
《Python数据科学手册》抄书笔记,第二章: NumPy入门
NumPy入门
NumPy为Numerical Python的简写。
2.1 理解Python中的数据类型
Python中,类型是动态推断的。这意味着可以将任何类型的数据指定给任何变量
Python变量不仅是它们的值,还包括了关于值的类型的一些额外信息。
2.1.1Python整型不仅仅是一个整型
Python的一个整数对象实际包括
ob_refcnt是一个引用计数,它帮助Python默默的处理内存的分配和回收
ob_type将保存对象的类型编码
ob_size指定接下来的数据成员的大小
ob_digit包含Python变量表示的实际整数值

C语言整型本质上是对应某个内存位置的标签,里面存储的字节会编码成整形。而Python的整形其实是一个指针,指向包含这个Python对象所有信息的某个内存位置,其中包括可以转成整型的字节。
2.1.2Python列表不仅仅是一个列表
Python列表中的每一项必须包含各自的类型信息、引用计数和其它信息;也就是说,每一项都是一个完整的Python对象。
一个特殊的例子,如果列表中的所有变量都是同一类型的,那么很多信息都是多余的,将数据存储在固定类型的数组中应该更加高效
在实现层面,数组基本上包含一个指向连续数据块的指针。另一方面,Python列表包含一个指向指针块的指针,这其中的每一个指针对应一个完整的Python对象。
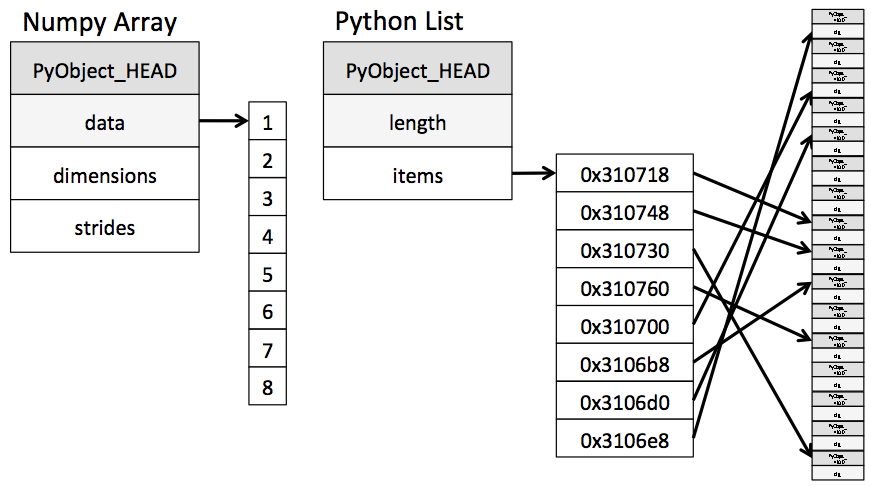
2.1.3Python中的固定类型数组
Python内置的array也可以新建数组,只不过功能比较少
In [23]: import array
In [24]: L = list(range(10))
In [25]: A = array.array('i',L)
In [26]: A
Out[26]: array('i', [0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [27]:
2.1.4 从Python列表中创建数组
数组的几种创建方式
In [27]: np.array([1,4,2,5])
Out[27]: array([1, 4, 2, 5])
In [28]: np.array([1,4,2,5,3.14])
Out[28]: array([1. , 4. , 2. , 5. , 3.14])
In [29]: np.array([1,2,3,4], dtype='float32')
Out[29]: array([1., 2., 3., 4.], dtype=float32)
In [30]: np.array([range(i,i+3) for i in range(2,7,2)])
Out[30]:
array([[2, 3, 4],
[4, 5, 6],
[6, 7, 8]])
In [31]:
创建的几种方式,可以指定dtype,然后如果存在不同的数据类型,向上进行转换。
2.1.5从头创建数组
面对大型数组的时候,用NumPy内置的方法从头创建数组
In [31]: np.zeros(10)
Out[31]: array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
In [32]: np.zeros(10,dtype=int)
Out[32]: array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
In [33]: np.ones((3,5),dtype=float)
Out[33]:
array([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
In [34]: np.full((3,5),3.14)
Out[34]:
array([[3.14, 3.14, 3.14, 3.14, 3.14],
[3.14, 3.14, 3.14, 3.14, 3.14],
[3.14, 3.14, 3.14, 3.14, 3.14]])
In [35]: np.arange(0,20,2)
Out[35]: array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18])
In [36]: np.linspace(0,1,5)
Out[36]: array([0. , 0.25, 0.5 , 0.75, 1. ])
In [37]: np.random.random(3)
Out[37]: array([0.59732559, 0.97842076, 0.18632508])
In [38]: np.random.random((3,3))
Out[38]:
array([[0.25772402, 0.09483585, 0.27354778],
[0.11003305, 0.83146282, 0.76717386],
[0.39212032, 0.56728285, 0.24272047]])
In [39]: np.random.normal(0,1,(3,3))
Out[39]:
array([[-0.89497281, -0.54395099, -1.11471111],
[ 2.27626402, -0.93851257, 0.58283954],
[ 0.74913593, -0.35278492, 0.18887886]])
In [40]: np.random.randint(0,10,(3,3))
Out[40]:
array([[1, 5, 2],
[2, 3, 6],
[0, 9, 2]])
In [41]: np.eye(3)
Out[41]:
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
In [42]: np.empty(3)
Out[42]: array([1., 1., 1.])
In [43]: np.full(3,1)
Out[43]: array([1, 1, 1])
2.1.6NumPy标准数据类型
当构建一个数组的时候,类型可以
np.zeros(10, dtype='int16')这样进行标注
np.zeros(10, dtype=np.int16)上面那种也可以,两种都可以
Data type Description bool_ Boolean (True or False) stored as a byte int_ Default integer type (same as C long; normally either int64 or int32) intc Identical to C int (normally int32 or int64) intp Integer used for indexing (same as C ssize_t; normally either int32 or int64) int8 Byte (-128 to 127) int16 Integer (-32768 to 32767) int32 Integer (-2147483648 to 2147483647) int64 Integer (-9223372036854775808 to 9223372036854775807) uint8 Unsigned integer (0 to 255) uint16 Unsigned integer (0 to 65535) uint32 Unsigned integer (0 to 4294967295) uint64 Unsigned integer (0 to 18446744073709551615) float_ Shorthand for float64. float16 Half precision float: sign bit, 5 bits exponent, 10 bits mantissa float32 Single precision float: sign bit, 8 bits exponent, 23 bits mantissa float64 Double precision float: sign bit, 11 bits exponent, 52 bits mantissa complex_ Shorthand for complex128. complex64 Complex number, represented by two 32-bit floats complex128 Complex number, represented by two 64-bit floats
上面是全部的数据类型
2.2.1 NumPy数组的属性
通过ndim(数组的维度), shape(数组的每个维度的大小),size(数组的总大小)属性
In [18]: x3
Out[18]:
array([[[8, 1, 5, 9, 8],
[9, 4, 3, 0, 3],
[5, 0, 2, 3, 8],
[1, 3, 3, 3, 7]],
[[0, 1, 9, 9, 0],
[4, 7, 3, 2, 7],
[2, 0, 0, 4, 5],
[5, 6, 8, 4, 1]],
[[4, 9, 8, 1, 1],
[7, 9, 9, 3, 6],
[7, 2, 0, 3, 5],
[9, 4, 4, 6, 4]]])
In [19]: print(x3.ndim,x3.shape,x3.size)
3 (3, 4, 5) 60
In [20]:
通过dtype属性来输出类型
In [20]: x3.dtype
Out[20]: dtype('int64')
In [21]:
通过itemsize表示每个数组成员的字节大小,以及nbytes表示所有数组成员的总字节大小
In [21]: x3.itemsize Out[21]: 8 In [22]: x3.nbytes Out[22]: 480 In [23]:
2.2.2数组索引:获取单个元素
一维数组的操作跟Python的列表差不多
In [23]: x1 Out[23]: array([5, 0, 3, 3, 7, 9]) In [24]: x1[0] Out[24]: 5 In [25]: x1[4] Out[25]: 7 In [26]: x1[-1] Out[26]: 9 In [27]: x1[-1] Out[27]: 9 In [28]: x1[-2] Out[28]: 7 In [29]:
多维数组的操作
In [29]: x2
Out[29]:
array([[3, 5, 2, 4],
[7, 6, 8, 8],
[1, 6, 7, 7]])
In [30]: x2[0][0]
Out[30]: 3
In [31]: x2[0,0]
Out[31]: 3
In [32]: x2[-1,-1]
Out[32]: 7
In [33]:
如果要改变数值,可以直接进行赋值操作
In [34]: x2
Out[34]:
array([[3, 5, 2, 4],
[7, 6, 8, 8],
[1, 6, 7, 7]])
In [35]: x2[0,0]=12
In [36]: x2
Out[36]:
array([[12, 5, 2, 4],
[ 7, 6, 8, 8],
[ 1, 6, 7, 7]])
NumPy数组是固定类型的。这意味着当你试图将一个浮点值插入一个整形数组时,浮点值会被截短成整形。这截短是自动完成的,不会给你提示或警告。
In [37]: x1 Out[37]: array([5, 0, 3, 3, 7, 9]) In [38]: x1[0]=3.14 In [39]: x1 Out[39]: array([3, 0, 3, 3, 7, 9]) In [40]:
2.2.3数组的切片:获取字数组
NumPy的切片语法于Python列表的标准切片语法相同。
为了获取数组x的一个切片,可以用以下方式
x[start:stop:step] 如果三个参数都未指定,那么它们会被分别设置默认值start=0,stop=0,step=1.
