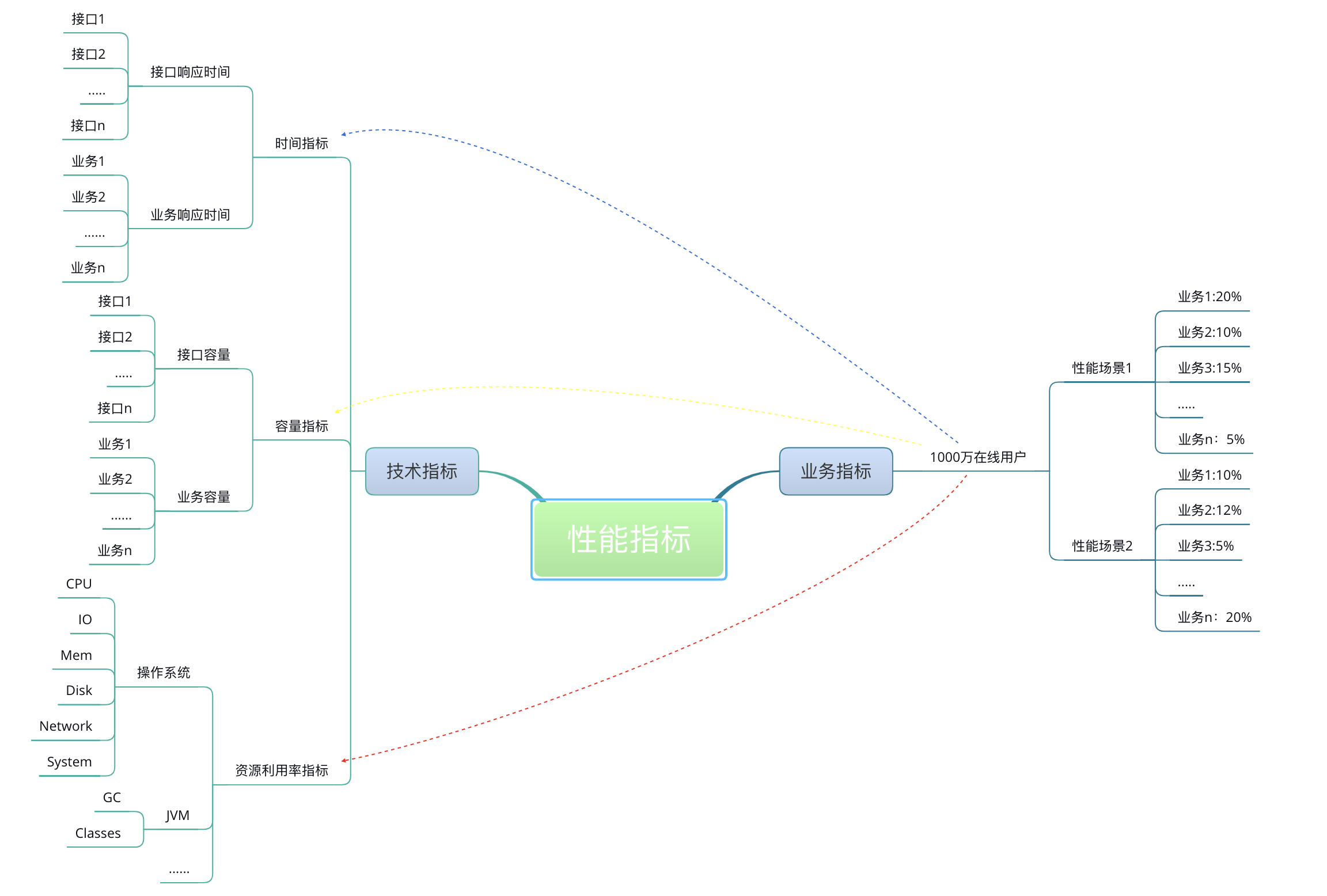
所有的技术指标都是在有业务场景的前提下制定的,而技术指标和业务指标之间也要有详细的换算过程。同时,在回答了技术指标是否满足的同时,也能回答是否可以满足业务指标。


TPS
为了区分这些概念,我们先说一下 TPS(Transactions Per Second)。我们都知道 TPS 是性能领域中一个关键的性能指标概念,它用来描述每秒事务数。我们也知道 TPS 在不同的行业、不同的业务中定义的粒度都是不同的。所以不管你在哪里用 TPS,一定要有一个前提,就是所有相关的人都要知道你的 T 是如何定义的。
通常情况下,我们会根据场景的目的来定义 TPS 的粒度。如果是接口层性能测试,T 可以直接定义为接口级;如果业务级性能测试,T 可以直接定义为每个业务步骤和完整的业务流。
如果我们要单独测试接口 1、2、3,那 T 就是接口级的;如果我们要从用户的角度来下一个订单,那 1、2、3 应该在一个 T 中,这就是业务级的了。
所以,性能中 TPS 中 T 的定义取决于场景的目标和 T 的作用。一般我们都会这样来定事务。
接口级脚本:——事务 start(接口 1)接口 1 脚本——事务 end(接口 1)——事务 start(接口 2)接口 2 脚本——事务 end(接口 2)——事务 start(接口 3)接口 3 脚本——事务 end(接口 3)业务级接口层脚本(就是用接口拼接出一个完整的业务流):——事务 start(业务 A)接口 1 脚本 - 接口 2(同步调用)接口 1 脚本 - 接口 3(异步调用)——事务 end(业务 A)
