Collaborative Spatioitemporal Feature Learning for Video Action Recognition
Collaborative Spatioitemporal Feature Learning for Video Action Recognition
摘要
时空特征提取在视频动作识别中是一个非常重要的部分。现有的神经网络模型要么是分别学习时间和空间特征(C2D),要么是不加控制地联合学习时间和空间特征(C3D)。
作者提出了一个新颖的neural操作,它通过在可学习的参数上添加权重共享约束来将时空特征encode collaboratively。
特别地,作者沿着体积视频数据的三个正交视图进行二维卷积,这样分别学到了空间表观线索和时间动作线索。
通过在不同视角共享卷积核,空间和时间特征可以协作地被学习到并且互相优化,然后通过加权求和融合互补特征,加权求和的系数是端到端学习到的。
算法性能达到了state-of-the-art的效果并在Moments in Time Challenge2018中夺冠。
基于在不同视角中学到的系数,作者量化了空间和时间特征的贡献,这个分析为模型提供了一定的可解释性,也许为将来的视频识别算法设计提供了一定的指导。
一、引言
时空特征的联合学习对于动作识别任务非常关键,空间特征的提取与图像识别任务类似,可以很轻松地提取出来,但是仍有两个问题没有被解决,一个是如何去学习时间特征,另一个问题是如何将空间特征和时间特征很好地结合起来。解决上述问题有几种尝试:1. 设计时间特征并将时间和空间特征作为输入送到双流网络中。2. 3D卷积网络将时间特征和空间特征紧密纠缠,共同学习,因此时空特征可以直接从网络中学习得到。然而3D卷积网络的大量参数和计算量限制了模型的性能。