一维子数组
In [47]: x= np.array(range(10)) In [48]: x Out[48]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) In [49]: x[:5] Out[49]: array([0, 1, 2, 3, 4]) In [50]: x[5:] Out[50]: array([5, 6, 7, 8, 9]) In [51]: x[4:7] Out[51]: array([4, 5, 6]) In [52]: x[::2] Out[52]: array([0, 2, 4, 6, 8]) In [53]: x[1::2] Out[53]: array([1, 3, 5, 7, 9]) In [54]:
步长为负数的时候,其实start于stop是交换了位置的,因此可以很方便的取逆序数组的方式
In [54]: x Out[54]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) In [55]: x[::-1] Out[55]: array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0]) In [56]: x[5:2:-1] Out[56]: array([5, 4, 3]) In [57]:
2多维子数组
多维切片也采用同样的方式处理,用逗号分隔。
In [59]: x2
Out[59]:
array([[12, 5, 2, 4],
[ 7, 6, 8, 8],
[ 1, 6, 7, 7]])
In [60]: x2[:2,:3]
Out[60]:
array([[12, 5, 2],
[ 7, 6, 8]])
In [61]: x2[:3,::2]
Out[61]:
array([[12, 2],
[ 7, 8],
[ 1, 7]])
In [62]: x2[::-1,::-1]
Out[62]:
array([[ 7, 7, 6, 1],
[ 8, 8, 6, 7],
[ 4, 2, 5, 12]])
In [63]:
操作其实跟1维差不多,就是多一个逗号
3 获取数组的行和列
用一个冒号表示空切片,我的理解也可以认为全选。
In [63]: x2
Out[63]:
array([[12, 5, 2, 4],
[ 7, 6, 8, 8],
[ 1, 6, 7, 7]])
In [64]: x2[:,:]
Out[64]:
array([[12, 5, 2, 4],
[ 7, 6, 8, 8],
[ 1, 6, 7, 7]])
In [65]: x2[:,0]
Out[65]: array([12, 7, 1])
In [66]: x2[0,:]
Out[66]: array([12, 5, 2, 4])
In [67]: x2[0]
Out[67]: array([12, 5, 2, 4])
In [68]:
如果取行的话,可以省略后面的:(冒号)
4非副本视图的子数组
数组的切片返回的数组数据的视图,而不是数值的副本。Python中是浅拷贝
In [76]: x2
Out[76]:
array([[12, 5, 2, 4],
[ 7, 6, 8, 8],
[ 1, 6, 7, 7]])
In [77]: x2_sub=x2[:2,:2]
In [78]: x2_sub
Out[78]:
array([[12, 5],
[ 7, 6]])
In [79]: x2_sub[0,0]=99
In [80]: x2
Out[80]:
array([[99, 5, 2, 4],
[ 7, 6, 8, 8],
[ 1, 6, 7, 7]])
In [81]:
这种默认的处理方式实际上非常有用:它意味着在处理非常大的数据集时,可以获取或处理这些数据集的片段,而不用复制底层的数据缓存。
5.创建数组的副本
.copy的方法实现
In [81]: x2_sub_copy = x2[:2,:2].copy()
In [82]: x2_sub_copy
Out[82]:
array([[99, 5],
[ 7, 6]])
In [83]: x2_sub_copy[0,0]=42
In [84]: x2_sub_copy
Out[84]:
array([[42, 5],
[ 7, 6]])
In [85]: x2
Out[85]:
array([[99, 5, 2, 4],
[ 7, 6, 8, 8],
[ 1, 6, 7, 7]])
2.2.4 数组的变形
通过reshape来可以改变维度,也可以通过np.newaxis来添加维度
In [96]: gird = np.arange(1,10).reshape(3,3)
In [97]: gird
Out[97]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
In [98]:
下面可以看到reshape于np.newaxis输出相同的效果
In [98]: x = np.arange(1,4)
In [99]: x
Out[99]: array([1, 2, 3])
In [100]: x.reshape(1,3)
Out[100]: array([[1, 2, 3]])
In [101]: x[np.newaxis,:]
Out[101]: array([[1, 2, 3]])
In [102]: x.reshape(3,1)
Out[102]:
array([[1],
[2],
[3]])
In [103]: x[:,np.newaxis]
Out[103]:
array([[1],
[2],
[3]])
In [104]:
np.newaxis添加在哪个位置,就会添加一个维度
2.2.5 数组拼接和分裂
1.数组的拼接
In [123]: x Out[123]: array([1, 2, 3]) In [124]: y Out[124]: array([4, 3, 2]) In [125]: np.concatenate([x,y]) Out[125]: array([1, 2, 3, 4, 3, 2]) In [126]: z=np.full(3,99) In [127]: np.concatenate([x,y,z]) Out[127]: array([ 1, 2, 3, 4, 3, 2, 99, 99, 99]) In [128]:
concatenate默认沿着第一轴拼接,通过调整axis来设置拼接的轴方向
In [133]: np.concatenate([gird,gird])
Out[133]:
array([[1, 2, 3],
[4, 5, 6],
[1, 2, 3],
[4, 5, 6]])
In [134]: np.concatenate([gird,gird],axis=1)
Out[134]:
array([[1, 2, 3, 1, 2, 3],
[4, 5, 6, 4, 5, 6]])
使用np.vstack(垂直栈)
- vertical
np.hstack(水平栈)
函数更加方便
In [140]: gird
Out[140]:
array([[9, 8, 7],
[6, 5, 4]])
In [141]: x
Out[141]: array([1, 2, 3])
In [142]: np.vstack([x,gird])
Out[142]:
array([[1, 2, 3],
[9, 8, 7],
[6, 5, 4]])
In [143]: y = np.array([[99],[99]])
In [144]: np.hstack([gird,y])
Out[144]:
array([[ 9, 8, 7, 99],
[ 6, 5, 4, 99]])
In [145]:
可以看出np.vstack于np.concatenate的默认参数拼接一样,np.hstack于np.concatenate中axis为1参数的拼接效果一样
2数组的分裂
分裂有np.split, np.vsplit, np.hsplit
In [145]: x = np.random.random(9)
In [146]: x
Out[146]:
array([0.65279032, 0.63505887, 0.99529957, 0.58185033, 0.41436859,
0.4746975 , 0.6235101 , 0.33800761, 0.67475232])
In [147]: x1,x2,x3=np.split(x,[3,5])
In [148]: print(x1,x2,x3)
[0.65279032 0.63505887 0.99529957] [0.58185033 0.41436859] [0.4746975 0.6235101 0.33800761 0.67475232]
In [149]:
后面的坐标点为切割点,取头不取尾,N个点得到N+1个子数组
In [154]: grid
Out[154]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
In [155]: upper,lower = np.vsplit(grid, [2])
In [156]: upper
Out[156]:
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
In [157]: lower
Out[157]:
array([[ 8, 9, 10, 11],
[12, 13, 14, 15]])
In [158]: left, right = np.split(grid,[2],axis=1)
In [159]: left
Out[159]:
array([[ 0, 1],
[ 4, 5],
[ 8, 9],
[12, 13]])
In [160]: right
Out[160]:
array([[ 2, 3],
[ 6, 7],
[10, 11],
[14, 15]])
In [163]: left, right = np.hsplit(grid,[2])
In [164]: left
Out[164]:
array([[ 0, 1],
[ 4, 5],
[ 8, 9],
[12, 13]])
In [165]: right
Out[165]:
array([[ 2, 3],
[ 6, 7],
[10, 11],
[14, 15]])
2.3NumPy数组的计算:通用函数
NumPy变快的关键是利用向量化操作,通常在NumPy的通用函数(ufunc)中实现。
2.3.1缓慢的循环
In [171]: %paste
import numpy as np
np.random.seed(0)
def compute_reciprocals(values):
output = np.empty(len(values))
for i in range(len(values)):
output[i] = 1.0 / values[i]
return output
values = np.random.randint(1, 10, size=5)
compute_reciprocals(values)
## -- End pasted text --
Out[171]: array([0.16666667, 1. , 0.25 , 0.25 , 0.125 ])
In [172]: big_array = np.random.randint(1,100,size=1000000)