用户级脚本——事务 start(业务 A)点击 0 - 接口 1 脚本 - 接口 2(同步调用)点击 0 - 接口 1 脚本 - 接口 3(异步调用)——事务 end(业务 A)
你要创建什么级别的事务,完全取决于测试的目的是什么。
在性能测试过程中,TPS 之所以重要,是因为它可以反应出一个系统的处理能力。我在很多场景中都说过,事务就是统计了一段脚本的执行时间,并没有什么特别的含义。而现在又多加了其他的几个概念。
响应时间 RT
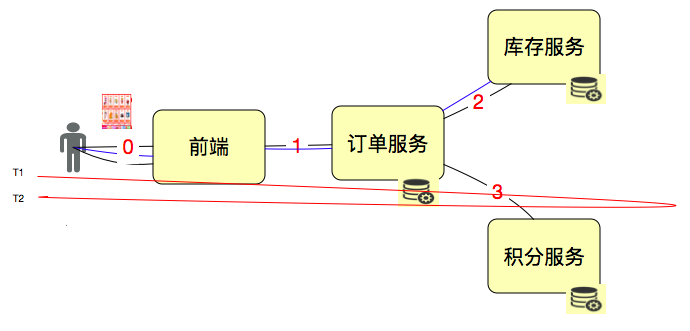
响应时间:RT = T2-T1 ,但是这个太笼统,反应不出问题。
因为我们要先画架构图,看请求链路,再一层层找下去。比如说这样:
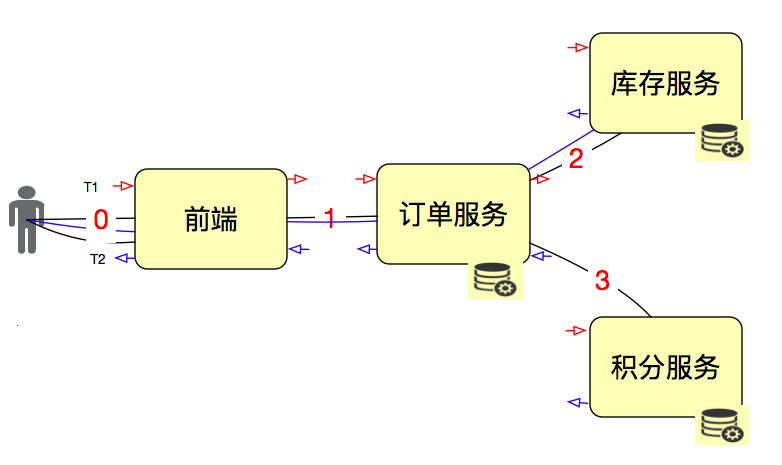
对于响应时间来说,时间的拆分定位是性能瓶颈定位分析中非常重要的一节。
在所有服务的进出口上都做记录,然后计算结果就行了。在做网关、总线这样的系统时,基本上都会考虑这个功能。
而现在,随着技术的发展,链路监控工具和一些 Metrics 的使用,让这个需求变得简单了不少。
压力工具中的线程数和用户数与 TPS
总是有很多人在并发线程数和 TPS 之间游荡,搞不清两者的关系与区别。这两个概念混淆的点就是,好像线程是真实的用户一样,那并发的线程是多少就描述出了多少真实的用户。但是做性能的都会知道,并发线程数在没有模拟真实用户操作的情况下,和真实的用户操作差别非常远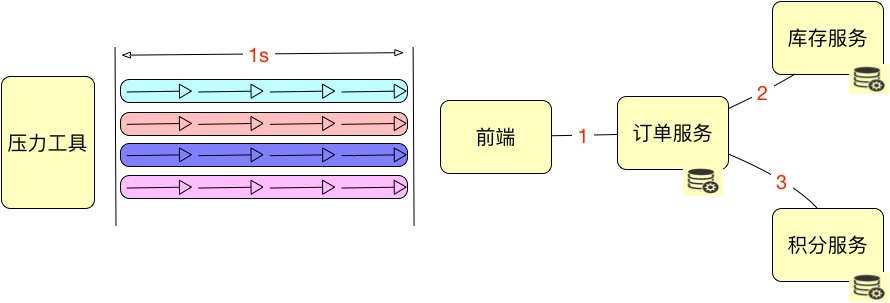
上图是4个线程,TPS为16,并发即为16.
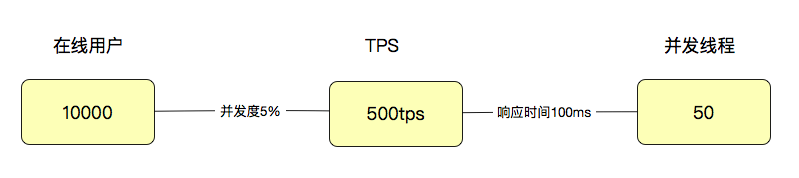