作者提出了一种联合时空特征学习操作(CoST),可以在权重共享约束下联合学习时空特征。给出视频序列的3D向量,作者首先从不同的角度将其分解成3个2D图像集合,然后用卷积操作分别对三个图像集合进行卷积。从三个角度得到的视频序列分别是:
- 我们平时见到的\(H-W\)视角,即就是将\(H-W\)看做一个平面,\(T\)作为单独一个维度将该平面扩充。
- \(T-W\)视角,即将\(T-W\)看做一个平面,\(H\)作为一个单独的维度将该平面扩充。
- \(T-H\)视角,即将\(T-H\)看做一个平面,\(W\)作为一个单独的维度将该平面扩充。
这样的设计使得每一帧都包含有丰富的动作信息,而不是在两帧之间有动作信息。使得2D卷积可以直接捕捉到时序动作线索。另外还使得作者可以用2D卷积学习到时空特征而不用3D特征。
不同视图共享参数的原因有:
- 不同视图生成的图像是可以兼容的,从图中可以看到,\(T-H\)和\(T-W\)视同形成的图像中仍然存在像边、角一样的边缘信息。因此可以共享权重。
- C2D网络的卷积核是内在冗余的,可以通过共享权重的方式进行学习时域特征。
- 模型的参数数量大大减少,网络可以更容易地进行训练。
另外,在空间域学习到的特征很容易通过巧妙设计网络结构和预训练参数迁移到时间域中。
不同视角的互补特征通过加权求和得到融合,算法为每一个视角的每一个通道学习出独立的参数,从而可以按需学习出时空特征。基于这些参数,作者可以将时间域和空间域各自的贡献量量化进行一些量化分析。
作者基于CoST操作,构建了一个卷积神经网络。这个网络和C2D相比,CoST可以联合地学习到时空特征,和C3D相比,CoST是基于2D卷积的,CoST连接了C2D和C3D。实验表明,CoST的性能比C2D和C3D都要好。
作者的贡献总结如下:
- 提出了CoST,用2D卷积代替3D卷积学出了时空特征
- 这是第一个将空间和时间特征的重要性定量分析的工作