In [173]: %timeit compute_reciprocals(big_array)
1.8 s ± 25.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [174]: %time compute_reciprocals(big_array)
CPU times: user 1.83 s, sys: 1.45 ms, total: 1.83 s
Wall time: 1.83 s
Out[174]:
array([0.1 , 0.01190476, 0.04545455, ..., 0.01428571, 0.01098901,
0.01149425])
In [175]:
运行100万次的速度慢的可以,这里的处理瓶颈并不在运算本身,而在Cpython在每次循环中必须做数据类型的检查和函数的调用。
每次进行倒数运算时,Python首先检查对象的类型,并且动态查找可以使用该数据类型的正确函数。
如果我们在编译代码时进行这样的操作,那么就能在代码执行之前知晓类型的声明,结果的计算也会更加有效率
2.3.2通用函数介绍
NumPy为很多类型的操作提供了非常方便的、静态类型的、可编译程序的接口,也被称作向量操作。
In [175]: print(compute_reciprocals(values)) [0.16666667 1. 0.25 0.25 0.125 ] In [176]: print(1.0/values) [0.16666667 1. 0.25 0.25 0.125 ] In [177]:
第二种方法就是向量操作。
In [177]: %timeit (1.0/big_array) 947 µs ± 25.5 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
速度快了太多了。
NumPy中的向量操作是通过通用函数实现的。通用函数的主要目的是对NumPy数组中的值执行更快的重复操作。
In [178]: np.arange(5)/np.arange(1,6) Out[178]: array([0. , 0.5 , 0.66666667, 0.75 , 0.8 ]) In [179]:
多维数组的操作
In [179]: x = np.arange(9).reshape(3,3)
In [180]: 2**x
Out[180]:
array([[ 1, 2, 4],
[ 8, 16, 32],
[ 64, 128, 256]])
In [181]:
2.3.3 探索NumPy的通用函数
1.数组的运算
NumPy通用函数的使用方式非常自然,因为它用到了Python原生的算术运算符。
In [182]: x =np.arange(4) In [183]: x Out[183]: array([0, 1, 2, 3]) In [184]: x+5 Out[184]: array([5, 6, 7, 8]) In [185]: x-5 Out[185]: array([-5, -4, -3, -2]) In [186]: x*2 Out[186]: array([0, 2, 4, 6]) In [187]: x/2 Out[187]: array([0. , 0.5, 1. , 1.5]) In [188]: x//2 Out[188]: array([0, 0, 1, 1]) In [189]: -x Out[189]: array([ 0, -1, -2, -3]) In [190]: x**2 Out[190]: array([0, 1, 4, 9]) In [191]: 2**x Out[191]: array([1, 2, 4, 8]) In [192]: x%2 Out[192]: array([0, 1, 0, 1]) In [193]: -(0.5*x+1) **2 Out[193]: array([-1. , -2.25, -4. , -6.25])
基本Python的一元操作符,在NumPy中都可以使用。
所有这些算术运算符都是NumPy内置函数的简单封装器
In [194]: x+2 Out[194]: array([2, 3, 4, 5]) In [195]: np.add(x,2) Out[195]: array([2, 3, 4, 5])
| perator | Equivalent ufunc | Description |
|---|---|---|
+ |
np.add |
Addition (e.g., 1 + 1 = 2) |
- |
np.subtract |
Subtraction (e.g., 3 - 2 = 1) |
- |
np.negative |
Unary negation (e.g., -2) |
* |
np.multiply |
Multiplication (e.g., 2 * 3 = 6) |
/ |
np.divide |
Division (e.g., 3 / 2 = 1.5) |
// |
np.floor_divide |
Floor division (e.g., 3 // 2 = 1) |
** |
np.power |
Exponentiation (e.g., 2 ** 3 = 8) |
% |
np.mod |
Modulus/remainder (e.g., 9 % 4 = 1) |
2绝对值
NumPy能理解Python内置的运算操作,也能够理解绝对值函数
In [198]: x= np.arange(-2,4) In [199]: x Out[199]: array([-2, -1, 0, 1, 2, 3]) In [200]: abs(x) Out[200]: array([2, 1, 0, 1, 2, 3])
In [201]: np.absolute(x) Out[201]: array([2, 1, 0, 1, 2, 3]) In [202]: np.abs(x) Out[202]: array([2, 1, 0, 1, 2, 3])
3.三角函数
首先定义角度
In [218]: theta = np.linspace(0,np.pi,3) In [219]: theta Out[219]: array([0. , 1.57079633, 3.14159265]) In [220]:
pi代码角度180度,不同的数值比例,代码不同的角度
In [220]: print("theta = ", theta)
...: print("sin(theta) = ", np.sin(theta))
...: print("cos(theta) = ", np.cos(theta))
...: print("tan(theta) = ", np.tan(theta))
theta = [0. 1.57079633 3.14159265]
sin(theta) = [0.0000000e+00 1.0000000e+00 1.2246468e-16]
cos(theta) = [ 1.000000e+00 6.123234e-17 -1.000000e+00]
tan(theta) = [ 0.00000000e+00 1.63312394e+16 -1.22464680e-16]
逆三角函数的使用
In [221]: x = [-1, 0, 1]
...: print("x = ", x)
...: print("arcsin(x) = ", np.arcsin(x))
...: print("arccos(x) = ", np.arccos(x))
...: print("arctan(x) = ", np.arctan(x))
x = [-1, 0, 1]
arcsin(x) = [-1.57079633 0. 1.57079633]
arccos(x) = [3.14159265 1.57079633 0. ]
arctan(x) = [-0.78539816 0. 0.78539816]
4 指数和对数
指数操作
In [222]: x = [1, 2, 3]
...: print("x =", x)
...: print("e^x =", np.exp(x))
...: print("2^x =", np.exp2(x))
...: print("3^x =", np.power(3, x))
x = [1, 2, 3]
e^x = [ 2.71828183 7.3890561 20.08553692]
2^x = [2. 4. 8.]
3^x = [ 3 9 27]
指数的逆运算,即对数运算。
In [223]: x = [1, 2, 4, 10]
...: print("x =", x)
...: print("ln(x) =", np.log(x))
...: print("log2(x) =", np.log2(x))
...: print("log10(x) =", np.log10(x))
x = [1, 2, 4, 10]
ln(x) = [0. 0.69314718 1.38629436 2.30258509]
log2(x) = [0. 1. 2. 3.32192809]
log10(x) = [0. 0.30103 0.60205999 1. ]
还有一些特殊的版本,对于非常小的输入值可以保持较好的精度:
In [224]: x = [0, 0.001, 0.01, 0.1]
...: print("exp(x) - 1 =", np.expm1(x))
...: print("log(1 + x) =", np.log1p(x))
exp(x) - 1 = [0. 0.0010005 0.01005017 0.10517092]
log(1 + x) = [0. 0.0009995 0.00995033 0.09531018]
当x的值很小时,以上函数给出的值比np.log和np.exp的计算更精准。
5专用的通用函数
...等用到的时候再回头看,
有一些更加晦涩的数学计算,scipy.specical可能包含了你需要的计算函数。
2.3.4高级的通用函数特性
1指定输出
In [228]: x = np.arange(5) In [229]: y= np.empty(5) In [230]: np.multiply(x,10,out=y) Out[230]: array([ 0., 10., 20., 30., 40.]) In [231]: print(y) [ 0. 10. 20. 30. 40.] In [232]: y = np.empty(10) In [233]: np.multiply(x,10,out=y) --------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-233-2d5db0a1fb2e> in <module> ----> 1 np.multiply(x,10,out=y) ValueError: operands could not be broadcast together with shapes (5,) () (10,)
指定输出需要指定输出的元素量要一致。
In [234]: y= np.zeros(10,dtype=np.float) In [235]: np.power(2,x,out=y[::2]) Out[235]: array([ 1., 2., 4., 8., 16.]) In [236]: print(y) [ 1. 0. 2. 0. 4. 0. 8. 0. 16. 0.]
