
贝叶斯优化
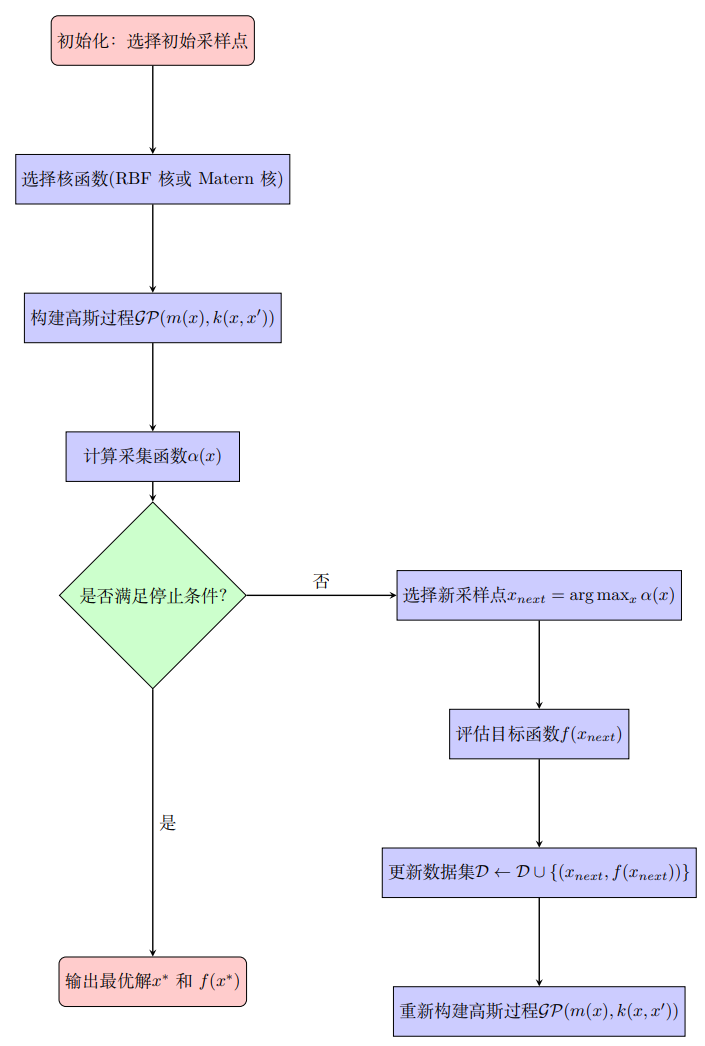
贝叶斯优化是一种用于优化目标函数的全局优化方法,其数学理论依赖于贝叶斯推断、高斯过程建模和采集函数的定义与优化.本文主要讨论贝叶斯优化的理论框架.
贝叶斯优化的目标是优化一个黑箱函数 \(f(x)\),即:
其含义是:
- 找到使得 \(f(x)\) 最小化的 \(x^*\) 值;
- \(\mathcal{X}\) 表示可能的\(x\) 值的搜索空间(定义域);
- \(\min\) 表示目标函数的最小值,而 \(\arg\) 表示达到这个最小值时对应的参数值.
补充一点,\(\arg\) 是 argument 的缩写,在数学中通常表示函数的输入.用在 \(\arg\min\) 或 \(\arg\max\) 中时,它专门用于指示哪个输入(自变量)使得目标函数 \(f(x)\) 取得最优值(最小值或最大值).
另外,由于每次评估 \(f(x)\) 都需要耗费大量时间或资源,因此我们只能进行有限次评估,而无法无限制地尝试所有可能的输入 \(x\).
通过贝叶斯推断,将 \(f(x)\) 的所有已知信息总结为后验分布;基于后验分布,利用采集函数选择下一个采样点 \(x_{next}\),以最小化目标函数.
注意了,目标函数 \(f(x)\) 是“黑箱”的,无法直接解析,但我们可以通过一组有限的采样点 \(\mathcal{D} = \{(x_i, f(x_i))\}_{i=1}^n\) 获取其离散信息.那么基于已有的采样数据,预测目标函数 \(f(x)\) 在某些新点\(x_*\) 的值及其不确定性。
而实际上,通过贝叶斯推断,目标函数的后验分布可以提供:预测均值(当前对目标函数值的最佳估计)、预测不确定性(目标函数值的置信范围).
