

数据分析01_数据观察
本次学习数据以Titanic为例,链接:https://www.kaggle.com/competitions/titanic/data
本次学习工具:jupyter
本次学习目录文件:

数据分析主要使用python的numpy和pandas库
import numpy as np import pandas as pd
一、载入数据
读取文件:read_csv(csv_name)
1.相对路径读取文件
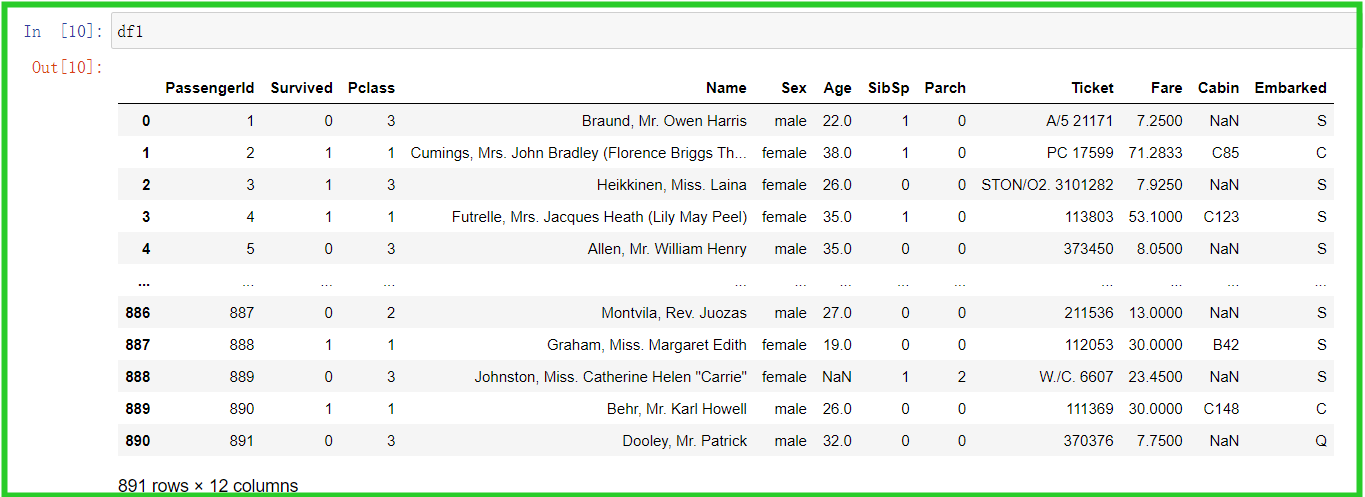
df1 = pd.read_csv('train.csv')
【注意点】
① 相对路径载入失败,查看当前路径
import os opppath = os.getcwd()

2.绝对路径读取文件
① 查看绝对路径
import os abs_path = os.path.abspath('train.csv')