如果这里谢的是y[::2] = 2**x,那么结果将是创建一个临时数组,该数组存放的是2**x的结果,并且接下来会将这些值复制到y数组中。对于较大的数组,通过使用out参数能够有效节约内存。
2聚合
reduce重复操作
In [237]: x = np.arange(1,6) In [238]: np.add.reduce(x) Out[238]: 15 In [239]: np.multiply.reduce(x) Out[239]: 120
如果要存储每次计算的中间结果,可以使用accumulate
In [240]: np.add.accumulate(x) Out[240]: array([ 1, 3, 6, 10, 15]) In [241]: np.multiply.accumulate(x) Out[241]: array([ 1, 2, 6, 24, 120])
3外积
任何通用函数都可以用outer方法获得两个不同输入数组所有元素对的函数运算结果。
In [256]: x
Out[256]: array([1, 2, 3, 4, 5])
In [257]: y
Out[257]: array([0, 1, 2])
In [258]: np.multiply.outer(x,y)
Out[258]:
array([[ 0, 1, 2],
[ 0, 2, 4],
[ 0, 3, 6],
[ 0, 4, 8],
[ 0, 5, 10]])
In [259]:
变成了二维数组,前面一个数组内的参数对第二个参数的数组进行操作,每个元素为第一个参数内的每一个元素.
2.4 聚合:最小值、最大值和其他值
2.4.1数组值求和
In [263]: big_array = np.random.random(1000000) In [264]: %timeit sum(big_array) 131 ms ± 1.45 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) In [265]: %timeit np.sum(big_array) 216 µs ± 3.51 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
np.sum的速度快太多了
2.4.2最小值和最大值
In [267]: %timeit min(big_array) 79.4 ms ± 1.52 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) In [268]: %timeit np.min(big_array) 255 µs ± 4.13 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
同样np.min于np.max都要快很多。
对于min,max,sum等其他NumPy绝喝,可以直接调用array对象的该方法
In [269]: print(big_array.min(), big_array.max(), big_array.sum()) 7.071203171893359e-07 0.9999997207656334 500216.8034810001 In [270]:
1多维度聚合
In [271]: M = np.random.random((3,4))
In [272]: M
Out[272]:
array([[0.79832448, 0.44923861, 0.95274259, 0.03193135],
[0.18441813, 0.71417358, 0.76371195, 0.11957117],
[0.37578601, 0.11936151, 0.37497044, 0.22944653]])
In [273]: M.sum()
Out[273]: 5.1136763453287335
In [274]: M.min(axis=0)
Out[274]: array([0.18441813, 0.11936151, 0.37497044, 0.03193135])
In [275]: M.min(axis=1)
Out[275]: array([0.03193135, 0.11957117, 0.11936151])
axis关键字指定的是数组将会被折腾的维度,而不是将要返回的维度。因此指定axis=0意味着第一个轴要被折叠 对于二维数组,这意味着每一列的值都会被聚合。」
2其他聚合函数
| Function Name | NaN-safe Version | Description |
|---|---|---|
np.sum |
np.nansum |
Compute sum of elements |
np.prod |
np.nanprod |
Compute product of elements |
np.mean |
np.nanmean |
Compute mean of elements |
np.std |
np.nanstd |
Compute standard deviation |
np.var |
np.nanvar |
Compute variance |
np.min |
np.nanmin |
Find minimum value |
np.max |
np.nanmax |
Find maximum value |
np.argmin |
np.nanargmin |
Find index of minimum value |
np.argmax |
np.nanargmax |
Find index of maximum value |
np.median |
np.nanmedian |
Compute median of elements |
np.percentile |
np.nanpercentile |
Compute rank-based statistics of elements |
np.any |
N/A | Evaluate whether any elements are true |
np.all |
N/A | Evaluate whether all elements are true |
2.4.3 示例:美国总统的身高是多少
In [285]: !head -4 data/president_heights.csv order,name,height(cm) 1,George Washington,189 2,John Adams,170 3,Thomas Jefferson,189
通过pandas读取文件,取出数据
In [286]: import pandas as pd
In [287]: data = pd.read_csv('data/president_heights.csv')
In [288]: heights = np.array(data['height(cm)'])
In [289]: print(heights)
[189 170 189 163 183 171 185 168 173 183 173 173 175 178 183 193 178 173
174 183 183 168 170 178 182 180 183 178 182 188 175 179 183 193 182 183
177 185 188 188 182 185]
输出相关信息
In [290]: print("Mean height: ", heights.mean())
...: print("Standard deviation:", heights.std())
...: print("Minimum height: ", heights.min())
...: print("Maximum height: ", heights.max())
Mean height: 179.73809523809524
Standard deviation: 6.931843442745892
Minimum height: 163
Maximum height: 193
In [292]: print("25th percentile: ", np.percentile(heights, 25))
...: print("Median: ", np.median(heights))
...: print("75th percentile: ", np.percentile(heights, 75))
25th percentile: 174.25
Median: 182.0
75th percentile: 183.0
总统的中位数身高182,174.25cm超越25%的身高。183超过75%的人群的身高
2.5数组的计算:广播
In [19]: a = np.array([0,1,2]) In [20]: b = np.full(3,5) In [21]: a+b Out[21]: array([5, 6, 7]) In [22]:
广播允许这些二元运算符可以用于不同大小的数组。例如,可以简单地讲一个标量(可以认为是一个零维的数组)和一个数组相加:
In [22]: a+5 Out[22]: array([5, 6, 7]) In [23]:
我们可以认为这个操作是将数值5扩展或重复至数组[5,5,5],然后执行加法。
NumPy广播功能的好处是,这种对值的重复实际上并没有发生,但是这是一种很好的理解模型
In [24]: M
Out[24]:
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
In [25]: a
Out[25]: array([0, 1, 2])
In [26]: M+a
Out[26]:
array([[1., 2., 3.],
[1., 2., 3.],
[1., 2., 3.]])
In [27]: a
Out[27]: array([0, 1, 2])
In [28]: b = np.arange(3)[:,np.newaxis]
In [29]: a
Out[29]: array([0, 1, 2])
In [30]: b
Out[30]:
array([[0],
[1],
[2]])
In [31]: a+b
Out[31]:
array([[0, 1, 2],
[1, 2, 3],
[2, 3, 4]])
In [32]:
多维数据的广播,下面有个图可以解释说明
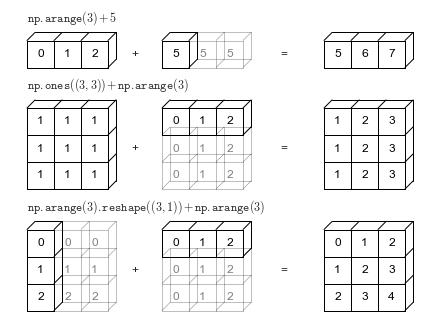
浅色的盒子表示广播的值。同样需要注意的是,这个额外的内存并没有再实际操作中进行分配,但是这样的想象方式更方便我们从概念上理解。
2.5.2广播的规则
规则1:如果两个数组的维度数不相同,那么小维度数组的形状将会在最左边补1。
规则2:如果两个数组的形状再任何一个维度上都不匹配,那么数组的形状会沿着维度为1的维度扩展以匹配另外一个数组的形状。
规则3:如果两个数组的形状再任何一个维度上都不匹配并且没有任何一个维度等于1,那么会引发异常。
1.广播示例1
In [32]: M= np.ones((2,3)) In [33]: a = np.arange(3) In [34]: M.shape Out[34]: (2, 3) In [35]: a.shape Out[35]: (3,) In [36]:
根据规则1,数组a的维度为1,所以左边补1
M.shape = (2, 3)a.shape = (3,)
M.shape -> (2, 3)a.shape -> (1, 3)
根据规则2,第一维度不匹配,因此扩展这个维度以匹配数组
M.shape -> (2, 3)a.shape -> (2, 3)
现在两个数组的形态都是(2,3)了
In [36]: M
Out[36]:
array([[1., 1., 1.],
[1., 1., 1.]])
In [37]: a
Out[37]: array([0, 1, 2])
In [38]: M+a
Out[38]:
array([[1., 2., 3.],
[1., 2., 3.]])