贝叶斯推断的核心公式是:
构建目标函数 \(f(x)\) 的后验分布,其关键要素是:
先验分布 \(p(f(x))\):在没有观察到数据之前,我们对 \(f(x)\) 的假设.高斯过程通常假设目标函数 \(f(x)\) 满足 \(\mathcal{GP}(m(x), k(x, x'))\),即高斯分布.
似然 \(p(\mathcal{D} \mid f(x))\):描述数据(采样点)如何从目标函数中生成,通常假设数据带有一定的噪声.
贝叶斯公式结合了先验分布和似然信息,得出目标函数的后验分布:
:::
下面讨论高斯建模过程
高斯过程(GP)是贝叶斯优化中常用的目标函数代理模型.GP 是一个分布的集合,它将输入 \(x\) 映射到目标函数 \(f(x)\),假设:
- 任意有限点集的目标函数值服从多元高斯分布;
- GP 可以估计目标函数的均值和不确定性(方差).
通过其均值函数 \(m(x)\) 和协方差函数(核函数) \(k(x, x')\) 定义:
其中:
- \(m(x)\):预测的均值函数,表示函数的中心趋势;
- \(k(x, x')\):协方差函数,描述不同输入点之间的相关性。
常用的核函数有:
1.RBF 核(又称高斯核)定义为:
其中:
- \(\|x - x'\|\):\(x\) 和 \(x'\) 之间的欧几里得距离;
- \(l\):核尺度(length scale),控制核函数随距离变化的快慢。
我们对 \(k(x, x')\) 的变量(如 \(x_i\))计算导数:
展开后:
这个导数是连续的。
对于高阶导数:
经过展开,\(k(x, x')\) 的二阶导数也连续。
此时通过递归计算,可证明 \(k(x, x')\) 的任意高阶导数均连续,这说明 \(k(x, x')\) 是无穷可微的.
当 \(\|x - x'\| \gg l\) 时,RBF 核的主要项为 \(-\frac{\|x - x'\|^2}{2l^2}\),当 \(\|x - x'\|\) 增大时:
特别地,对于任意固定的 \(\epsilon > 0\),存在一个\(\|x - x'\|\) 的界限 \(R\),使得当 \(\|x - x'\| > R\) 时,\(|k(x, x')| < \epsilon\).
这表明 RBF 核值随距离的平方指数衰减,对远离 \(x'\) 的点贡献趋近于零.
尺度参数 \(l\) 决定了 RBF 核的函数平滑性及相关性范围,我们从以下两方面分析:
1.当\(l\) 增大时,RBF 核的衰减变得更缓慢,导致 \(k(x, x')\)的值在更大的距离范围内保持较高,因此,生成的目标函数表现得更加平滑。
2.当 \(l\) 减小时,RBF 核的衰减加快,导致函数值对局部变化更敏感,生成的目标函数变化更快.
取一维情况,\(x, x' \in \mathbb{R}\),核函数为:
对 \(x\) 求二阶导数:
展开后:
- 当 \(l\) 增大时,\(\frac{1}{l^2}\) 和 \(\frac{1}{l^4}\) 减小,导数值整体变小,表示函数变化更缓慢.
- 当 \(l\) 减小时,导数值变大,表示函数变化更剧烈.
一个核函数 \(k(x, x')\) 是正定的,如果对于任意有限点集 \(X = \{x_1, x_2, \dots, x_n\}\),核矩阵 \(K\) 是半正定矩阵(正定矩阵的放宽条件).
RBF 核是径向基函数,其正定性可以通过 Schoenberg 的定理证明.
对于任意点集 \(\{x_1, x_2, \dots, x_n\}\),RBF 核矩阵的 \((i, j)\) 元素为:
对任意权重向量 \(a = [a_1, a_2, \dots, a_n]^\top\),计算二次型:
通过展开:
由于 \(\exp(-x)\) 是正定函数,且平方和非负,\(\sum_{i,j} a_i a_j K_{ij} \geq 0\).
因此,RBF 核生成的核矩阵 \(K\) 是正定的,从而满足高斯过程的要求.