② 绝对路径读取文件
df2 = pd.read_csv(abs_path)
【注意点】
① 读取其他格式文本,如.xlsx,.tsv等格式
df3 = pd.read_excel('train.xlxs')
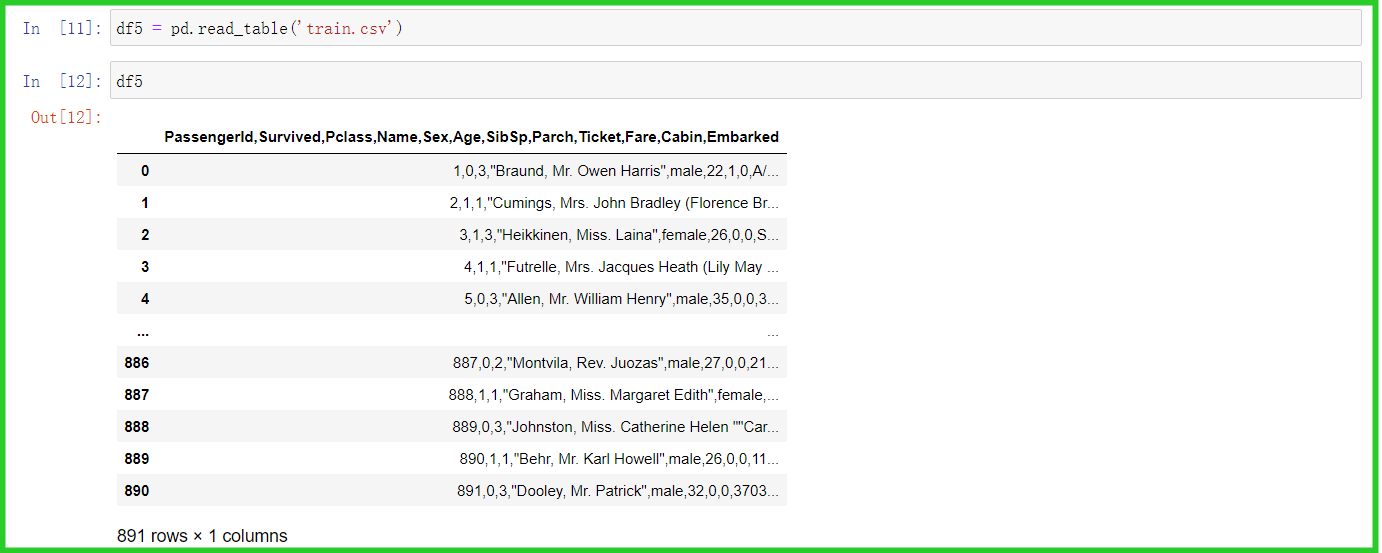
df4 = pd.read_csv('train.tsv', sep='\t')
② read_csv()与read_table()的区别在于分隔符,前者按照逗号“,”分隔,后者按照制表符“\t”分隔
源文件
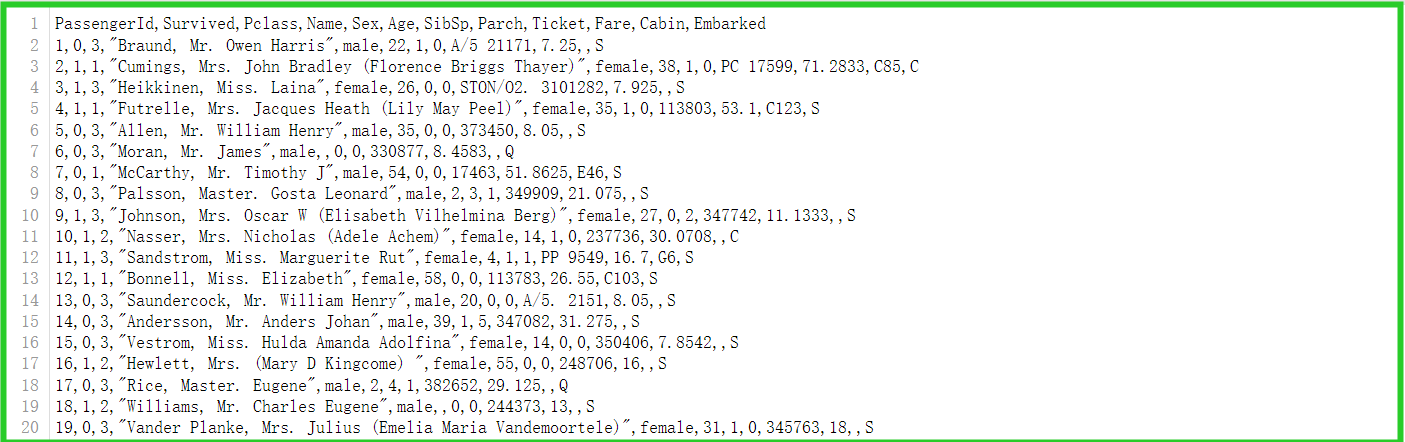
read_csv()载入的文件,以“,”分隔,因此多列
read_table()载入的文件,以“\t”分隔,因此1列
3.数据模块
4.表头中英文替换
初始文件表头

① colunms:直接替换
df1.columns = ['乘客ID','是否幸存','乘客等级(1/2/3等舱位)','乘客姓名','性别','年龄','堂兄弟/妹个数','父母与小孩个数','船票信息','票价','客舱','E登船港口']