- CoST性能比C3D以及它的变体要好一些,在大型数据集上达到了state-of-the-art的效果
二、相关工作
介绍了传统的基于手工特征的算法,其中性能最好的是光流引导下沿轨迹的局部特征。介绍了双流网络结构以及LSTM对时序演变的建模。介绍了C3D以及C3D的演变模型。和作者提出的算法最为相似的是Slicing CNN,也是从不同视角学习模型进行crowd video understanding,不同的是,该算法从不同的网络分支中独立地学习出三个视角的特征,最后在网络顶层进行合并。作者是联合学习时空特征,时空特征的聚合在每一层都进行。
三、方法
1. 2D ConNets
C2D模型(图中(a)C2D模型)能够提取出鲁棒的空间特征,但是只用了很简单的策略将空间和时间特征结合起来。作者以C2D为baseline模型,以ResNet作为骨架网络,构建了一个网络结构,如表所示是ResNet-50的结构。
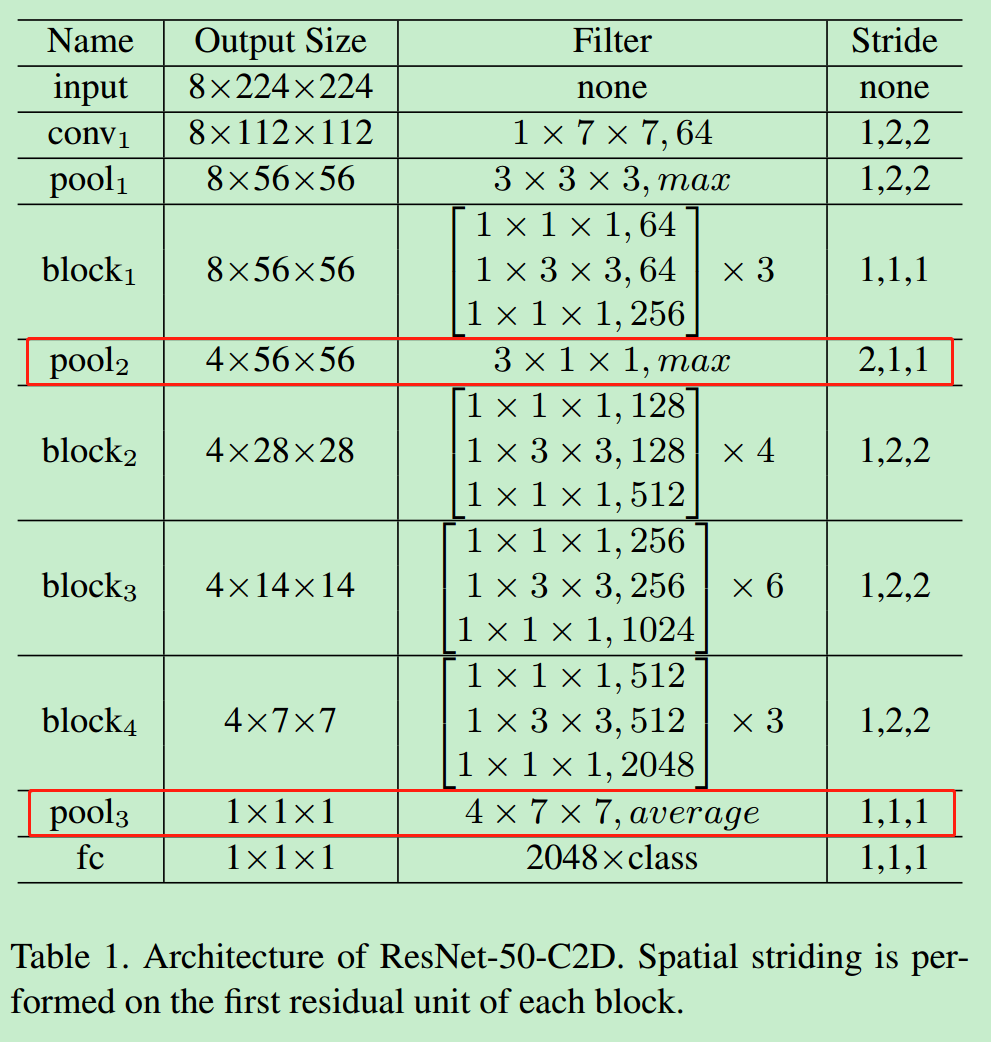
ResNet网络结构
2. 3D ConNets
C3D是C2D的改进,增加了时间维度,将\(h \times w\)的卷积核变成了\(t \times h \times w\)的卷积核。图中(b)和(c)是是C3D的两种卷积方式,很明显地可以看到,(c)的参数量比(b)的参数量要小很多,而且实验结果表明(c)的效果和(b)的效果不相上下,作者采用(c)结构来作为C3D的baseline模型。
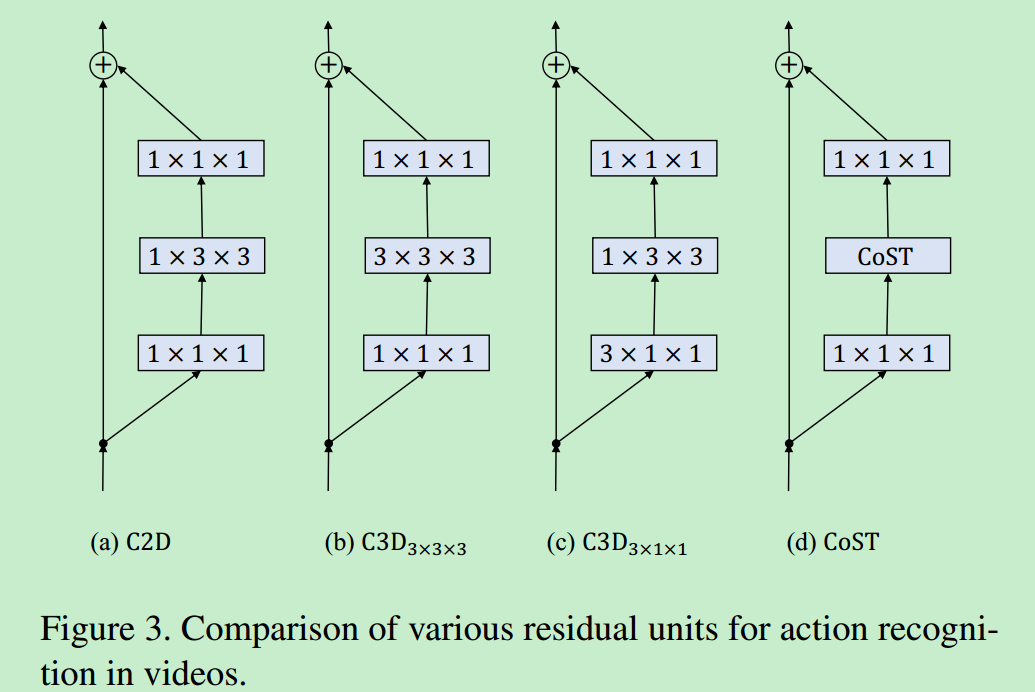
3. CoST
下图对比了CoST操作和\(C3D_{3 \times 3 \times 3}\)和\(C3D_{3 \times 1 \times 1}\),\(C3D_{3 \times 3 \times 3}\)利用3D卷积将时间和空间特征联合提取出来,\(C3D_{3 \times 1 \times 1}\)首先用\({3 \times 1 \times 1}\)的卷积核提取时间上的特征,然后用\({3 \times 3 \times 3}\)的卷积核提取空间特征。