《机器学习实战》菜鸟学习笔记(二)kNN示例
目的:改进约会网站配对效果
数据样本 下载地址 (百度网盘)
读取txt数据的代码
1 def file2matrix(filename): 2 fr = open(filename) 3 arrayOfLines = fr.readlines() 4 numberOfLines = len(arrayOfLines) 5 retMat = zeros((numberOfLines,3)) 6 classLabelVector = [] 7 index = 0 8 for line in arrayOfLines: 9 line = line.strip() 10 listFromLine = line.split('\t') 11 retMat[index,:] = listFromLine[0:3]#attention 12 classLabelVector.append(int(listFromLine[-1]))#why int 13 index += 1 14 return retMat,classLabelVector
这段代码没有什么好解释的,注意一点 listFromLine[0:3] 表示的是0,1,2下标的值(不包含3)
matplotlib
matplotlib可以认为是python下的MATLAB,集成了各种画图api。给个比较好的教程 点击链接
作图代码
1 import kNN 2 from numpy import * 3 import matplotlib 4 import matplotlib.pyplot as plt 5 6 group,labels = kNN.createDataSet() 7 kNN.classify0([0,0],group,labels,3) 8 datingDataMat,datingLabels = kNN.file2matrix('F:\Documents\Python Code\machinelearninginaction\Ch02\datingTestSet2.txt') 9 fig = plt.figure() 10 ax = fig.add_subplot(1,1,1) 11 ax.scatter(datingDataMat[:,1],datingDataMat[:,2], 12 15.0*array(datingLabels),15.0*array(datingLabels)) 13 plt.show()
这段代码中需要注意的可能就只有几点:
1. fig.add_subplot(1,1,1)表示作一个1*1的图,其中激活第一个图。
2. scatter() 函数,确定横纵坐标,以及图中点的大小以及颜色。
结果如图:
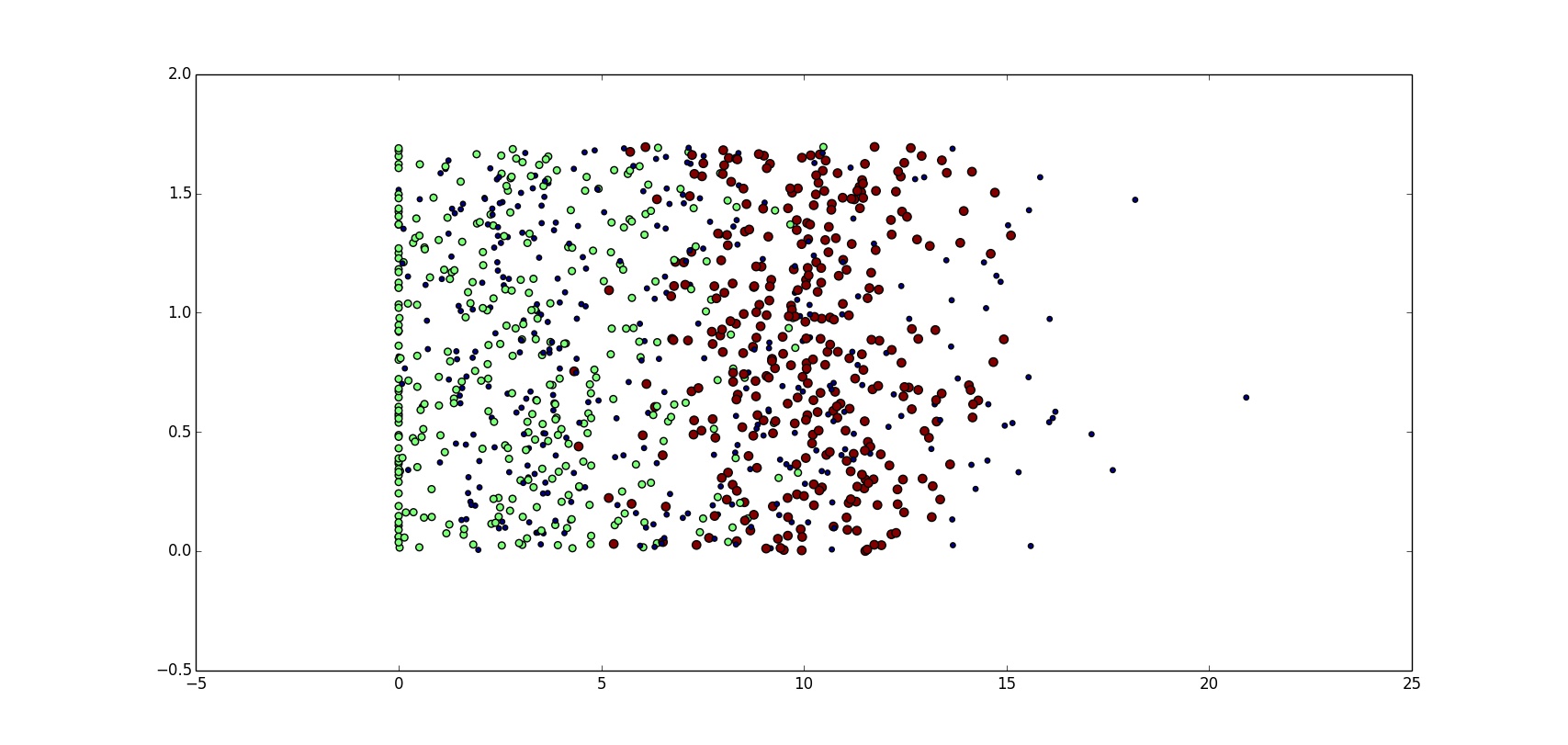
图中的横纵坐标分别表示 玩游戏所耗时间的百分比 以及 每周消费冰激凌公升数,但是我们从图中很难获取到有用的信息。下面我们再来用另外一维数据试试,也就是每年飞行里数这个特征,作图如下(程序与上面那段代码几乎相同):

怎么样,效果立马不一样了吧。
到此为止,可能认为这个问题已经搞定了,给定一个人,只需要看看离他最近的人的分类就可以啦。可是问题在于这个“近”是怎么判定的呢?上面我们用的是欧氏距离,这有木有问题呢?很不幸,有问题,其中一个最明显的问题就是,算了,先看计算距离的公式吧。
((0-67)^2+(20000-32000)^2+(1.1-0.1)^2 )^0.5
发现了没有啊,相对于第二项,第一项和第三项几乎不起任何作用啊!
于是乎,怎么办呢,归一化!下面是归一化的函数:
1 def autoNorm(dataSet): 2 minVals = dataSet.min(0) 3 maxVals = dataSet.max(0) 4 ranges = maxVals - minVals 5 normDataSet = zeors(shape(dataSet)) 6 m = dataSet.shape[0] 7 normDataSet = dataSet - tile(minVals,(m,1)) 8 normDataSet = normDataSet/tile(ranges,(m,1)) 9 return normDataSet,ranges,minVals