我们这里用了比较长的篇幅来解释这块,主要说明以下几点:
- RBF 核生成的函数是无穷可微的,适合光滑函数建模;
- RBF 核值对远离点快速衰减,表明其对局部相关性的建模能力;
- 控制核函数的平滑程度,调整生成函数的变化速度;
- 正定核,确保高斯过程的理论基础.
2.Matern 核的定义:
其中:
- \(\Gamma(\nu)\):伽马函数;
- \(K_\nu(\cdot)\):修正贝塞尔函数;
- \(\nu > 0\):平滑参数,决定核函数生成的目标函数的光滑性;
- \(l > 0\):尺度参数,控制函数变化的快慢。
通过参数 \(\nu\) 提供了从不光滑到光滑函数的一种建模灵活性.
为什么呢,注意:
该核的光滑性由参数 \(\nu\) 控制, 当 \(\nu = 1/2\) 时,Matern 核简化为绝对指数核:
对应的目标函数是连续但不可导的.
当 \(\nu > 1/2\) 时,函数逐渐变得更光滑:
- \(\nu = 3/2\):目标函数是一次可导的;
- \(\nu = 5/2\):目标函数是两次可导的;
- \(\nu \to \infty\):Matern 核趋于 RBF 核,生成函数是无穷可微的.
修正贝塞尔函数的定义为:
其中 \(I_\nu(r)\) 是第一类修正贝塞尔函数。
对于任意 \(\nu > 0\),\(K_\nu(r)\) 是连续可导的,且随 \(r\) 变化逐渐衰减.
核的导数阶数与参数 \(\nu\) 有直接关系,当 \(\nu = m + 1/2\)(\(m\) 为非负整数)时,Matern 核的目标函数是 \(m\) 次连续可导的.
核函数的导数由以下公式近似:
$$
\frac{\partial k(x, x')}{\partial x_i} \propto \left(\frac{\sqrt{2\nu}|x - x'|}{l}\right)^{\nu - 1} K_{\nu-1}\left(\frac{\sqrt{2\nu}|x - x'|}{l}\right),
$$
其中 \(K_{\nu-1}\) 表示贝塞尔函数的阶数降低 1。这表明 \(\nu - 1\) 决定了导数的最高阶次.
当 \(\nu \to \infty\) 时,核中的修正贝塞尔函数趋近于高斯分布核,函数的无限可微性逐渐显现.
表现为:
另外,核中的贝塞尔函数 \(K_\nu(r)\) 在 \(r \gg 1\) 时具有指数衰减性质:
这里 \(r = \frac{\sqrt{2\nu} \|x - x'\|}{l}\).
这意味着 Matern 核值在输入点之间的距离较大时迅速趋近于零
不难发现:
-
当 \(\nu\) 较大时:核函数的相关性扩展到更远的距离,局部性减弱。
-
当 \(\nu\) 较小时:核函数的值更快衰减,局部性增强.
-
较大的\(l\) 使得函数变化缓慢,相关性范围更广;
-
较小的 \(l\) 使得函数变化迅速,相关性范围更窄.
对于固定的 \(\nu\),\(\frac{\|x - x'\|}{l}\) 决定了衰减的速度.\(l\) 越大,衰减越慢;\(l\) 越小,衰减越快.
考虑一维输入:
当 \(l \to \infty\) 时,\(r \to 0\),核函数值趋近于 1;当 \(l \to 0\) 时,\(r \to \infty\),核函数值趋近于 0.这表明 \(l\) 决定了核函数的影响范围.
核函数 \(k(x, x')\) 是正定的,当且仅当对于任意点集 \(\{x_1, x_2, \dots, x_n\}\) 和任意权重向量 \(\{a_1, a_2, \dots, a_n\}\),以下关系成立:
Matern 核是径向基核的一种扩展,同样可以通过 Schoenberg 定理验证其正定性,因为修正贝塞尔函数 \(K_\nu(r)\) 满足正定核的构造条件.
后验分布:
假设已知 \(n\) 个采样点的数据集 \(\mathcal{D} = \{(x_i, f(x_i))\}_{i=1}^n\),目标是预测新点 \(x_*\) 的目标函数分布.