作者用3个\(3 \times 3\)的2D卷积核从三个视角分别进行卷积操作,然后通过加权求和将三个特征图进行融合,注意,这里的三个卷积核参数是共享的(代码怎么实现的参数共享呢),参数可以通过端到端的方法去训练。
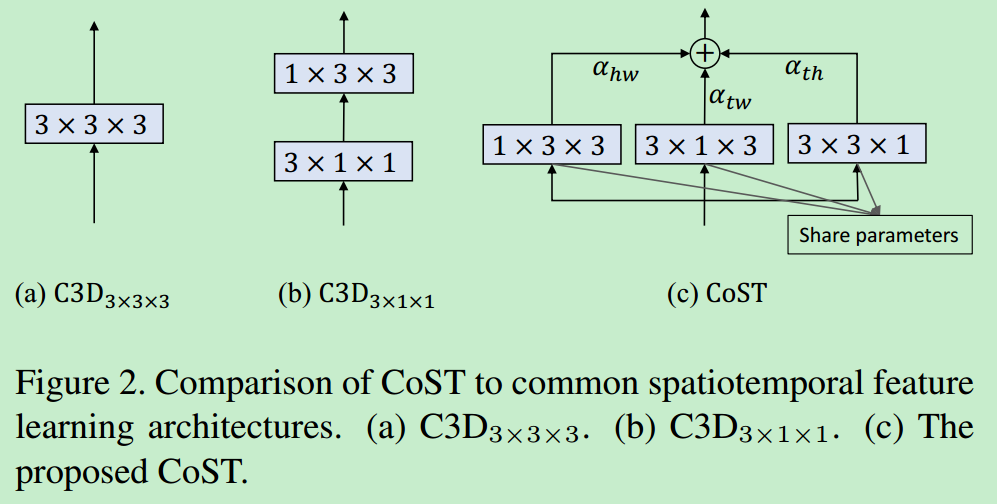
输入的特征大小为\(T \times H \times W \times C_1\),\(C_1\)是输入特征的通道数,三个视角的卷积操作可以表示为:
其中,\(\otimes\)表示3D卷积操作,\(w\)是增加了一个维度的三个视角共享的\(3 \times 3\)的卷积。
这里的卷积可以这样理解:对于\(T-W\)视角,将\(T-W\)看做一个平面,\(H\)看做是平面的堆叠,其中每个平面是有\(C_1\)个通道。如果单独看一个平面,只对一个平面进行卷积操作,则卷积核的大小为\(C_1 \times 3 \times 3\),卷积结果大小为\(T \times W\)。然而从这个视角出发,共有\(H\)个这样的平面,所以对每一个平面都用上述\(C_1 \times 3 \times 3\)的卷积核进行卷积,即每一个平面用完全一样的\(C_1 \times 3 \times 3\)的卷积核进行卷积得到\(T \times W \times H\)大小的特征。因为共有\(C_2\)个卷积核,所以经过卷积后的特征图大小为\(T \times H \times W \times C_2\),上述公式中\(w_{3 \times 1 \times 3}\)中忽略了平面的通道数\(C_1\),并且将\(H\)用\(1\)代替。
