
一种关系数据库实现的Tree数据结构
一种关系数据库实现的Tree数据结构
1.概述
在多个项目中需要使用Tree数据结构来操作与保持数据(如单位结构、嵌套表格),通常可以使用XML文件或关系数据库对Tree进行保存于操作,两者的选取可依据以下约束:
l 数据访问的并发性:是否存在不同用户对Tree中的不同字段有并发读写操作;
l 数据的依赖关系:是否存在其它数据对Tree结构中的字段的依赖关系;
l 数据处理的复杂度:是否需要对Tree中的字段进行复杂处理(如统计);
如果对以上三个问题回答是,应考虑擦用关系数据库,否则应考虑XML文件。下面介绍一种在项目中常使用的一种关系数据库实现的Tree数据结构。
2.数据结构
树由节点构成,每个节点包含三个字段:ID、NAME和VALUE。在数据库中建立一张节点表NODE,表结构包含此三个字段,表中的一行描述了一个节点。节点的ID为字符串类型,用于描述树的结构,下面以MySQL数据库为例,给出一个例子。
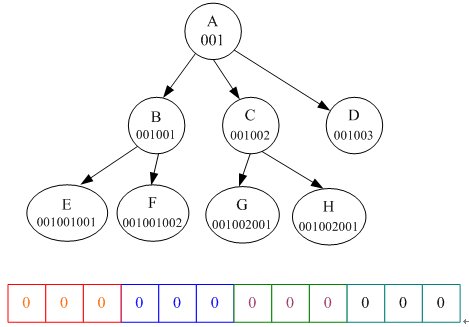
该列子中,一个ID包含多个段,每段3个字节。一个段表示一个层。在第一层的节点有3个字节,在第2层的节点有6个字节,依次类推。每层3位字节,在一层中可描述1千个节点。
3.数据操作
3.1节点的添加
输入:父节点的ID
输出:创建节点的ID
操作流程:(以在002节点下创建新节点为例)
1)找到父节点下的最大节点
SELECT RIGHT(id,3) AS id FROM node WHERE id LIKE '002___' order by id desc limit 0,1 ";
2)将最大节点加1后设置为新创建的节点ID
3.2查询当前节点的直接子孙
输入:上层节点ID
输出:下层节点ID的列表
操作流程:(以在002节点为例)
select id from node WHERE id like '002___'
3.3查询所有祖先节点
根据ID可直接获得所有祖先的ID。
3.4删除节点(级联操作)
输入:删除节点的ID
操作流程:(以删除002节点为例子)
delete from node where id like ’002%’
3.5节点的移动(级联操作)
输入:目的父节点ID
输出:新的当前节点
操作流程:(以002节点移动到003节点下为例)
UPDATE NODE SET ID = CONCAT('003',RIGHT(NODE,length(b)-3)) WHERE NODE LIKE '002%';