In [39]:
2广播示例2
In [39]: a = np.arange(3).reshape(3,1)
In [40]: a
Out[40]:
array([[0],
[1],
[2]])
In [41]: b = np.arange(3)
In [42]: a.shape
Out[42]: (3, 1)
In [43]: b.shape
Out[43]: (3,)
In [44]:
a.shape = (3, 1)b.shape = (3,)
规则1告诉我们,1将补全给b
a.shape -> (3, 1)b.shape -> (1, 3)
规则2告诉我们,需要更新这两个数组的维度来相互匹配。
a.shape -> (3, 3)b.shape -> (3, 3)
所以a+b的输出为
In [44]: a+b
Out[44]:
array([[0, 1, 2],
[1, 2, 3],
[2, 3, 4]])
3.广播示例3
现在来看一组会报错的示例
In [45]: M=np.ones((3,2)) In [46]: a=np.arange(3) In [47]: M.shape Out[47]: (3, 2) In [48]: a.shape Out[48]: (3,)
M.shape = (3, 2)a.shape = (3,)
根据规则1
M.shape -> (3, 2)a.shape -> (1, 3)
根据规则3,不兼容会报错了
In [49]: M+a --------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-49-2267d2681641> in <module> ----> 1 M+a ValueError: operands could not be broadcast together with shapes (3,2) (3,)
默认是左边补1,如果想右边补1也可以。
In [50]: M+a[:,np.newaxis]
Out[50]:
array([[1., 1.],
[2., 2.],
[3., 3.]])
In [51]: a
Out[51]: array([0, 1, 2])
In [52]: M
Out[52]:
array([[1., 1.],
[1., 1.],
[1., 1.]])
示例只用了+号,其实广播规则对于任意二进制通用函数都是适用的。
2.5.3广播的实际应用
1 数组的归一化
In [53]: X = np.random.random((10,3)) In [54]: Xmean = X.mean(axis=0) In [55]: Xmean Out[55]: array([0.35156125, 0.40162279, 0.43185145]) In [56]: X_centered = X - Xmean In [57]: X_centered.mean(0) Out[57]: array([1.11022302e-17, 0.00000000e+00, 1.11022302e-17]) In [58]:
求出的均值,按照列【就是把行压缩了】,一维数组
然后进行减法操作,进行平均计算验算
2画一个二维函数
广播另外一个非常有用的地方在于,它能基于二维函数显示图片。我们希望定义一个函数z=f(x,y),可以用广播沿着数值区间计算该函数:
x = np.linspace(0, 5, 50) y = np.linspace(0, 5, 50)[:, np.newaxis] z = np.sin(x) ** 10 + np.cos(10 + y * x) * np.cos(x)
%matplotlib inline import matplotlib.pyplot as plt
plt.imshow(z, origin='lower', extent=[0, 5, 0, 5],
cmap='viridis')
plt.colorbar();
2.6 比较、掩码和布尔逻辑
2.6.1示例:统计下雨天数
略
2.6.2 和通用函数类似的比较操作
> < >= <= == !=6个比较操作符号
In [74]: x Out[74]: array([1, 2, 3, 4, 5]) In [75]: x >3 Out[75]: array([False, False, False, True, True]) In [76]: x >3 Out[76]: array([False, False, False, True, True]) In [77]: x<=3 Out[77]: array([ True, True, True, False, False]) In [78]: x>=3 Out[78]: array([False, False, True, True, True]) In [79]: x ==3 Out[79]: array([False, False, True, False, False]) In [80]: x!=3 Out[80]: array([ True, True, False, True, True])
利用复合表达式实现对两个数组的逐元素比较也是可行的
In [81]: 2 ** x == x **2 Out[81]: array([False, True, False, True, False])
比较操作符于运算操作符一样,也是借助通用函数实现的。你使用x <3 实际使用的是np.less(x,3)
| Operator | Equivalent ufunc | Operator | Equivalent ufunc | |
|---|---|---|---|---|
== |
np.equal |
!= |
np.not_equal |
|
< |
np.less |
<= |
np.less_equal |
|
> |
np.greater |
>= |
np.greater_equal |
比较运算符会跟算术运算符一样进行广播
In [86]: rng = np.random.RandomState(0)
In [87]: x = rng.randint(10,size=(3,4))
In [88]: x
Out[88]:
array([[5, 0, 3, 3],
[7, 9, 3, 5],
[2, 4, 7, 6]])
In [89]: x<6
Out[89]:
array([[ True, True, True, True],
[False, False, True, True],
[ True, True, False, False]])
2.6.3 操作布尔数组
In [90]: x
Out[90]:
array([[5, 0, 3, 3],
[7, 9, 3, 5],
[2, 4, 7, 6]])
1 统计记录的个数
In [92]: np.count_nonzero(x<6) Out[92]: 8 In [93]: np.count_nonzero(x<6,axis=1) Out[93]: array([4, 2, 2]) In [94]: np.sum(x<8) Out[94]: 11 In [95]: np.sum(x<8,axis=1) Out[95]: array([4, 3, 4])
都是可以指定折叠的轴的
如果要快递检测任何或者所有的这些是否为True,可以用np.any或np.all
In [96]: x
Out[96]:
array([[5, 0, 3, 3],
[7, 9, 3, 5],
[2, 4, 7, 6]])
In [97]: np.any(x>8)
Out[97]: True
In [98]: np.any(x<0)
Out[98]: False
In [99]: np.all(x<10)
Out[99]: True
In [100]: np.all(x<8,axis=1)
Out[100]: array([ True, False, True])
In [101]:
同样也是可以指定轴的
2.布尔运算符
记住 and和or对整个对象执行单个布尔运算,而&于|对一个对象的内容(单个比特或字节)执行布尔运算。
& | ^ ~
对应的np命令函数
| Operator | Equivalent ufunc | Operator | Equivalent ufunc | |
|---|---|---|---|---|
& |
np.bitwise_and |
| | np.bitwise_or |
|
^ |
np.bitwise_xor |
~ |
np.bitwise_not |
In [104]: np.sum((inches>0.5) & (inches<1)) Out[104]: 29 In [105]:
注意里面的小括号不能少,这个关系到优先级的问题.假如没有小括号,计算机可能会这么认为
inches > (0.5 & inches) < 1
利用 A AND B 和 NOT (NOT A OR B)的等价原理
In [106]: np.sum(~((inches <= 0.5) | (inches >= 1) )) Out[106]: 29
利用这些,天气的输出,可以做到了
In [107]: print("Number days without rain: ", np.sum(inches == 0))
...: print("Number days with rain: ", np.sum(inches != 0))
...: print("Days with more than 0.5 inches:", np.sum(inches > 0.5))
...: print("Rainy days with < 0.2 inches :", np.sum((inches > 0) &
...: (inches < 0.2)))
Number days without rain: 215
Number days with rain: 150
Days with more than 0.5 inches: 37
Rainy days with < 0.2 inches : 75
2.6.4 将布尔数组作为掩码
In [111]: x
Out[111]:
array([[5, 0, 3, 3],
[7, 9, 3, 5],
[2, 4, 7, 6]])
In [112]: x<5
Out[112]:
array([[False, True, True, True],
[False, False, True, False],
[ True, True, False, False]])
In [113]: x[x<5]
Out[113]: array([0, 3, 3, 3, 2, 4])
In [114]:
直接从二维数组中抽出了复合条件的元素,并合成一个一维数组。
后续可以操作输出,需要的数据进行统计。
In [114]: # construct a mask of all rainy days