得到三个视角的特征后,对其进行加权求和得到该层最终的输出:
\(\boldsymbol{\alpha}=\left[\alpha_{h w}, \alpha_{t w}, \alpha_{t h}\right]\),\(\boldsymbol{\alpha}\)是一个\(C_2 \times 3\)大小的矩阵,其中3表示3个视角。为了避免从多个视图得到的响应发生巨大爆炸,\(\boldsymbol{\alpha}\)用SoftMax函数对每一行进行归一化。
作者设计了两种CoST结构,如图所示:

CoST(a)
系数\(\boldsymbol{\alpha}\)被认为是模型参数的一部分,在反向传播的时候可以被更新,当进行识别的时候参数是固定的
CoST(b)
系数\(\boldsymbol{\alpha}\)是基于特征被网络预测得到的,这个设计灵感来自于最近的自适应机制。每个样本的系数值取决于样本自己。首先用global pooling将三个视角的特征pooling为\(1 \times 1 \times 1\),然后然后用\(1 \times 1 \times 1\)的卷积核进行卷积,这里的参数也是共享的,接着将拼起来的三个特征送到FC层中,最后用Softmax函数进行归一化。
4. 与C2D和C3D的联系
如图所示,如果\(T-W\)和\(T-H\)的系数是0,这时候就退化成C2D了,因此,CoST是严格一般化的C2D
CoST可以看做是特殊化的C3D,3D卷积核参数量是\(k^3\),可以看做是一个\(3 \times 3\)的立方体空间,而CoST的参数量为\(3 k^{2}-3 k+1\),可以看做图中的立方体去了八个角的剩余的部分。如果参数没有共享,CoST非常接近C3D除了八个角的参数被设置成0并且不可以被学习,如果有参数共享,虽然感受野的大小只有19个,对应的19个参数可以从不同视图之间共享的9个可学习参数中派生出来。对于计算量,CoST也远胜于C3D。
