一只简单的网络爬虫(基于linux C/C++)————socket相关及HTTP
socket相关
建立连接
网络通信中少不了socket,该爬虫没有使用现成的一些库,而是自己封装了socket的相关操作,因为爬虫属于客户端,建立套接字和发起连接都封装在build_connect中
//建立连接
int build_connect(int *fd, char *ip, int port)
{
struct sockaddr_in server_addr;
bzero(&server_addr, sizeof(struct sockaddr_in));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(port);//主机字节序转化为网络字节序
if (!inet_aton(ip, &(server_addr.sin_addr)))
{//ip转化为网络字节序ip地址
return -1;
}
if ((*fd = socket(PF_INET, SOCK_STREAM, 0)) < 0)
{//创建socket套接字
return -1;
}
if (connect(*fd, (struct sockaddr *)&server_addr, sizeof(struct sockaddr_in)) < 0)
{//连接
close(*fd);
return -1;
}
SPIDER_LOG(SPIDER_LEVEL_DEBUG,"连接建立成功:%s",ip);
return 0;
}build_connect(int *fd, char *ip, int port)中,ip和port都是通过url传递进去的,fd则是创建socket后通过指针传出来的。
可以使用下面的函数将socket设置为非阻塞模式
void set_nonblocking(int fd)
{//设置非阻塞模式
int flag;
if ((flag = fcntl(fd, F_GETFL)) < 0)
{
SPIDER_LOG(SPIDER_LEVEL_ERROR, "fcntl getfl fail");
}
flag |= O_NONBLOCK;
if ((flag = fcntl(fd, F_SETFL, flag)) < 0)
{
SPIDER_LOG(SPIDER_LEVEL_ERROR, "fcntl setfl fail");
}
}核心便是使用了该函数fcntl,可以用O_NONBLOCK设置。

如果linux的内核在2.6.27以上,则有另一个方式,如下图所示

socket函数的原型是
int socket(int domain, int type, int protocol);这里的type参数一般可以取如下的值
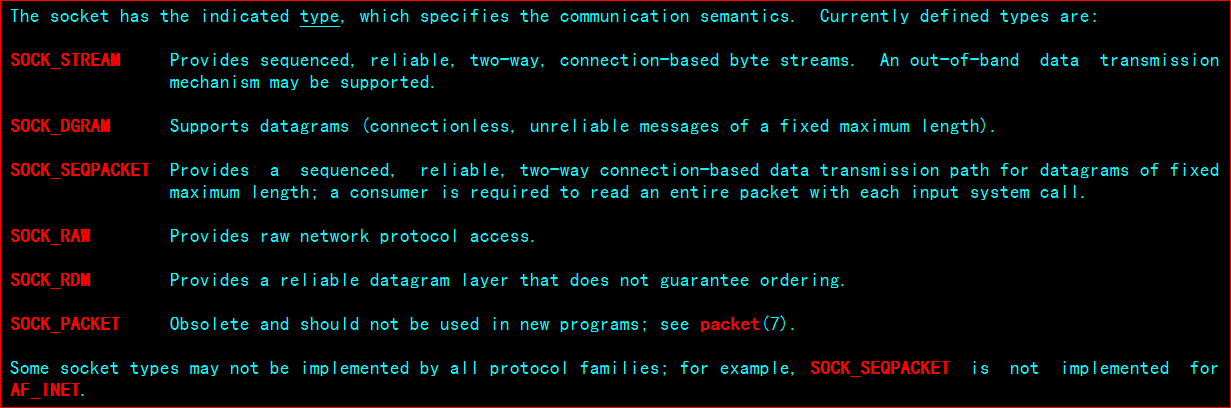
linux2.6.27以上的内核支持SOCK_NONBLOCK与SOCK_CLOEXEC,意味着可以使用如下的方法创建一个非阻塞的套接字,一气呵成。
int sockfd = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK | SOCK_CLOEXEC, 0);发送请求
发送请求主要使用write函数向socket文件描述符写东西,而爬虫的发送主要就是发送http请求,以便获取我们想要的资源
//发送http请求
int send_request(int fd, void *arg)
{
int need, begin, n;
char request[1024] = {0};
Url *url = (Url *)arg;
//打印下请求的信息
SPIDER_LOG(SPIDER_LEVEL_DEBUG,"url->path:%s",url->path);
SPIDER_LOG(SPIDER_LEVEL_DEBUG,"发出的请求域名url->domain:%s",url->domain);
//组成HTTP头部信息
sprintf(request, "GET /%s HTTP/1.0\r\n"
"Host: %s\r\n"
"Accept: */*\r\n"
"Connection: Keep-Alive\r\n"
"User-Agent: Mozilla/5.0 (compatible; Qteqpidspider/1.0;)\r\n"
"Referer: %s\r\n\r\n", url->path, url->domain, url->domain);
need = strlen(request);
begin = 0;
//向服务器发送请求
while(need)