# 一个雨天的bool数组 ...: rainy = (inches > 0) ...: ...: # construct a mask of all summer days (June 21st is the 172nd day) ...: days = np.arange(365)
# 一个夏天的bool数组 ...: summer = (days > 172) & (days < 262) ...:
# 选出雨天进行中位数 ...: print("Median precip on rainy days in 2014 (inches): ", ...: np.median(inches[rainy]))
# 选出夏天的中位数 ...: print("Median precip on summer days in 2014 (inches): ", ...: np.median(inches[summer]))
# 夏天的最大降雨量 ...: print("Maximum precip on summer days in 2014 (inches): ", ...: np.max(inches[summer]))
# 非夏天并且雨天的中位数 ...: print("Median precip on non-summer rainy days (inches):", ...: np.median(inches[rainy & ~summer])) Median precip on rainy days in 2014 (inches): 0.19488188976377951 Median precip on summer days in 2014 (inches): 0.0 Maximum precip on summer days in 2014 (inches): 0.8503937007874016 Median precip on non-summer rainy days (inches): 0.20078740157480315
2.7 花哨的索引
花哨的索引于前面那些简单的索引非常非常类似,但是传递的是索引数组,而不是单个标量。花哨的索引让我们能够快速获得并修改复杂的数组值的子数据集。
2.7.1探索花哨的索引
In [5]: import numpy as np In [6]: rand = np.random.RandomState(42) In [7]: x = rand.randint(100,size=10) In [8]: x Out[8]: array([51, 92, 14, 71, 60, 20, 82, 86, 74, 74]) In [9]: [x[3],x[7],x[2]] Out[9]: [71, 86, 14] In [10]: ind = [3,7,4] In [11]: x[ind] Out[11]: array([71, 86, 60]) In [12]:
通过一个索引数组从一个数组里面取出对应索引位置的元素。
利用花哨的索引,结果的形状于索引数组的形状一致,而不是于被索引数组的形状一致:
In [12]: ind = np.array([[3,7],[4,5]])
In [13]: x[ind]
Out[13]:
array([[71, 86],
[60, 20]])
In [14]:
花哨的索引也对多维度适用。假设我们有以下数组:
In [16]: X
Out[16]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
通过双坐标点取值
In [23]: X
Out[23]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
In [24]: row = np.array([0,1,2])
In [25]: col = np.array([2,1,3])
In [26]: X[row,col]
Out[26]: array([ 2, 5, 11])
在花哨的索引中,索引值的配对遵循广播的规则。因此将一个列向量和一个行向量组合在一个索引中,会得到二维的结果:
In [27]: X[row[:,np.newaxis],col]
Out[27]:
array([[ 2, 1, 3],
[ 6, 5, 7],
[10, 9, 11]])
In [28]:
这里,每一行的值于每一列的向量配对,正如我们看到的广播的算术运算
In [27]: X[row[:,np.newaxis],col]
Out[27]:
array([[ 2, 1, 3],
[ 6, 5, 7],
[10, 9, 11]])
In [28]:
花哨索引返回的值反映的是广播后的索引数组的形状,而不是被索引的形状。
2.7.2组合索引
In [31]: X
Out[31]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
In [32]: X[2,[2,0,1]]
Out[32]: array([10, 8, 9])
In [33]: X[1:,[2,0,1]]
Out[33]:
array([[ 6, 4, 5],
[10, 8, 9]])
In [34]:
上面演示了花哨索引于简单索引以及切片的组合。
In [34]: mask = np.array([1,0,1,0],dtype=np.bool)
In [35]: X[row[:,np.newaxis],mask]
Out[35]:
array([[ 0, 2],
[ 4, 6],
[ 8, 10]])
In [36]:
对于多维的理解,还需要加强,我个人理解,第一个参数为列向量,数值为选取的每一个行所有的数据。就上面的情况
2.7.3 示例:选择随机点【真的很难理解,只能抄书了】
一个NXD的矩阵,表示在D个维度的N个点。下面是一个二维正态分布的点组成的数组:
mean = [0, 0]
cov = [[1, 2],
[2, 5]]
X = rand.multivariate_normal(mean, cov, 100)
X.shape
(100, 2)
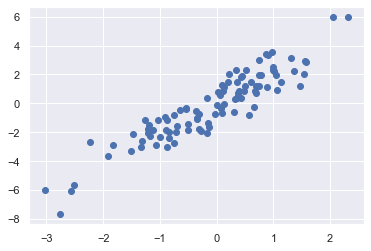
利用画图工具进行画图,画出散点图
%matplotlib inline import matplotlib.pyplot as plt import seaborn; seaborn.set() # for plot styling plt.scatter(X[:, 0], X[:, 1]);
随机选择20个不重复的索引值
indices = np.random.choice(X.shape[0], 20, replace=False) indices
array([60, 13, 16, 78, 35, 20, 37, 83, 38, 56, 42, 67, 39, 36, 82, 59, 53,
99, 32, 68])
通过花哨索引取值
selection = X[indices] # fancy indexing here selection.shape (20, 2)
画出选中的点
plt.scatter(X[:, 0], X[:, 1], alpha=0.3)
plt.scatter(selection[:, 0], selection[:, 1],
facecolor='none', s=200);

2.7.4.用花哨的索引修改值
修改花哨索引的值
In [1]: import numpy as np In [2]: x = np.arange(10) In [3]: i = np.array([2,1,8,4]) In [4]: x[i] Out[4]: array([2, 1, 8, 4]) In [5]: x[i] = 99 In [6]: x Out[6]: array([ 0, 99, 99, 3, 99, 5, 6, 7, 99, 9]) In [7]:
可以使用-=,+=来赋值
任意的赋值操作来实现,例如:
In [7]: x[i] -=10 In [8]: x Out[8]: array([ 0, 89, 89, 3, 89, 5, 6, 7, 89, 9])
重复的索引以后面的数据为准
In [9]: x = np.zeros(10) In [10]: x[[0,0]]=[4,6] In [11]: x Out[11]: array([6., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) In [12]:
对单个元素进行多次累加
In [11]: x Out[11]: array([6., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) In [12]: i = [2,3,3,4,4,4] In [13]: x[i] += 1 In [14]: x Out[14]: array([6., 0., 1., 1., 1., 0., 0., 0., 0., 0.]) In [15]:
通过上面的方式发现失败
需要借助at函数
In [15]: x =np.zeros(10) In [16]: np.add.at(x,i,1) In [17]: x Out[17]: array([0., 0., 1., 2., 3., 0., 0., 0., 0., 0.])
at()函数在这里对给定的操作、给定的索引(这里是i)以及给定的值(这里是1)执行就地操作。
2.7.5 示例:数据区间划分
100个值,快速统计分布在每个区间中的数据频次。
In [224]: np.random.seed(42)
In [225]: x = np.random.randn(100)
In [226]: bins = np.linspace(-5,5,20)
In [227]: bins
Out[227]:
array([-5. , -4.47368421, -3.94736842, -3.42105263, -2.89473684,
-2.36842105, -1.84210526, -1.31578947, -0.78947368, -0.26315789,
0.26315789, 0.78947368, 1.31578947, 1.84210526, 2.36842105,
2.89473684, 3.42105263, 3.94736842, 4.47368421, 5. ])
In [228]: counts = np.zeros_like(bin)
In [229]: i = np.searchsorted(bins, x)
In [230]: i
Out[230]:
array([11, 10, 11, 13, 10, 10, 13, 11, 9, 11, 9, 9, 10, 6, 7, 9, 8,
11, 8, 7, 13, 10, 10, 7, 9, 10, 8, 11, 9, 9, 9, 14, 10, 8,
12, 8, 10, 6, 7, 10, 11, 10, 10, 9, 7, 9, 9, 12, 11, 7, 11,
9, 9, 11, 12, 12, 8, 9, 11, 12, 9, 10, 8, 8, 12, 13, 10, 12,
11, 9, 11, 13, 10, 13, 5, 12, 10, 9, 10, 6, 10, 11, 13, 9, 8,
9, 12, 11, 9, 11, 10, 12, 9, 9, 9, 7, 11, 10, 10, 10])
In [233]: counts
Out[233]: array(0, dtype=object)
In [234]: counts = np.zeros_like(bins)
In [235]: np.add.at(counts, i, 1)
In [236]: counts
Out[236]:
array([ 0., 0., 0., 0., 0., 1., 3., 7., 9., 23., 22., 17., 10.,
7., 1., 0., 0., 0., 0., 0.])