归一化是如何实现的呢?首先找到每一列的最小值和最大值,然后求出范围。注意以上的操作都是基于array的,虽然表面看起来是一个数字,但实际上是数组。
这段程序实现的功能就是 (数组 - 数组中的最小值)/(最大值-最小值),于是乎,归一化完成了。
然后测试该算法的准确性。使用随机选取的90%的样本训练,10%的样本检测。代码如下:
1 def datingClassTest(): 2 hoRatio = 0.10 3 datingDataMat,datingLabels = file2matrix('datingTestSet.txt') 4 normMat,ranges,minVals = autoNorm(datingDataMat) 5 m = normMat.shape[0] 6 numTestVecs = int(m*hoRatio) 7 errorCount = 0.0 8 for i in range(numTestVecs): 9 classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],\ 10 datingLabels[numTestVecs:m],3) 11 print "the classifier came back with: %d, the real answer is: %d"\ 12 % (classsifierresult, datingLabels[i]) 13 if (classifierResult != datingLabels[i]):errorCount += 1.0 14 print "the total error rate is: %f" % (errorCount/float(numTestVecs))
这段代码的作用就是检测分类器效果的。
程序首先读取数据,并进行归一化的处理,接着调用了我们之前写的 calssify0 这段分类程序,对normMat中的数据进行分类。
下面给出一段程序,这段程序用于输入用户的信息来预测海伦对他的喜欢程度
def classifyPerson(): #定义喜欢程度 resultList = ['not at all','in small doses','in large doses'] #输入玩游戏时间,飞行公里,和冰激凌消耗量 percentTats = float(raw_input("percentage of time spent playing video games?")) ffMiles = float(raw_input("frequent flier miles earned per year")) iceCream = float(raw_input("liters of ice cream consumed per year")) #建立knn原始数据 datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #特征归一化 normMat,ranges,minVals = autoNorm(datingDataMat) #将输入量建成三个特征 inArr = array([ffMiles,percentTats,iceCream]) #最近邻 classifierResult = classify0((inArr-minVals)/ranges,normMat,datingLabels,3) #输出结果 print "You will probably like this person: ", resultList[classifierResult - 1]
怎么样不难吧?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号