给你一个场景: 并发度为5%,需求满足10000用户在线
拿 5% 来计算,就是 10000 用户 x5%=500(TPS),注意哦,这里是 TPS,而不是并发线程数。如果这时响应时间是 100ms,那显然并发线程数是 500TPS/(1000ms/100ms)=50(并发线程)。
通过这样简单的计算逻辑,我们就可以看出来用户数、线程数和 TPS 之间的关系了。
但是!响应时间肯定不会一直都是 100ms 的嘛。所以通常情况下,上面的这个比例都不会固定,而是随着并发线程数的增加,会出现趋势上的关系。
业务模型下的响应时间
业务模型应该如何得到呢?
这里有两种方式是比较合理的:
1、根据生产环境的统计信息做业务比例的统计,然后设定到压力工具中。有很多不能在线上直接做压力测试的系统,都通过这种方式获取业务模型。
2、直接在生产环境中做流量复制的方式或压力工具直接对生产环境发起压力的方式做压力测试。这种方式被很多人称为全链路压测。其实在生产中做压力测试的方式,最重要的工作不是技术,而是组织协调能力。相信参与过的人都能体会这句话的重量。
那么响应时间如何设计比较合理呢?
这里有两种思路推荐给你。
1、同行业的对比数据。
2、找到使用系统的样本用户(越多越好),对他们做统计,将结果拿出来,就是最有效的响应时间的制定标准。
总结
性能测试概念中:性能指标、性能模型、性能场景、性能监控、性能实施、性能报告。
性能场景中:基准场景、容量场景、稳定性场景、异常场景。
性能指标中:TPS、RT。 (记住 T 的定义是根据不同的目标来的)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号