\(f(X)\) 和 \(f(x_*)\) 的联合分布为多元高斯分布:
其中:
- \(K(X, X)\):已知采样点的协方差矩阵;
- \(K(X, x_*)\):已知点与新点的协方差向量;
- \(K(x_*, x_*)\):新点的协方差。
条件分布(后验分布)为:
其中:
- 均值 \(\mu(x_*)\):\[\mu(x_*) = m(x_*) + K(x_*, X)K(X, X)^{-1}(f(X) - m(X)), \]表示当前模型对\(x_*\) 的预测值;
- 方差 \(\sigma^2(x_*)\):\[\sigma^2(x_*) = K(x_*, x_*) - K(x_*, X)K(X, X)^{-1}K(X, x_*), \]表示预测值的不确定性。
注意:
- \(\mu(x_*)\) 是对 \(f(x_*)\) 的预测值;
- \(\sigma(x_*)\) 是预测值的置信区间,反映目标函数的不确定性。
采集函数
采集函数用于在后验分布的基础上引导下一步的采样点选择。下面我们对期望改进(EI)、置信上界(UCB)和概率改进(PI)三种采集函数进行讨论:
\(\alpha(x)\)平衡两种优化策略:
1.利用:优先选择预测值较好的区域(\(\mu(x)\) 较小的位置),目标是快速找到局部最优点。
2.探索:优先选择预测不确定性较大的区域(\(\sigma(x)\) 较大),目标是扩展搜索范围,避免陷入局部最优。
通过优化 \(\alpha(x)\),采集函数在这两种策略之间找到平衡点,从而引导贝叶斯优化逐步逼近全局最优解.
期望改进(EI)
其中:
- \(f(x^+)\):当前的最优值(最小值);
- \(f(x)\):新点的目标函数值(服从后验分布 \(\mathcal{N}(\mu(x), \sigma^2(x))\))。
定义标准化变量:
其中:
- \(\mu(x)\):预测均值;
- \(\sigma(x)\):预测标准差。
采集函数的解析形式:
其中:
- \(\Phi(Z)\):标准正态分布的累积分布函数;
- \(\phi(Z)\):标准正态分布的概率密度函数。
针对利用部分: \((\mu(x) - f(x^+))\Phi(Z)\) 代表在目标函数值低于当前最优值的概率下,对差值的贡献。如果 $\mu(x) $ 明显小于 \(f(x^+)\),这部分值较大,EI 倾向于选择此点进行采样.
对于探索部分:\(\sigma(x)\phi(Z)\) 是由不确定性 \(\sigma(x)\) 贡献的改进部分.如果 \(\sigma(x)\) 较大,即目标函数在此区域的后验分布方差较大,EI 倾向于选择此点进行采样.
EI 同时考虑了目标函数值的最优性(利用)和不确定性(探索),是一种经典的采集函数.
有一点比较好的是,自然平衡探索和利用,无需额外超参数,但计算复杂度较高,因为需要计算正态分布的 \(\Phi(Z)\) 和 \(\phi(Z)\);对 \(\sigma(x) \approx 0\) 的区域可能退化为简单的利用策略。
置信上界(UCB)
其中:
- \(\kappa > 0\):控制探索与利用的权衡参数.
针对利用部分:\(\mu(x)\) 是目标函数的后验均值,直接反映对目标函数值的当前估计,较小的 \(\mu(x)\) 值优先被选择.
对于探索部分:\(\kappa \sigma(x)\) 用于控制探索性,\(\sigma(x)\) 表示不确定性,较大的 \(\kappa\) 值鼓励更多探索,较小的 \(\kappa\) 值则倾向于利用.
UCB 通过超参数 \(\kappa\) 在探索和利用之间明确权衡,较大的 \(\kappa\) 会优先选择预测方差较大的区域,从而增加对未知区域的探索.
很显然,仅需调节超参数 \(\kappa\),因此算法实现比较简单;但超参数 \(\kappa\) 的选择可能较敏感.
概率改进(PI)
其中:
- \(\Phi(Z)\):标准正态分布的累积分布函数;
- \(f(x^+)\):当前最优值。
PI 直接计算目标函数在新点 \(x\) 处改善当前最优值的概率,如果预测均值 \(\mu(x)\) 小于 \(f(x^+)\),且预测标准差 \(\sigma(x)\) 较大,则改善的概率较高。
另外,PI 强调利用,因为主要考虑改进当前最优值的概率;如果 \(\sigma(x)\) 很小(即后验分布不确定性低),PI 值可能退化为对预测均值的简单依赖.