② read_csv(file, names=[], header)读取文件时修改表头
i. 增加表头
df7 = pd.read_csv('train.csv', names=['乘客ID','是否幸存','乘客等级(1/2/3等舱位)','乘客姓名','性别','年龄','堂兄弟/妹个数','父母与小孩个数','船票信息','票价','客舱','E登船港口'])

ii.替换表头
df7 = pd.read_csv('train.csv', names=['乘客ID','是否幸存','乘客等级(1/2/3等舱位)','乘客姓名','性别','年龄','堂兄弟/妹个数','父母与小孩个数','船票信息','票价','客舱','E登船港口'],header=0)

三、文件信息
1.查看基本信息
① 直接输入名称,显示整个数据集
df1

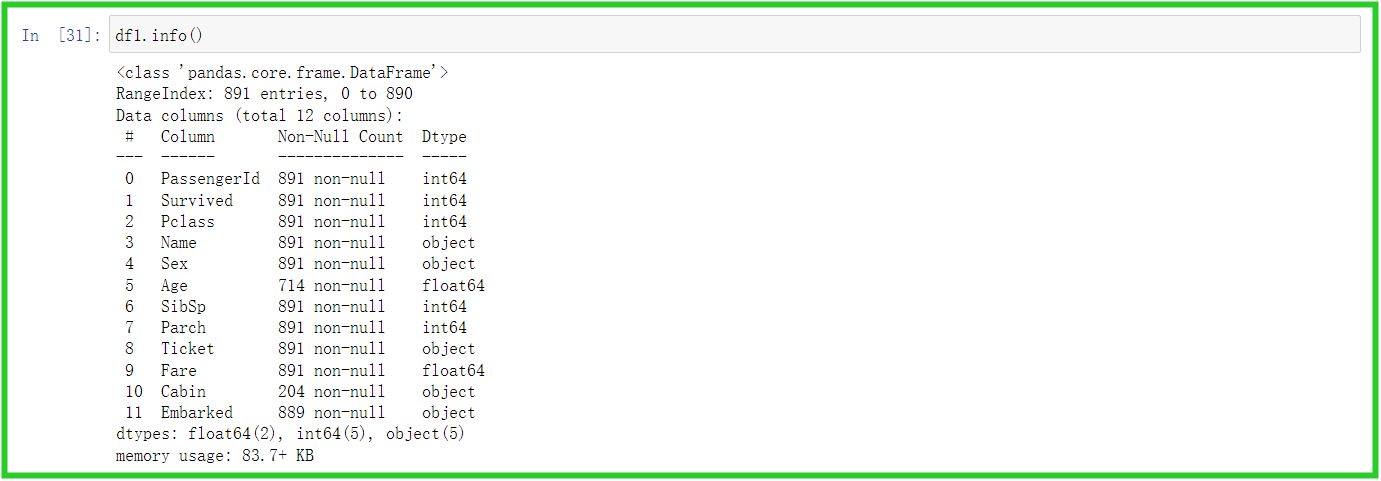
② info() :输出
df1.info()
③ describe():输出所有列的各参数
df1.describe()

