20200917-2 词频统计
此作业的要求参见https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11207
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。
重点/难点 :
(1)如何将py文件转化为exe文件
官网教程:
(2)英文字符的冗余校验和删除
重要代码展示:
字符预处理:
def word_counter(file): ... # 打开文件 with open(file) as f: for line in f: # 从文件流中读取一行文本,赋值到变量line # 使用正则表达式替换文本中的字符,将\r, \n, ., " 替换为空格 line = re.sub('\r|\n|\.|,|\"', ' ', line) # 将文本中连续的空格去除 line = re.sub(' +', ' ', line) # 将替换好的文本的字符转换为小写 line = line.lower() # 将文本按空格分割为单词 words = line.split(" ")
词频统计:
for word in words: # 处理每一个词 if len(word) == 0: continue if word in counter_dic.keys(): # 检查单词是否在字典中 # 在,该词对应的值加1 counter_dic[word] = counter_dic[word] + 1 else: # 不在,向字典添加这个词,并将对应的值赋值为1 counter_dic[word] = 1 counter = counter_dic keys = sorted(counter, key=counter.get, reverse=True)
执行效果截图:

功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
重点/难点 :使用open函数读文件,根据空格数将单词存入document计算词频
重要代码展示:
# 检查文件是否存在 if not os.path.isfile(args.s): print(f"文件 {args.s} is inexistence.", file=sys.stderr) #exit(-1) try: counter = word_counter(args.s) keys = sorted(counter, key=counter.get, reverse=True) print(f"total {len(counter.keys())}\n") # 打印总词数 # 打印前20个词的信息 for key in keys[:20]: print(f"{key} {counter[key]}") except Exception: print(f"{args.s} fail.")
执行效果截图:
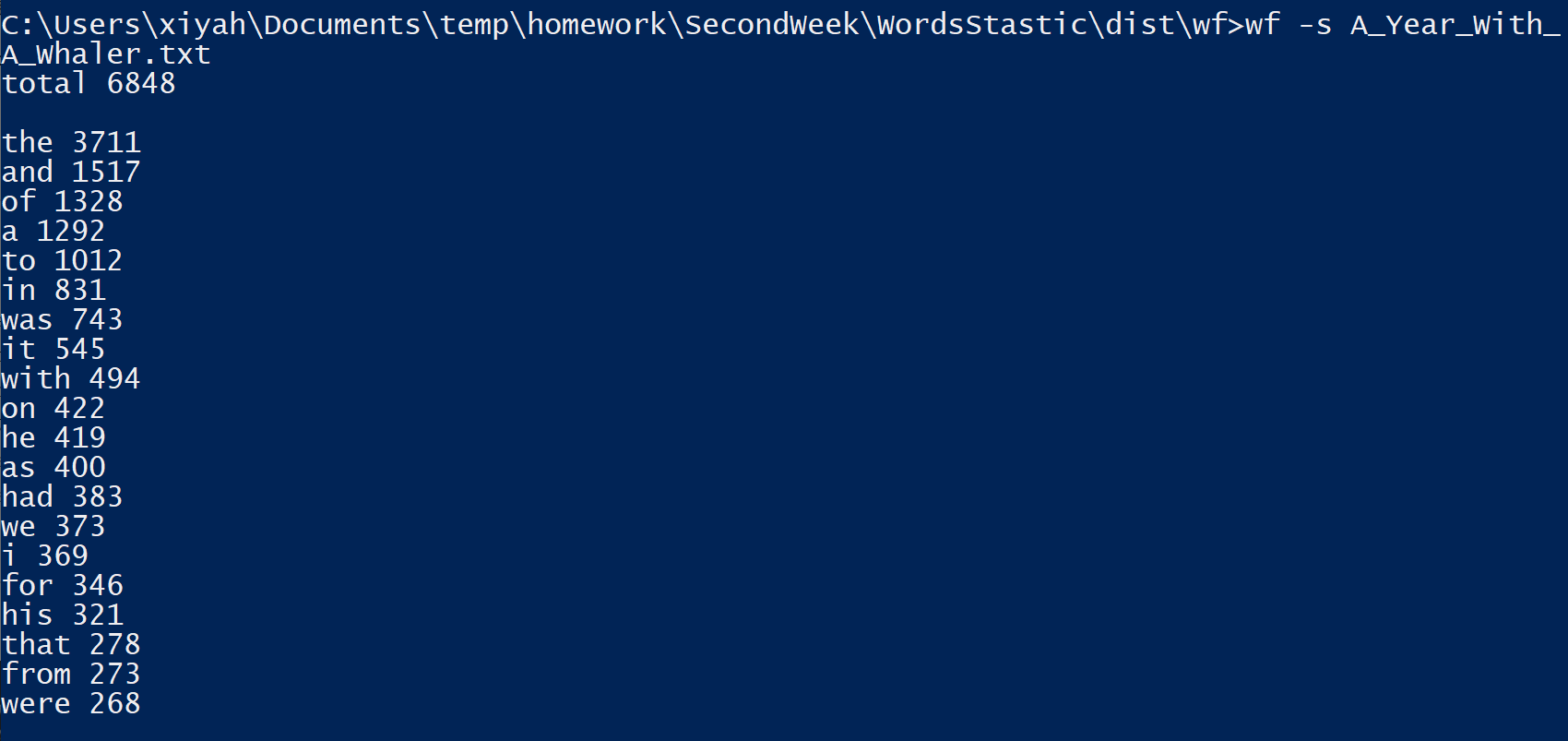
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
重点/难点 :利用流边读取边处理。
重点代码展示:
if not os.path.isdir(args.folder): # 文件不存在,抛出文件不存在异常 print(f"文件夹 {args.folder} 不存在,请检查后重试。", file=sys.stderr) sys.exit(-1) # 文件夹存在,处理每一个文件 # 列出文件夹的全部文件 files = os.listdir(args.folder) # for file in files: for i, file in enumerate(files): try: counter = word_counter(os.path.join(args.folder, file)) # 按counter字典的值对字典进行倒序排序,获取排序后的字典key keys = sorted(counter, key=counter.get, reverse=True) # 输出结果 print(file) # 打印文件名 print(f"total {len(counter.keys())}\n") # 打印总词数 # 打印前20个词的信息 for key in keys[:20]: print(f"{key} {counter[key]}")
执行效果截图:

功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋
友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管
这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
重点/难点 :对于重定向的理解和实践
重点代码展示:
text = input()
执行效果图:

PSP表格
| psp阶段 | 预计花费时间 | 实际花费时间 | 原因 |
| 功能1 | 100min | 196min | 由于对python不熟悉,在处理冗余字符和理解open()函数上花费了大量时间 |
| 功能2 | 120min | 117min | 由于功能2是对功能1的复用,所以相对顺利些 |
| 功能3 | 105min | 212min | 研究读取流和文件中词频统计的方法 |
| 功能4 | 150min | 167min | 花了很多时间去理解重定向的概念 |
代码及版本控制
GitHub中代码地址:https://github.com/siahu/Word.git
coding.net中代码地址:https://siahu.coding.net/public/WordsStastic/Words/git/files

 浙公网安备 33010602011771号
浙公网安备 33010602011771号