不难看出,很可能探索性不足,容易陷入局部最优;在 \(\sigma(x)\) 较小时退化为利用策略.
| 特性 | 期望改进(EI) | 置信上界(UCB) | 概率改进(PI) |
|---|---|---|---|
| 平衡方式 | 同时动态考虑探索和利用 | 通过参数\(\kappa\) 手动平衡 | 更倾向于利用 |
| 复杂度 | 中等 | 低 | 低 |
| 适用场景 | 大多数场景 | 可控探索和利用比例 | 目标函数较平滑,探索需求低的场景 |
| 优点 | 自然平衡探索与利用,鲁棒性强 | 实现简单,可调节性好 | 算法直观,容易理解 |
| 缺点 | 计算复杂,可能退化为利用 | 需要手动调节超参数,可能不够灵活 | 探索性不足,易陷入局部最优 |
高斯过程的逼近能力
高斯过程 \(f(x) \sim \mathcal{GP}(m(x), k(x, x'))\) 是目标函数的非参数模型,假设目标函数 \(f(x)\) 的值服从多元高斯分布:
其中:
- \(m(X)\):目标函数的均值函数;
- \(K(X, X)\):核函数生成的协方差矩阵。
如果目标函数 \(f(x)\) 是连续的,并且我们采用的核函数 \(k(x, x')\) 是正定且足够光滑,那么高斯过程在理论上可以无限接近\(f(x)\),特别地,当采样点数量 \(n \to \infty\) 且分布覆盖整个定义域时,高斯过程的后验均值 \(\mu(x)\) 会收敛于目标函数\(f(x)\)
例如,对于 RBF 核和 Matern 核,后验误差界具有以下形式:
其中:
- \(C\):与目标函数特性相关的常数;
- \(\gamma_n\):核矩阵 \(K(X, X)\)的信息增益。
注意,使用 RBF 核时,高斯过程的误差收敛速度最优; Matern 核的误差收敛速度与其平滑参数 \(\nu\) 相关,\(\nu\) 越大,收敛速度越快.
此外,通过后验方差 \(\sigma(x)\) 量化未采样区域的模型不确定性.这种泛化能力是贝叶斯优化能够有效探索整个定义域的基础.
序贯设计
贝叶斯优化通过序贯设计逐步选择采样点 \(x_{next}\),以最小化目标函数 \(f(x)\)。其目标是随着迭代次数的增加,采样点能够逐步覆盖整个定义域,并集中在全局最优点 \(x^*\) 附近。其核心在于利用采集函数,通过结合目标函数的后验分布和不确定性估计,动态平衡探索和利用,从而在有限次采样中逼近最优解。
不同采集函数的收敛性表现各异。例如,期望改进(EI) 通过最大化目标函数值的期望改进,在目标函数 \(f(x)\) 满足 Lipschitz 连续的假设下,能够以次优级别的代价 \(\mathcal{O}(n^{-1/d})\) 收敛到全局最优值。置信上界(UCB) 则通过参数 \(\kappa\) 平衡探索和利用,适用于平滑目标函数,理论上也能够以次优速度收敛到全局最优点。相比之下,概率改进(PI) 更偏向利用策略,其目标是最大化目标函数改进的概率,但在探索性较低的情况下,收敛速度通常较慢.
目标函数的平滑性
是贝叶斯优化收敛性的基础假设.常见假设包括:
Lipschitz 连续性:
- 如果目标函数 \(f(x)\) 满足 Lipschitz 条件:\[|f(x) - f(x')| \leq L \|x - x'\|, \]则采集函数能够以次优速度找到全局最优值.
信息增益的收敛性
信息增益量化了通过采样获得的目标函数信息。对于高斯过程,信息增益 \(\gamma_n\) 满足:
其中 \(d\) 是输入空间的维度。信息增益的快速衰减表明,随着采样点数量增加,目标函数的不确定性逐渐减小.
在目标函数 \(f(x)\) 满足 Lipschitz 连续性和核函数满足 Mercer 定理的条件下,贝叶斯优化的序贯设计能够保证:随着 \(n \to \infty\),最优点的误差收敛到零;信息增益 \(\gamma_n\) 随 \(n\) 增加逐渐减小,且满足 \(\sum_{n=1}^\infty \gamma_n < \infty\).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号