这里的看懂还是花了我一点时间,np.searchsorted返回第二个参数内的元素在第一个参数内的索引位置,组个返回一个索引的数组
通过一份空表,对空表内的每个索引的值进行累加,形成柱状图,思路还是非常清晰的。
每次通过这么复杂的逻辑太麻烦了,NumPy还有np.histogram方法来实现:
In [237]: counts, edges = np.histogram(x, bins)
In [238]: counts
Out[238]:
array([ 0, 0, 0, 0, 1, 3, 7, 9, 23, 22, 17, 10, 7, 1, 0, 0, 0,
0, 0])
In [239]: edges
Out[239]:
array([-5. , -4.47368421, -3.94736842, -3.42105263, -2.89473684,
-2.36842105, -1.84210526, -1.31578947, -0.78947368, -0.26315789,
0.26315789, 0.78947368, 1.31578947, 1.84210526, 2.36842105,
2.89473684, 3.42105263, 3.94736842, 4.47368421, 5. ])
两个入参,第一个入选的参数,第二个是范围,出参为统计的频率,以及入参的第二个参数。
print("NumPy routine:")
%timeit counts, edges = np.histogram(x, bins)
print("Custom routine:")
%timeit np.add.at(counts, np.searchsorted(bins, x), 1)
NumPy routine: 26.2 µs ± 1.21 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) Custom routine: 11.5 µs ± 212 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
通过对比,我们自己写的好像比内置的histogram函数要快。
但增大数据量就出现了不同的结果
x = np.random.randn(1000000)
print("NumPy routine:")
%timeit counts, edges = np.histogram(x, bins)
print("Custom routine:")
%timeit np.add.at(counts, np.searchsorted(bins, x), 1)
NumPy routine: 55.3 ms ± 1.91 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) Custom routine: 80 ms ± 2.29 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
告诉我们不同的函数在处理不同的数据的时候,效率会出现偏差。
2.8数组的排序
书中的选择排序
import numpy as np
def selection_sort(x):
for i in range(len(x)):
swap = i + np.argmin(x[i:])
(x[i], x[swap]) = (x[swap], x[i])
return x
从第一个数字开始,每次于后面的最小数进行交换,时间复杂度为N平方
作者的大招算法我觉的很佩服,老喜欢
def bogosort(x):
while np.any(x[:-1] > x[1:]):
np.random.shuffle(x)
return x
每次打乱,只要前排的数字全部小于后排的,那就按小到大的排序了。
很有意思的逻辑,用了死循环,如果不成立,用random.shuffle继续重新洗牌。
2.8.1NumPy中的快速排序:np.sort和np.argsort
np.sort默认使用的是快速排序,时间复杂都NlogN
在不修改数组的情况下,通过np.srot的方法实现排序,跟Python差不多的使用
In [246]: n Out[246]: array([3, 1, 2, 5, 4, 0]) In [247]: np.sort(n) Out[247]: array([0, 1, 2, 3, 4, 5]) In [248]: n Out[248]: array([3, 1, 2, 5, 4, 0]) In [249]: n.sort() In [250]: n Out[250]: array([0, 1, 2, 3, 4, 5])
argsort,返回排好序情况下,去原数组该取的位置。
In [251]: x = np.array([2, 1, 4, 3, 5])
...: i = np.argsort(x)
...: print(i)
[1 0 3 2 4]
从输出的i可以看出来,每个元素当做索引去原数组取值,就是排好序的输出。
In [254]: x[i] Out[254]: array([1, 2, 3, 4, 5]) In [255]:
sort可以通过添加axis参数来选择行或者列进行排序
In [258]: np.sort(X)
Out[258]:
array([[3, 4, 6, 6, 7, 9],
[2, 3, 4, 6, 7, 7],
[1, 2, 4, 5, 7, 7],
[0, 1, 4, 5, 5, 9]])
In [259]: np.sort(X,axis=1)
Out[259]:
array([[3, 4, 6, 6, 7, 9],
[2, 3, 4, 6, 7, 7],
[1, 2, 4, 5, 7, 7],
[0, 1, 4, 5, 5, 9]])
In [260]: np.sort(X,axis=0)
Out[260]:
array([[2, 1, 4, 0, 1, 5],
[5, 2, 5, 4, 3, 7],
[6, 3, 7, 4, 6, 7],
[7, 6, 7, 4, 9, 9]])
默认对每一行进行排序,参数未axis=1
2.8.2部分排序,分隔
np.parttition函数的输入值是数组和数字K,输出结果是一个新数组,最左边是第K小的值,元素是没有排序的
In [266]: x = np.array([7, 2, 3, 1, 6, 5, 4]) In [267]: np.partition(x,3) Out[267]: array([2, 1, 3, 4, 6, 5, 7])
靠左边的三个数字是前三小的数字。
np.parttition也可以指定具体的维度
In [268]: X
Out[268]:
array([[6, 3, 7, 4, 6, 9],
[2, 6, 7, 4, 3, 7],
[7, 2, 5, 4, 1, 7],
[5, 1, 4, 0, 9, 5]])
In [269]: np.partition(X,2)
Out[269]:
array([[3, 4, 6, 7, 6, 9],
[2, 3, 4, 7, 6, 7],
[1, 2, 4, 5, 7, 7],
[0, 1, 4, 5, 9, 5]])
In [270]: np.partition(X,2,axis=1)
Out[270]:
array([[3, 4, 6, 7, 6, 9],
[2, 3, 4, 7, 6, 7],
[1, 2, 4, 5, 7, 7],
[0, 1, 4, 5, 9, 5]])
每一行的前2小的数值出来了。
2.8.3示例:K个最近邻
利用argsort函数沿着多个轴快速找到集合中每个点的最近邻。首先在二维平面上创建10个随机点。首先将这些数据点放在10X2的数组中
X = rand.rand(10, 2) print(X)
[[0.00706631 0.02306243] [0.52477466 0.39986097] [0.04666566 0.97375552] [0.23277134 0.09060643] [0.61838601 0.38246199] [0.98323089 0.46676289] [0.85994041 0.68030754] [0.45049925 0.01326496] [0.94220176 0.56328822] [0.3854165 0.01596625]]
画个图出来看看
%matplotlib inline import matplotlib.pyplot as plt import seaborn; seaborn.set() # Plot styling plt.scatter(X[:, 0], X[:, 1], s=100);

现在来计算两两数据点对间的距离。两个点间间距离的平方等于每个维度的距离差的平方的和。利用NumPy的广播和聚合功能,可以用一行代码计算矩阵的平方距离:
dist_sq = np.sum((X[:, np.newaxis, :] - X[np.newaxis, :, :]) ** 2, axis=-1)
看不懂拆开,其实我拆开还是不能很理解,呵呵呵
# for each pair of points, compute differences in their coordinates differences = X[:, np.newaxis, :] - X[np.newaxis, :, :] differences.shape
(10, 10, 2)
# square the coordinate differences sq_differences = differences ** 2 sq_differences.shape
(10, 10, 2)
# sum the coordinate differences to get the squared distance dist_sq = sq_differences.sum(2) dist_sq.shape dist_sq
array([[0. , 0.40999909, 0.90538547, 0.05550496, 0.50287983,
1.14976739, 1.15936537, 0.19672877, 1.16632222, 0.14319923],
[0.40999909, 0. , 0.55794316, 0.18090431, 0.00906581,
0.21465798, 0.19098635, 0.15497331, 0.20095384, 0.16679585],
[0.90538547, 0.55794316, 0. , 0.81458763, 0.67649219,
1.13419594, 0.74752753, 1.08562368, 0.9704683 , 1.03211241],
[0.05550496, 0.18090431, 0.81458763, 0. , 0.23387834,
0.70468321, 0.74108843, 0.05338715, 0.72671958, 0.0288717 ],
[0.50287983, 0.00906581, 0.67649219, 0.23387834, 0. ,
0.14021843, 0.1470605 , 0.16449241, 0.13755476, 0.18859392],
[1.14976739, 0.21465798, 1.13419594, 0.70468321, 0.14021843,
0. , 0.06080186, 0.48946337, 0.01100053, 0.56059965],
[1.15936537, 0.19098635, 0.74752753, 0.74108843, 0.1470605 ,
0.06080186, 0. , 0.61258786, 0.02046045, 0.66652228],
[0.19672877, 0.15497331, 1.08562368, 0.05338715, 0.16449241,
0.48946337, 0.61258786, 0. , 0.54429694, 0.00424306],
[1.16632222, 0.20095384, 0.9704683 , 0.72671958, 0.13755476,
0.01100053, 0.02046045, 0.54429694, 0. , 0.60957115],
[0.14319923, 0.16679585, 1.03211241, 0.0288717 , 0.18859392,