三、实验结果
作者在Moments in Time和Kinetics进行了实验,Moments in Time共有来自于339个动作类的802245个训练视频和39900个验证视频,每个视频被修剪得是的持续时间有3秒,Kinetics有236763个训练视频和19095个验证视频分别来自400个人体动作类别,每个视频持续时间有10秒。
1. 实验细节
对于一个视频,采样64个连续的视频帧,然后每隔8帧抽一帧样本,这样对于每一个视频有8个视频帧。从一个按比例缩放的视频中随机裁剪出大小为224×224像素的图像块,该视频的短边随机采样在256到320像素之间。模型用在ImageNet上预训练的2D模型进行初始化。用8个GPU进行训练,为了加快速度,8个GPU被分为两组并且权重在两个组之间异步更新。每个GPU上的mini-batch的大小为8个视频,即对于一个组的四个GPU,总共的mini-batch大小为32。用SGD方法迭代600次,momentum为0.9且weight decay为0.0001.学习率初始化为0.005且在300k和450k次迭代的时候下降10倍。
在推理过程中,作者对短边重调到256像素的视频执行空间完全卷积推理。而对于时域,从一个完整的视频中平均采样10个片段,并分别计算它们的分类分数。最后的预测是所有剪辑的平均得分。
2. 消融实验
分别在两个数据集上验证了CoST(b)的效果更好、共享权重效果更好、CoST的效果比C2D和C3D的效果更好。
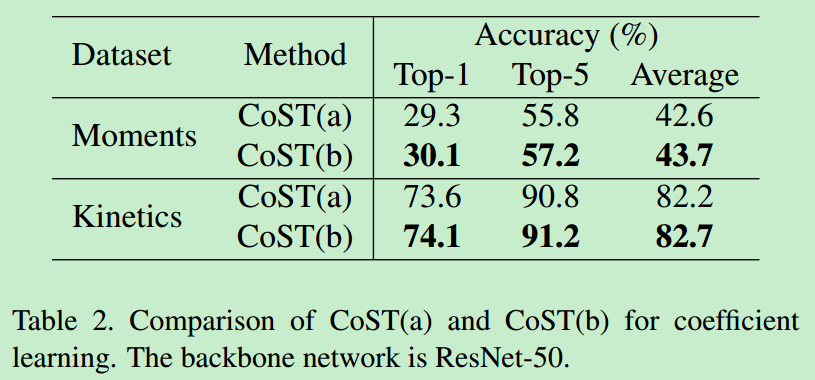

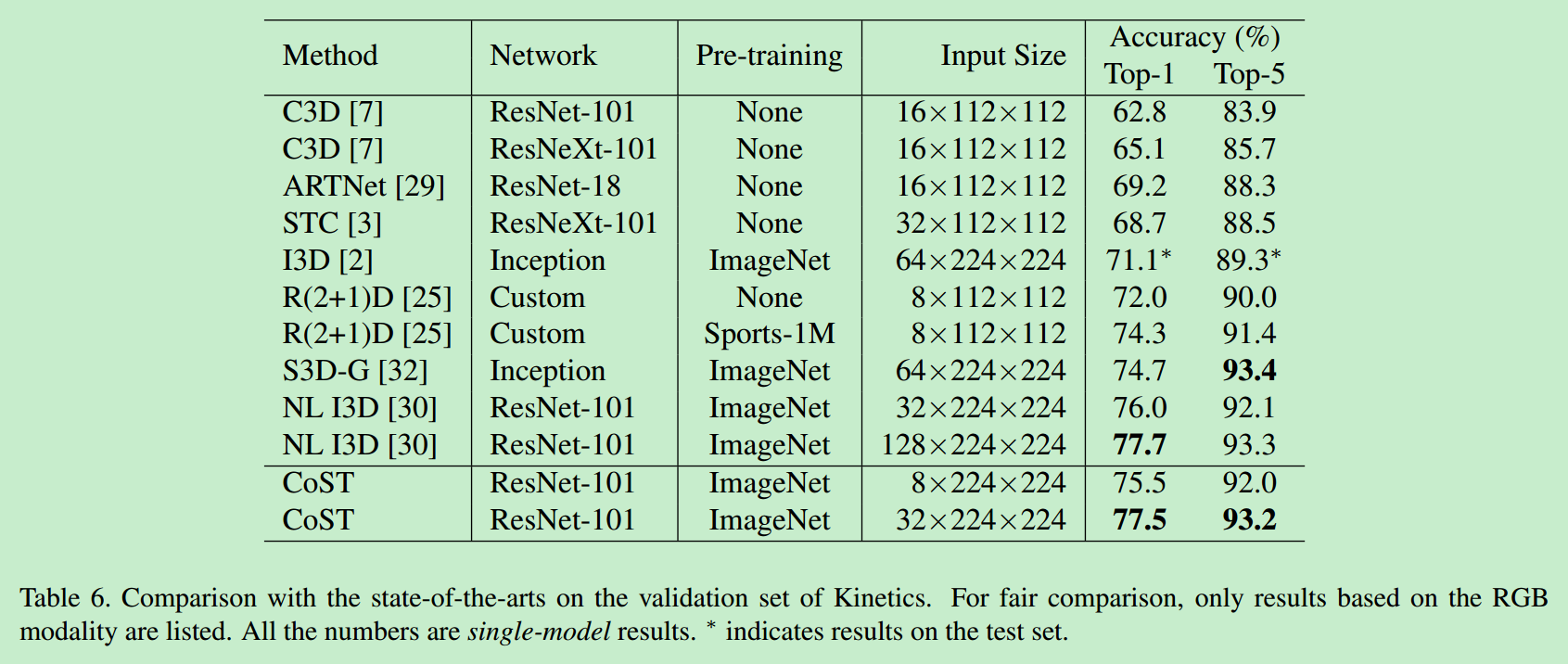
3. 和state-of-the-art相比
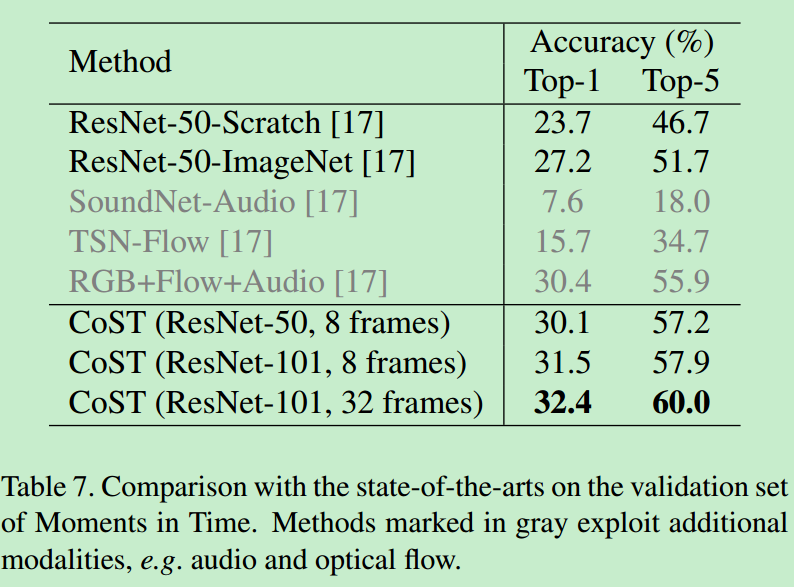
