模型性能评估
模型性能评估是为了评价模型的泛化能力,模型性能评估主要有两个问题要解决:
1)用什么数据来评估?
2)用什么标准来评估?
下面的第一节内容主要解答用什么数据来评估模型的性能,第二节解答用什么标准来评估。
1.用什么数据来评估模型性能
常用的有3中,按照复杂程度程度排序分别为:
1)训练集+测试集
2)holdout方法
3)K折交叉验证
其中第1种方法是用测试集来评估模型的性能;第二种方法是用验证集+测试集来评估,验证集用于训练过程中的评估,测试集用于最终的评估;第3种方法也是用验证集+测试集的方式,但是不同于第2种,在k折交叉验证方法下验证集是不重复的,且一次训练会得到k个模型。
1.1 训练集+测试集
最简单的方法,就是将数据集按比例分为训练集和测试集,训练集用来训练模型,测试集用来测试模型性能;
优点:简洁,易操作;
缺点:鲁棒性差,可能存在性能评估失真和过拟合情况;(原因:重复使用同一组测试集来评估,意味这测试集也在间接的参与模型训练,那么测试集有又当运动员又当裁判的风险)
scikit-learn库中的model_selection模块下提供了train_test_split方法,专门用于这种方式的数据集划分;
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
参数中的test_size是指测试集占全部数据的比例。
1.2 holdout方法
该方法是机器学习模型泛化性能的一个经典且常用的方法;
holdout方法是在前一种方法的基础上改进而来,它把数据集划分为3个部分:1)训练集,2)验证集,3)测试集;
在模型训练和参数调优阶段,只使用验证集对模型做性能评估,在训练的过程中选择那些在训练集和验证集上表现都良好的模型,最后才在测试集上对模型性能进行泛化评估;这样会大大减少测试集使用的次数,减少过拟合的风险。
优点:降低模型过拟合风险;
缺点:模型性能对训练集数据划分为训练及验证子集的方法是敏感的,评价结果会随样本的不同而发生变化。
1.3 K折交叉验证
在k折交叉验证方法中,我们将不重复并随机的将训练数据划分为k个,其中k-1个用于模型的训练,剩下一个用于模型的测试,重复此过程k次,得到k个模型以及其性能评价;
一般过程如下:
1)选择一套超参,进行K折交叉验证,记录此套超参在K折交叉验证下的性能评价(一般是K个模型的性能评价的平均);
2)更换超参,继续1)步骤中的方法;
3)所有超参完成训练;
4)选取其中表现最好的超参数,使用这套超参值在所有的训练集上重新训练模型;
5)使用独立的测试集对最终的模型进行测试评价;
该方法的重点是:无重复抽样,即将数据集划分为k个之后,每次选择不同的块作为交叉验证中的验证集,保证不会有重复的验证集。
scikit-learn库中的model_selection模块中有StratifiedKFold类,可以方便的进行操作:
import numpy as np
from sklearn.model_selection import StratifiedKFold
X = np.array([\
[1,2],\
[3,4],\
[1,3],\
[2,4],\
[2,3],
[1,4],
])
y = np.array([0,0,0,1,1,1])
skf = StratifiedKFold(n_splits=3)
for train_index,valid_index in skf.split(X,y):
print("train:",train_index,"valid:",valid_index)
X_train,X_valid = X[train_index],X[valid_index]
y_train,y_valid = y[train_index],y[valid_index]
创建类时传入的n_split参数代表k折中的k;
执行结果如下:

2.用什么标准来评价模块性能的好坏
在分类模型中,最常用评价标准就是错误率;但是除了错误率,还有准确率,召回率,F1分数等评价指标,在不同的应用场景下,不同的评价指标可能会带来更好的效果;在介绍这些指标之前先介绍它们的基础--混淆矩阵;
2.1 混淆矩阵(confusion matrix)
混淆矩阵是一个简单的方阵,用于显示一个分类器的分类效果;
如下图所示:
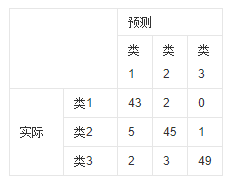
为简化叙述,下面以二分类模型来描述:
在二分类中模型中,有4个变量:1)真正(true positive),2)真负(true negative),3)假正(false positive),4)假负(false negative);这4个变量分布如下图,变量值代表属于此类的数据个数。

scikit-learn库中的metrics模块中有confusion_matrix方法,可以直接调用此方法来生成混淆矩阵:
from sklearn.metrics import confusion_matrix confmat = confusion_matrix(y_true=y_test,y_pred=y_pred)
confusion_matrix方法中的参数分别为实际测试样本的类标以及使用模型预测出来测试样本的类标。
2.2 分类模型的准确率与召回率
这里定义了3个不同的评价指标,根据实际应用需要可以选择其中合适的指标作为模型评价标准,或者通过组合变换实现更复杂的评价指标。
准确率:预测为正的数据中实际为正的比率;$PRE = \frac{TP}{TP+FP}$;
召回率:实际为正的样本被预测正确的比率;$REC=\frac{TP}{TP+FN}$;
F1分数:$F1=2\frac{PRE\times REC}{PRE+REC}$
scikit-learn库中的metrics模块中有precision_score,recall_score,f1_score方法,使用方法与confusion_matrix相同。
这些指标都只是参考,有需要的话可以自己订制指标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号