{
n = write(fd, request+begin, need);//发送请求
if (n <= 0)
{
if (errno == EAGAIN)
{ //write buffer full, delay retry
usleep(1000);
continue;
}
SPIDER_LOG(SPIDER_LEVEL_WARN, "Thread %lu send ERROR: %d", pthread_self(), n);
free_url(url);
close(fd);
return -1;
}
begin += n;//起始点指针的偏移
need -= n;//直到发送完
}
return 0;
}
http请求将在下面谈。我们这里是将http请求写入request数组中,然后使用
n = write(fd, request+begin, need);//发送请求
进行发送,n返回的是写入的长度,然后每次将长度更新直到写完了为止。如果返回EAGAIN则稍作延时继续写
EAGAIN
在Linux环境下开发经常会碰到很多错误(设置errno),其中EAGAIN是其中比较常见的一个错误(比如用在非阻塞操作中)。
从字面上来看,是提示再试一次。这个错误经常出现在当应用程序进行一些非阻塞(non-blocking)操作(对文件或socket)的时候。例如,以O_NONBLOCK的标志打开文件/socket/FIFO,如果你连续做read操作而没有数据可读。此时程序不会阻塞起来等待数据准备就绪返回,read函数会返回一个错误EAGAIN,提示你的应用程序现在没有数据可读请稍后再试。
又例如,当一个系统调用(比如fork)因为没有足够的资源(比如虚拟内存)而执行失败,返回EAGAIN提示其再调用一次(也许下次就能成功)。
接收消息
接收消息采用read函数,我们先预先分配一个1M的空间用来接收
//一个HTML分配1M缓冲区
#define HTML_MAXLEN 1024*1024
void * recv_response(void * arg)
{//epollin事件到来就调用该函数解析
begin_thread();//这个函数只是打印线程自身的id
int i, n, trunc_head = 0, len = 0;
char * body_ptr = NULL;
evso_arg * narg = (evso_arg *)arg;
Response *resp = (Response *)malloc(sizeof(Response));
resp->header = NULL;
resp->body = (char *)malloc(HTML_MAXLEN);
resp->body_len = 0;
resp->url = narg->url;
//regex_t 是一个结构体数据类型,用来存放编译后的正则表达式,
//它的成员re_nsub 用来存储正则表达式中的子正则表达式的个数,
//子正则表达式就是用圆括号包起来的部分表达式。
regex_t re;
//int regcomp (regex_t *compiled, const char *pattern, int cflags)
//pattern 是指向我们写好的正则表达式的指针
if (regcomp(&re, HREF_PATTERN, 0) != 0)
{//compile error匹配错误
SPIDER_LOG(SPIDER_LEVEL_ERROR, "compile regex error");
}
//
SPIDER_LOG(SPIDER_LEVEL_INFO, "Crawling url: %s/%s", narg->url->domain, narg->url->path);
while(1)
{
// typedef struct Response {
// Header *header;
// char *body;//内容
// int body_len;//长度
// struct Url *url;//相关联的url
// } Response;
// what if content-length exceeds HTML_MAXLEN? 超过则会一直读啊,读到没有数据为止
//读取后放到 resp->body + len
n = read(narg->fd, resp->body + len, 1024);//得到返回数据
if (n < 0)
{
if (errno == EAGAIN || errno == EWOULDBLOCK || errno == EINTR)
{
// TODO: Why always recv EAGAIN?