0.56059965, 0.66652228, 0.00424306, 0.60957115, 0. ]])
这里可以看到该矩阵的对角线(也就是每个点到其自身的距离)的值都是0
dist_sq.diagonal()
array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
可以使用np.argsort函数沿着每行进行排序
nearest = np.argsort(dist_sq, axis=1) print(nearest)
[[0 3 9 7 1 4 2 5 6 8] [1 4 7 9 3 6 8 5 0 2] [2 1 4 6 3 0 8 9 7 5] [3 9 7 0 1 4 5 8 6 2] [4 1 8 5 6 7 9 3 0 2] [5 8 6 4 1 7 9 3 2 0] [6 8 5 4 1 7 9 3 2 0] [7 9 3 1 4 0 5 8 6 2] [8 5 6 4 1 7 9 3 2 0] [9 7 3 0 1 4 5 8 6 2]]
这里可以看到第一列按照0~9从小到大排列。这是因为每个点的最近领是其自身,所有结果也正是我们所想。
如果使用全排序,我们实际上可以实现的比这个例子展示的更多。如果我们仅仅关心k个近邻,那么唯一需要做的是分隔每一行,这样最小的k+1的平方距离将排在最前面,其他更长的距离占据矩阵该行的其他位置。
可以用np.argpartition函数实现:
K = 2 nearest_partition = np.argpartition(dist_sq, K + 1, axis=1) nearest_partition
array([[3, 0, 9, 7, 1, 4, 2, 5, 8, 6],
[1, 4, 7, 9, 3, 5, 6, 2, 8, 0],
[2, 1, 4, 6, 3, 0, 5, 7, 8, 9],
[3, 9, 7, 0, 1, 5, 6, 2, 8, 4],
[1, 8, 4, 5, 7, 6, 9, 3, 2, 0],
[5, 8, 6, 4, 1, 7, 9, 3, 2, 0],
[6, 8, 5, 4, 1, 7, 9, 3, 2, 0],
[7, 9, 3, 1, 4, 5, 6, 2, 8, 0],
[8, 5, 6, 4, 1, 7, 9, 3, 2, 0],
[3, 9, 7, 0, 1, 5, 6, 2, 8, 4]])
各个点位的前3小的节点已经标出,期中有一个肯定是自身。
画出每个点相邻的点
plt.scatter(X[:, 0], X[:, 1], s=100)
# draw lines from each point to its two nearest neighbors
K = 2
# 首先循环10个点
for i in range(X.shape[0]):
# 从已经选出的点里面跳出前三个最近的点
for j in nearest_partition[i, :K+1]:
# plot a line from X[i] to X[j]
# use some zip magic to make it happen:
# 画出三个点到每个点的最近线段,一个点就是自身
plt.plot(*zip(X[j], X[i]), color='black')

上面的写法真的很漂亮,等我线性代数学好了,回头一定还要再来看看。
图中的每个点和离它最近的两个节点用线连接。咋一看,你可能会奇怪为什么有些点的连接多于两条,这是因为点A是点B最领近的两个节点之一,但并不意味着B一定是A的最邻近的两个节点之一。
尽管本例中的广播和按行排序可能看起来不如循环直观,但是在实际运行中,Python中这类数据的操作会更高效。你可能会尝试通过手动循环数据并对每一组相邻节点单独进行排序来实现同样的功能,
但是这种方法和我们使用的向量化操作相比,肯定在算法执行上效率更低。并且向量化操作的优美之处在于,它的实现方式决定了它对输入数据的数据量并不敏感。
也就是说,我们可能非常轻松地计算任意维度空间的100或者1000000个相邻几诶点,而代码看起来是一样的
2.9结构化数据:NumPy的结构化数组
假定现在的人的三条独立的数组数据
name = ['Alice', 'Bob', 'Cathy', 'Doug'] age = [25, 45, 37, 19] weight = [55.0, 85.5, 68.0, 61.5]
通过zeros行数,设置dtype
data = np.zeros(4, dtype={'names':('name', 'age', 'weight'),
'formats':('U10', 'i4', 'f8')})
print(data.dtype)
data
[('name', '<U10'), ('age', '<i4'), ('weight', '<f8')]
array([('', 0, 0.), ('', 0, 0.), ('', 0, 0.), ('', 0, 0.)],
dtype=[('name', '<U10'), ('age', '<i4'), ('weight', '<f8')])
通过列坐标进行赋值
[('name', '<U10'), ('age', '<i4'), ('weight', '<f8')]
array([('', 0, 0.), ('', 0, 0.), ('', 0, 0.), ('', 0, 0.)],
dtype=[('name', '<U10'), ('age', '<i4'), ('weight', '<f8')])
[('Alice', 25, 55. ) ('Bob', 45, 85.5) ('Cathy', 37, 68. )
('Doug', 19, 61.5)]
# Get all names
data['name']
array(['Alice', 'Bob', 'Cathy', 'Doug'], dtype='<U10')
# Get first row of data
data[0]
('Alice', 25, 55.)
# Get the name from the last row
data[-1]['name']
'Doug'
Using Boolean masking, this even allows you to do some more sophisticated operations such as filtering on age:
# Get names where age is under 30
data[data['age'] < 30]['name']
array(['Alice', 'Doug'], dtype='<U10')
通过列坐标,行索引都能取值
还能使用布尔掩码,进行一些更加复杂的操作。
data[data['age']<30]
array([('Alice', 25, 55. ), ('Doug', 19, 61.5)],
dtype=[('name', '<U10'), ('age', '<i4'), ('weight', '<f8')])
2.9.1 生成结构化数组
结构化数组的数据类型有多种指定方式。此前我们看到过的采用字典的方式:
np.dtype({'names':('name', 'age', 'weight'),
'formats':('U10','i4','f8')})
dtype([('name', '<U10'), ('age', '<i4'), ('weight', '<f8')])
为了简明起见,数值数据类型可以用Python类型或NumPy的dtype类型指定:
np.dtype({'names':('name','age','weight'),
'formats':((np.str_,10),int,np.float)})
dtype([('name', '<U10'), ('age', '<i8'), ('weight', '<f8')])
复合类型也可以是元祖列表:
np.dtype([('name','S10'),('age','i4'),('weight','f8')])
dtype([('name', 'S10'), ('age', '<i4'), ('weight', '<f8')])
如果类型的名称对你来说并不重要,那你可以仅仅用一个字符串来指定它。在该字符串中数据类型用逗号分隔:
np.dtype('S10,i4,f8')
dtype([('f0', 'S10'), ('f1', '<i4'), ('f2', '<f8')])
简写的字符串格式的代码可能看起来令人困惑,但是它们其实基于非常简单的规则。第一个(可选)字符是<或者>,分别表示"低字节序"和"高字节序",表示字节(bytes)类型的数据在内存中存放顺序的习惯用法。
后一个字符指定的是数据的类型:字符、字节、整形、浮点型、等等.最后一个字符表示该对象的字节大小
| Character | Description | Example |
|---|---|---|
'b' |
Byte | np.dtype('b') |
'i' |
Signed integer | np.dtype('i4') == np.int32 |
'u' |
Unsigned integer | np.dtype('u1') == np.uint8 |
'f' |
Floating point | np.dtype('f8') == np.int64 |
'c' |
Complex floating point | np.dtype('c16') == np.complex128 |
'S', 'a' |
String | np.dtype('S5') |
'U' |
Unicode string | np.dtype('U') == np.str_ |
'V' |
Raw data (void) | np.dtype('V') == np.void |
2.9.2更高级的复合类型
NumPy中也可以定义更高级的复合数据类型。列如,你可以创建一种类型,其中每个元素都包含一个数组或矩阵。
我们会创建一个数据类型,该数据类型用mat组件包含一个3X3的浮点矩阵
tp = np.dtype([('id','i8'),('mat','f8',(3,3))])
X = np.zeros(1,dtype=tp)
print(X[0])
print(X['mat'].shape)
X['mat']
(0, [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.]])
(1, 3, 3)
array([[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]])
现在X数组的每个元素都包含一个id和3X3的矩阵。为什么我们宁愿用这种方法存储数据,也不用简单的多维数组,或者Python字典呢?
原因是NumPy的dtype直接映射到C结构的定义,因此包含数组内容的缓存可以直接在C程序中使用。如果你想写一个Python接口与一个遗留的C语言或Fortran库交互,从而操作数据结构,你将会发现结构化数组非常有用。
2.9.3记录数组:结构化数组的扭转
NumPy还提供了np.recarray类。它返回的数据可以通过.来获取属性
data['age'] array([25, 45, 37, 19], dtype=int32)
本来我们是这样取列数据的,通过np.recarray调用传参后
data_rec = data.view(np.recarray) data_rec.age array([25, 45, 37, 19], dtype=int32)
这种方式不好的地方的是,在获取数据的时候,开销大一点所以稍微慢一点
%timeit data['age'] %timeit data_rec['age'] %timeit data_rec.age 127 ns ± 2.34 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each) 2.53 µs ± 74.3 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 3.22 µs ± 20.4 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
差距还是比较大的。
结束,下一站pandas
𝑧=𝑓

 浙公网安备 33010602011771号
浙公网安备 33010602011771号