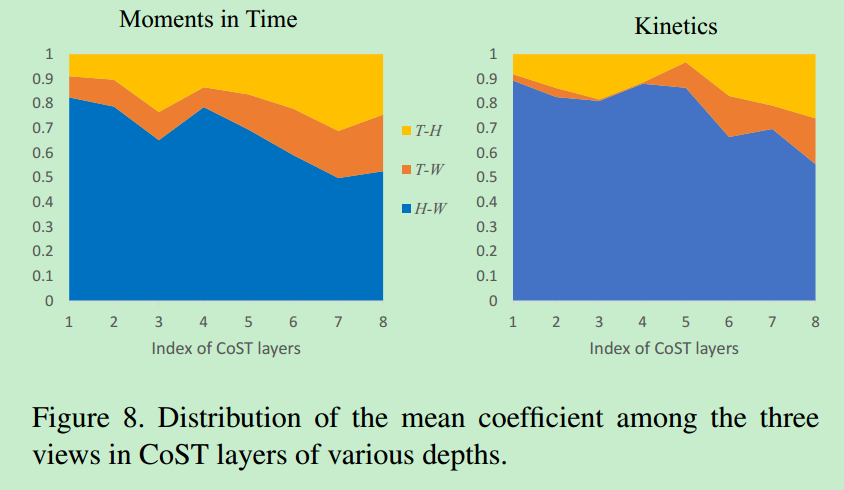
4. 不同视角的重要性
作者将\(W-H\)视角的系数定义为空间特征的影响力,将\(T-W\)和\(T-H\)视角的系数定义为时间特征的影响力。从图8可以看到空间特征在两个数据集上的作用都非常重要,Moments in Time比Kinetics更需要时间特征。随着层数的增加,空间特征的影响力在下降,时间特征的影响力在上升,说明网络底层更关注空间特征的学习,网络高层更关注时间特征的提取。而且作者还用一些实例化的图像来说明对于一些视频样本,时间特征更重要,对于另外一些视频样本,空间特征更重要。

5. 讨论
对于视频分析,如何高效地对时空特征进行编码仍然是一个开放性的问题。虽然实验表明参数共享在一定程度上提升了动作识别的性能,但是空间维度T是否可以被当做一个普通的空间维度,从直观上来讲,空间特征和时间动作是属于两种不同的模态信息。促使作者协同学习的动机是不同视图的可视化(如图1所示)。有趣的是,我们的实验结果表明,至少在某种程度上,它们具有相似的特征,可以使用具有相同网络架构的单一网络共同学习并且共享卷积内核。 在物理学中,根据Minkowski时空,三维空间和一维时间可以统一为四维连续体。 作者的发现可能在特征表示学习的背景下由时空模型解释和支持。
四、结论
从3D视频数据中学习特征是动作识别的主要挑战,在本文中,作者提出了一种新颖的特征学习操作,它从多个视角联合学习时空特征。 它可以很容易地用作C2D和C3D的直接替代品。在大规模的数据集上验证了作者提出的关键的优越性。基于不同视角学习到的系数,可以看到空间和时间特征对动作识别任务的具体贡献量。系统分析表明了一些有前途的算法设计方向,将来的工作将向这方面发展。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号