④ columns:输出列
df1.columns

⑤ name: 输出特定列的内容

2.查看前10行和后15行
① head(num):参数缺省时为前5行,加参数则num行


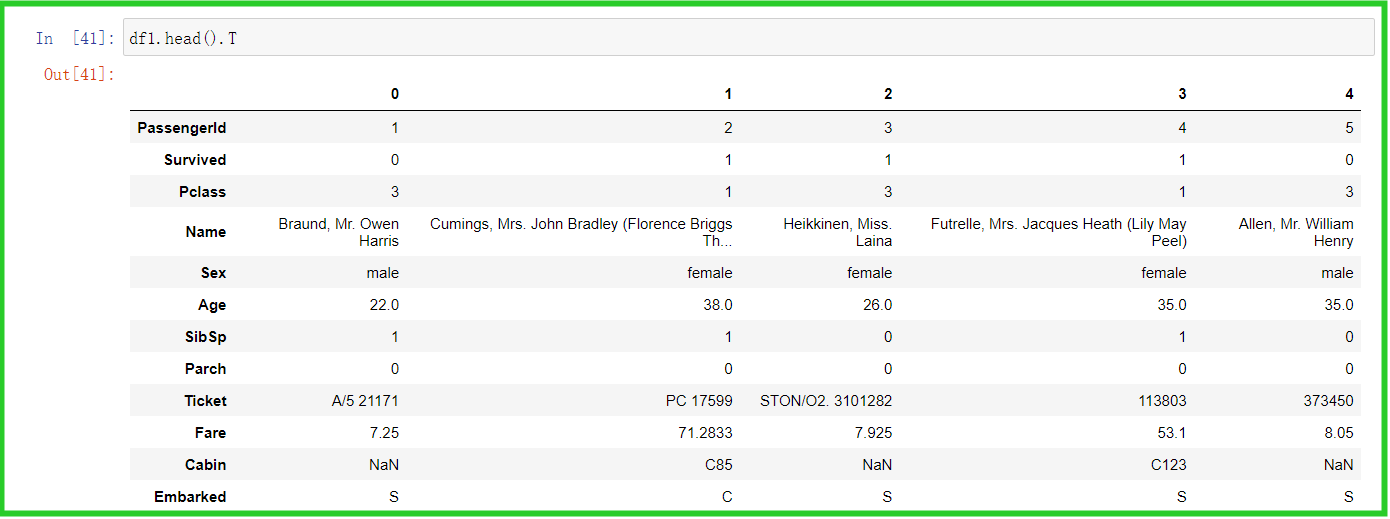
② head().T为转置
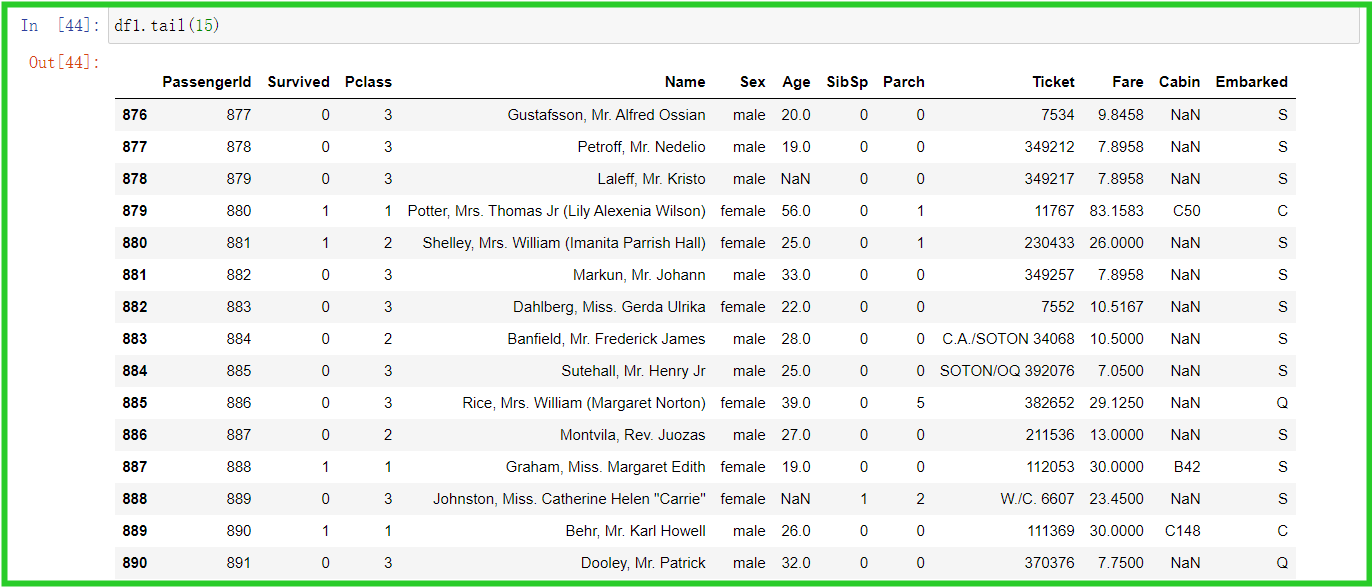
③ tail(num) :参数缺省时为后5行,加参数则num行

