python-集合(set)知识整理
#### 集合 ####
-
set 集合 和 线性结构
- 线性结构 的查询时间复杂度是 O(n),即随着数据规模的增大而增加耗时。
- set集合 ,dict 字典 等结构,内部使用hash值作为key,时间复杂度可以做到O(1),查询时间和数据规模无关
- 可hash
- 数字型:int、float、complex
- 布尔型:True、False
- 字符串:string、bytes
- 元组:tuple
- None
- 以上都是不可变类型,成为可哈希 类型。
set 的元素必须是可hash的。*** 不管你嵌套多少层,只要有不可哈希的元素就会报错 !!!
集合特性: 1、元素必须是不可变类型(数字,字符串,元组),必须可ha
2、不同元素组成,如果相同就会自动去重,只保留一个。
3、集合是无序的
4、集合是可变类型
定义集合:s = {1,4,32,1}

使用s = set()时,必须是可迭代对象才行。


# 集合是一个可变的、无序的,不重复的数据组合,
它的主要作用如下:
1、去重,把一个列表变成集合,就自动去重了
2、关系测试,测试两组数据之前的交集、差集、并集等关系
(注:set元素要求必须可hash才能加入到set元素中)
因为没有顺序,所以无法被索引,但是可以被迭代。
list01 = [1,4,5,6,7,8,4,5,6]
print(list01,type(list01))
# [1, 4, 5, 6, 7, 8, 4, 5, 6] <class 'list'>
list01 = set(list01)
print(list01,type(list01))
# {1, 4, 5, 6, 7, 8} <class 'set'>
基本概念:
全集
所有元素的集合,
子集subset和超集superset
一个集合A所有元素都在另一个集合B内,A是B的子集,B是A的超集
真子集和真超集
A是B的子集,且A不等于B,A就是B的真子集,B是A的真超集。
并集:过个集合合并的结果
交集:多个集合的公共部分
差集:集合中除去和其他集合公共部分
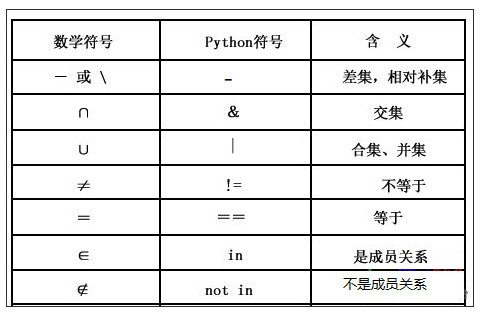
# ################### 交集 (intersection)符号为:【 & 】 #########################



# 交集 表示符号:& 表示 集合1和集合2 中都有的。
list02 = set([2,6,0,22,8,4])
print(list01,list02)
# {1, 4, 5, 6, 7, 8} {0, 2, 4, 6, 8, 22}
# # 交集 intersection
print(list01.intersection(list02))
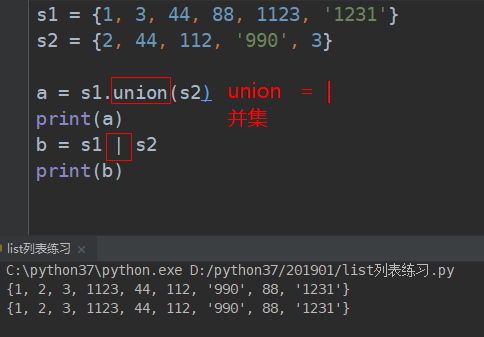
# ################### 并集 (union)符号为: 【 | 】#########################

# 并集 表示符号:| 表示 集合1或者是集合2中有的
# # 并集 union 并起来去重
print(list01.union(list02))
# {0, 1, 2, 4, 5, 6, 7, 8, 22}
# ################### 差集 (difference)符号为:【 - 】 #########################

A -P = {} ,A -P 为空集,说明P包含A


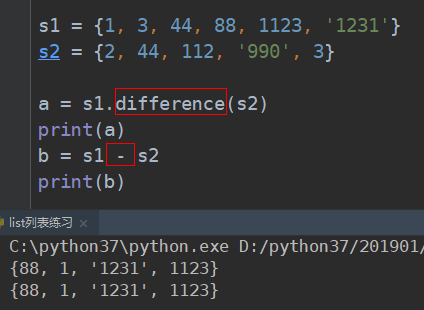
# 差集表示符号:- 表示 set01 - set02 表示 set01中有的,set02中没有的
# set02 - set01 表示 set02中有的,set01中没有的
# # 差集 difference list01中有的,list02中没有的
print(list01.difference(list02))
# {1, 5, 7}
print(list02.difference(list01))
# {0, 2, 22}
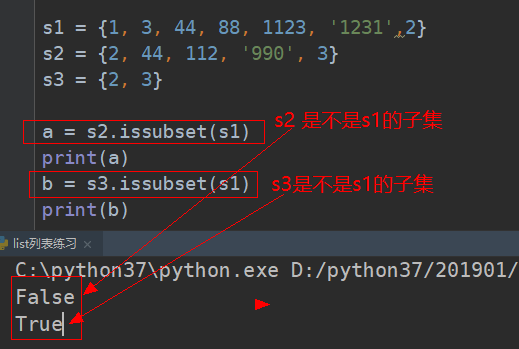
# ################### 子集 (issubset) #########################
aa.issubset(bb) 进行判断,aa是不是bb的子集
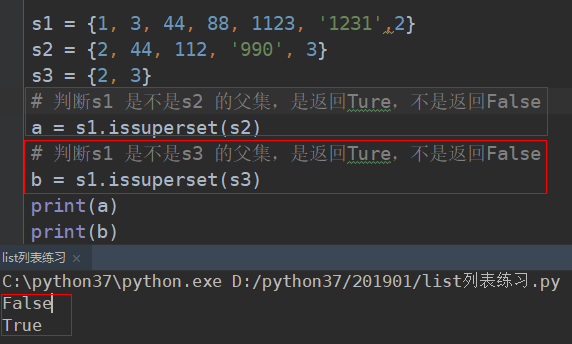
# ################### 父集 (issuperset) #########################
# ################### 反向差集| 交叉补集| 对称差集 (symmetric_difference)符号为:【 ^ 】 #########################