// should we deal EINTR
//SPIDER_LOG(SPIDER_LEVEL_WARN, "thread %lu meet EAGAIN or EWOULDBLOCK, sleep", pthread_self());
usleep(100000);
continue;
}
//strerror返回:指向错误信息的指针即错误的描述字符串
SPIDER_LOG(SPIDER_LEVEL_WARN, "Read socket fail: %s", strerror(errno));
break;
}
else if (n == 0)
{//数据读完
// finish reading
resp->body_len = len;
if (resp->body_len > 0)
{//匹配正则表达式,如果是新的会加入原始的队列
//编译好的正则表达式,反馈体,原来的url
extract_url(&re, resp->body, narg->url);//该函数在url.cpp中
}
// deal resp->body 处理响应体
for (i = 0; i < (int)modules_post_html.size(); i++)
{
SPIDER_LOG(SPIDER_LEVEL_WARN, "保存文件");
modules_post_html[i]->handle(resp);//此模块就是保存html文件的
}
break;
}
else
{
//SPIDER_LOG(SPIDER_LEVEL_WARN, "read socket ok! len=%d", n);
len += n;//更新已经读取的长度
resp->body[len] = '\0';
if (!trunc_head)//还没有截去头部
{//strstr() 函数搜索一个字符串在另一个字符串中的第一次出现。
//找到所搜索的字符串,则该函数返回第一次匹配的字符串的地址;
//如果未找到所搜索的字符串,则返回NULL。
if ((body_ptr = strstr(resp->body, "\r\n\r\n")) != NULL) //头部于体相差两个\r\n
{
*(body_ptr+2) = '\0';//响应体
resp->header = parse_header(resp->body);//解析一下响应头,得到状态码还有类型
if (!header_postcheck(resp->header)) //用模块再次检测
{//这里经常出差
SPIDER_LOG(SPIDER_LEVEL_WARN, "goto leave");
goto leave; // modulues filter fail
}
trunc_head = 1;
// cover header
body_ptr += 4;//这部分对比网页的源码去看
for (i = 0; *body_ptr; i++) //保存内容
{
resp->body[i] = *body_ptr;
body_ptr++;
}
resp->body[i] = '\0';
len = i;//去除头部的操作应该是发生在第一次的
}
continue;
}
}
}
leave:
close(narg->fd); // close socket
free_url(narg->url); // free Url object
regfree(&re); // free regex object
// free resp
free(resp->header->content_type);
free(resp->header);
free(resp->body);
free(resp);
end_thread();//结束任务
return NULL;
}核心的接收函数如下:
n = read(narg->fd, resp->body + len, 1024);//得到返回数据n表示读取到的长度,n小于0表示错误,等于0表示数据读取完毕,读取完毕之后采用正则表达式解析页面,这个下次再谈。
HTTP
HTTP报文由从客户机到服务器的请求和从服务器到客户机的响应构成。请求报文格式如下:
请求行 - 通用信息头 - 请求头 - 实体头 - 报文主体