④ tail().T为转置

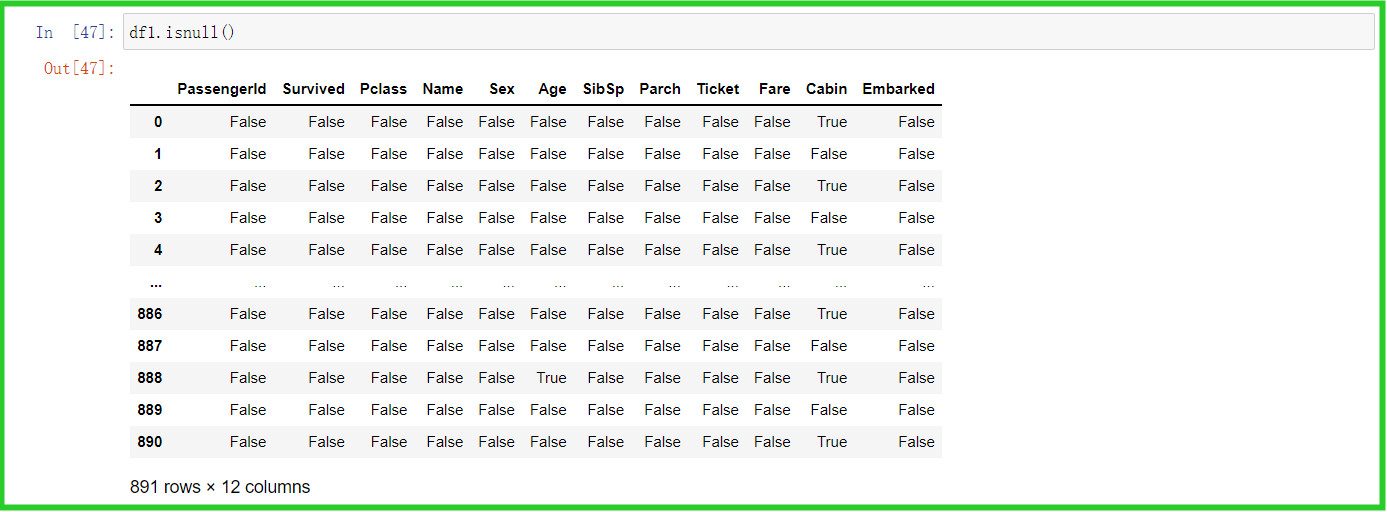
3. 判断数据是否为空,空返回true,其余范围false
① isnull():判断是否为空
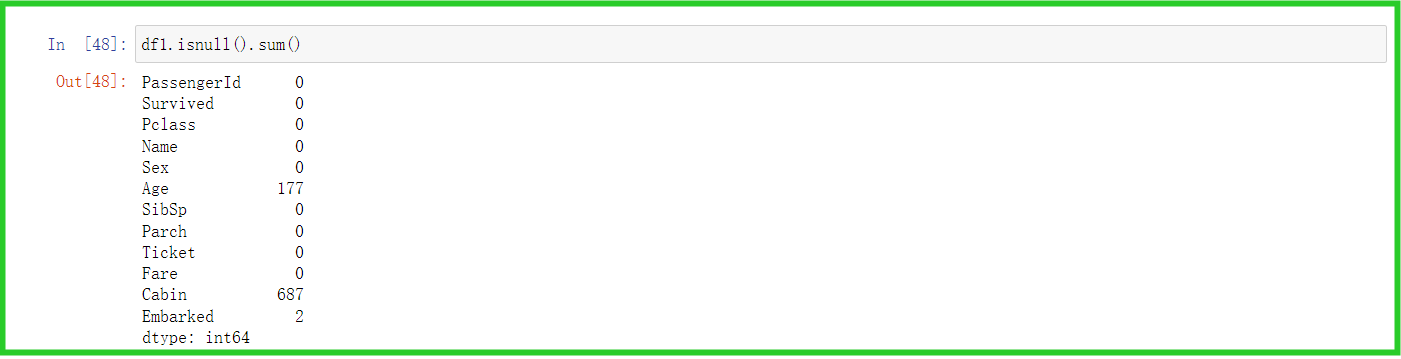
② isnull().sum() :空数据汇总
4. 保存文件为train_chinese.csv
① to_csv()
df7.to_csv('train_chinese.csv')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号