# list01和list02里面,互相都没有的,取出来放到一块
print(list01.symmetric_difference(list02))
########################## 集合的功能介绍及举例说明 ###################################
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# __author__:anxu.qi
# Date:2018/12/4
#######################################################################################
a = {11, 22, 33, 44, 66, 99, "oopp",1123, "111"}
b = {11,22,88,99,"oopp","opop"}
# ##################### add 向集合中添加元素 注:一次只允许添加一个元素 ####

# a.add("vivo")
# print(a) # {33, 66, 'opop', 'vivo', 11, 44, 77, 22, 55}
# #################### clear 删除集合的所有的元素 #################

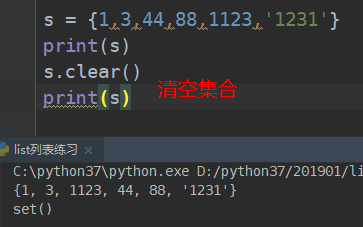
# #################### copy 浅copy ####
重新赋值一份数据给s1

# #################### difference A中存在的B中不存在的 ####
# A中存在,B中不存在 返回一个新值,变量接受
c = a.difference(b)
print(c) # {33, 66, 1123, 44, '111'}
# #################### difference_update A中存在的B中不存在的,结果更新为A ####
a.difference_update(b)
print(a) # {33, 66, 1123, '111', 44}
a = {11, 22, 33, 44, 66, 99, "oopp",1123, "111"}
b = {11,22,88,99,"oopp","opop"}
# #################### discard 移除指定的元素,不存在不报错 ####


# #################### remove 移除指定的元素,不存在则提示ERROR。 ####



做的是key的比较
a.discard(11111)
# #################### intersection 取出交集并赋值给cc #####
cc = a.intersection(b)
print(cc) # {11, 'oopp', 99, 22}
# #################### intersection_update 取出交集并赋值给A ####
a.intersection_update(b)
print(a) # {'oopp', 11, 99, 22}
# #################### isdisjoint 如果没有交集返回True,有交集为False ####
print(a.isdisjoint(b)) # False
se = {11,22,33,44}
be = {11,22}
# #################### issubset # 另一个集合是否包含此集合, 子序列 ####
print(be.issubset(se)) # True
# #################### issuperset # 这个集合是否包含另一个集合 父序列 ####
print(se.issuperset(be)) # True
# #################### pop # 移除并返回任意集合元素,如果集合为空,则引发KeyError ####

aaa = se.pop() # 可以将移除的那个元素赋值给其他值 ####
print(aaa) # 33
# #################### symmetric_difference # 将se中存在的be不存在的,be不存在的se中存在的合并到了一起,赋值为dddd ####
dddd = se.symmetric_difference(be)
print(dddd) # {33, 99, 44, 77, 88}
cccc = se.symmetric_difference(be)
print(cccc) # {33, 99, 44, 77, 88}
# #################### symmetric_difference_update # 将se中存在的be不存在的,be不存在的se中存在的合并到了一起,赋值为se ####
se.symmetric_difference_update(be)
print(se) # {33, 99, 44, 77, 88}
# ##############################
se = {11,22,33,44,99}
be = {11,22,77,88}
# #################### union # 取并集 ####


tt = se.union(be)
print(tt) # {33, 99, 11, 44, 77, 22, 88}
# #################### update # 更新的时候,必须得是可迭代(Iterable)的 ####
|= 就等于update




se.update([666,888])
se.update(666,888)
print(se)
# ########################################################################################################


list 随着规模的增加,效率在往下走,
set 随着规模的增加,效率还是那样

集合补充:
不可变集合:frozonset
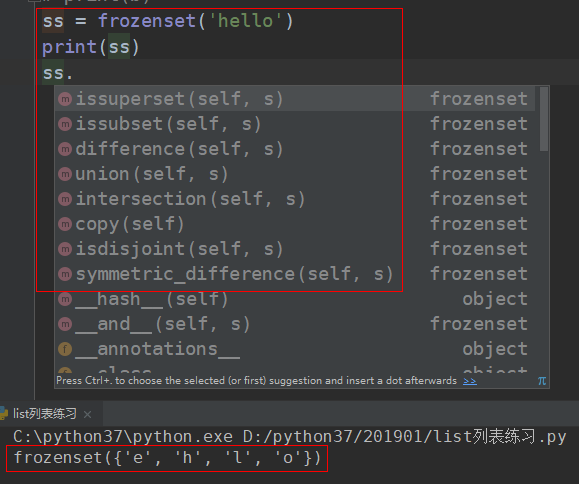
# 不考虑顺序的快速去重

#####有一篇介绍python集合的文章,写的很好
https://tw.saowen.com/a/ab713431b675abe3d71cf675d04082b9601135ba484291bb2b3a95b6ccad0e4f
我的目标是每天厉害一点点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号