请求行以方法字段开始,后面分别是 URL 字段和 HTTP 协议版本字段,并以 CRLF 结尾。SP 是分隔符。除了在最后的 CRLF 序列中 CF 和 LF 是必需的之外,其他都可以不要。有关通用信息头,请求头和实体头方面的具体内容可以参照相关文件。
应答报文格式如下:
状态行 - 通用信息头 - 响应头 - 实体头 - 报文主体
状态码元由3位数字组成,表示请求是否被理解或被满足。原因分析是对原文的状态码作简短的描述,状态码用来支持自动操作,而原因分析用来供用户使用。客户机无需用来检查或显示语法。有关通用信息头,响应头和实体头方面的具体内容可以参照相关文件。
HTTP请求
下图给出了请求报文的一般格式

我们这里的爬虫以下面的HTTP请求为例
"GET /%s HTTP/1.0\r\n"
"Host: %s\r\n"
"Accept: */*\r\n"
"Connection: Keep-Alive\r\n"
"User-Agent: Mozilla/5.0 (compatible; Qteqpidspider/1.0;)\r\n"
"Referer: %s\r\n\r\n", url->path, url->domain, url->domain)HTTP响应
HTTP响应参考下面的例子
HTTP/1.1 200 OK
Date: Sat, 31 Dec 2005 23:59:59 GMT
Content-Type: text/html;charset=ISO-8859-1
Content-Length: 122
<html>
<head>
<title>Wrox Homepage</title>
</head>
<body>
<!-- body goes here -->
</body>
</html>在接收函数中,有一个函数用于解析HTTP的头部,如下
//解析反馈头
static Header * parse_header(char *header)
{
int c = 0; // typedef struct Header {
// char *content_type;//文件类型
// int status_code;//状态码
// } Header;
char *p = NULL;
char **sps = NULL;
char *start = header;
Header *h = (Header *)calloc(1, sizeof(Header));
//找到\r\n第一次出现的地方
if ((p = strstr(start, "\r\n")) != NULL)
{//第一行应该是HTTP/1.0 200 OK\r\n,'\r\n'只是一个字节
*p = '\0';
sps = strsplit(start, ' ', &c, 2);//按空格分隔字符串,分隔3次
if (c == 3)
{
h->status_code = atoi(sps[1]);//保存状态码
}
else
{
h->status_code = 600; //给个自己的错误码
}
start = p + 2;
}
while ((p = strstr(start, "\r\n")) != NULL)
{
*p = '\0';
sps = strsplit(start, ':', &c, 1);//以冒号分隔
if (c == 2)
{
if (strcasecmp(sps[0], "content-type") == 0)//查找内容的类型
{
h->content_type = strdup(strim(sps[1]));
}
}
start = p + 2;
}
return h;
}这里获取了状态码还有内容的类型,接着其实是接收体将HTTP头部覆盖了,因此最后的Response结构体的body其实只是保存了内容。
在学习HTTP相关的东西时,可以使用浏览器方便的查看一些必要的信息,例如
使用鼠标右键
点审查元素,可以看到很多的内容
Network——>可以看到头部等等的信息,这在学习的时候有助于我们更好地理解
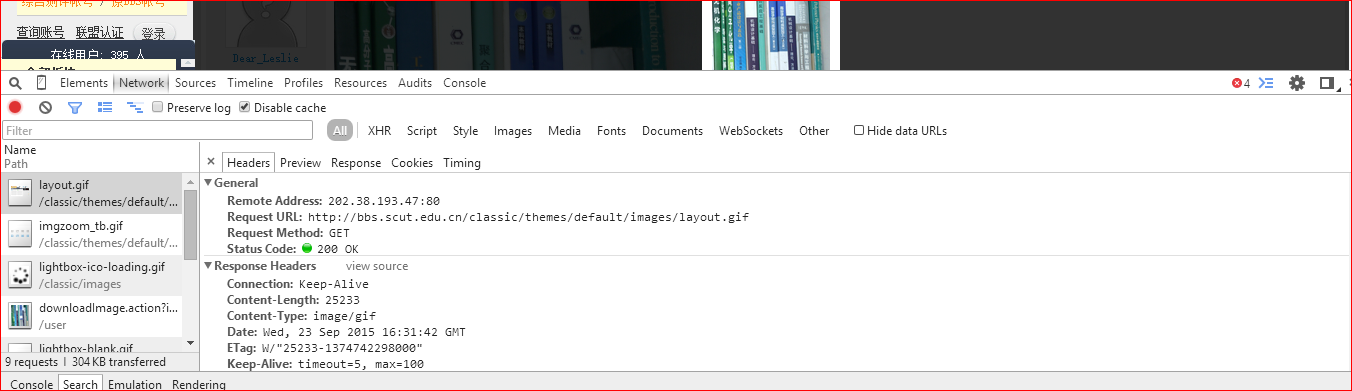
更过的HTTP相关内容可以参考这里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号