Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition (ST-GCN)
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
摘要
动态人体骨架模型带有进行动作识别的重要信息,传统的方法通常使用手工特征或者遍历规则对骨架进行建模,从而限制了表达能力并且很难去泛化。
作者提出了一个新颖的动态骨架模型ST-GCN,它可以从数据中自动地学习空间和时间的patterns,这使得模型具有很强的表达能力和泛化能力。
在Kinetics和NTU-RGBD两个数据集上achieve substantial improvements over mainstream methods(与主流方法相比,取得了质的提升)
一、引言
(引言是摘要的详细扩充版本,从引言可以看出,用一个新的方法做一个问题,要调查这个问题的其他解决方法,指出目前的方法的弊端,另外还需要对这个新的方法进行介绍,指出前人没有用此方法解决该问题,然后介绍自己的方法)
动作识别可以从人体的多种形态去识别,比如外形、深度、光流、身体骨架,但是人们对外形和光流的研究比较多,对包含有大量信息的动态骨架研究较少,作者提出了一种有原则的、高效的方法对动态骨架进行建模
现今对人体动态骨架的研究:早期的算法利用动态骨架的时序信息而忽略了空间信息;后来提出的算法大多数都依赖于人工制定的原则去分析骨架的空间模式,这样的只针对某一个特定应用的方法很难去泛化。
作者需要提出一种方法,可以自动捕捉(嵌套在关节空间结构以及其时序动态)中的模式。
GCN被应用在像图像分类、文献分类、半监督学习等任务中,然而很多任务都是将一个固定的图作为输入。用GCN去对动态图在大规模数据集上进行建模还没有被研究,比如人体骨架序列。
作者通过将图卷积网络扩展到时空图模型,设计了一种(用于动作识别的骨架序列)的通用表示,叫做时空图卷积网络。
模型建立在骨架图构成的序列之上,其中的每一个点都对应人体骨架结构中的每一个节点。这里有两种类型的边,一种是空间边(spatial edges)它建立在每一帧人体骨架的自然连接节点上,另外一种是时序边(temporal edges)它将连续两帧中相同节点连接起来。时空图卷积网络中的很多层也根据他们建立起来了,这就使得信息在时间和空间域被整合起来了。
层级性的ST-GCN避免了手动设计遍历规则,这不仅使得表达能力更强并且性能更好,同时也很容易在不同的场景中泛化。在通用的GCN表达之上,作者在图像模型的启发下,学习了新的策略去设计图卷积核。
总结:
- 提出了ST-GCN,一个通用的基于图的框架去对动态人体骨架进行建模
- 在ST-GCN中提出了几个卷积核设计规则去满足骨架模型特殊的要求
- 与原始的基于手工部分和遍历规则的算法相比,作者提出的方法在两个大规模的基于骨架的动作识别数据集上取得了优越的性能,并且大大减少了人工设计。
二、相关工作
图卷积网络主要有两种主流方法:
- 基于光谱的观点(spectral perspective)图卷积中的位置信息被看做是以光谱分析的形式。
- 基于空间的观点(spatial perspective)卷积核直接被应用在图节点和他们的邻居节点。
- 作者采用第二种做法,限制每一个滤波只应用到一个节点的一个邻域
基于骨架的动作识别:
- 基于手工特征的方法,设计几种手工特征去捕获连接点的运动信息,比如,关节点轨迹的协方差矩阵
- 基于深度学习的方法,循环神经网络,端到端进行动作识别(Among these approaches, many have emphasized the importance of modeling the joints within parts of human bodies. But these parts are usually explicitly assigned using domain knowledge.)
- 作者是第一个将图卷积网络应用在基于骨架的动作识别任务中的。它和以前的方法都不同,可以隐式地通过图卷积网络将位置信息和时序动态信息结合起来。
三、时空图卷积网络
在现有的基于骨架的动作识别方法中提出,body parts的信息对于基于骨架的动作识别非常有效。作者提出,性能的提升主要是body parts比整个骨架具有更多的局部特征,因此有了用局部信息层级表示的骨架序列,因此有了ST-GCN
1. pipeline
给出一个动作视频的骨架序列信息,首先构造出表示该骨架序列信息的图结构,ST-GCN的输入就是图节点上的关节坐标向量,然后是一系列时空图卷积操作来提取高层的特征,最后用SofMax分类器得到对应的动作分类。整个过程实现了端到端的训练。
2. 构造骨架的图结构
记一个有\(N\)个节点和\(T\)帧的骨骼序列的时空图为\(G=(V,E)\),其节点集合为\(V=\left\{v_{t i} | t=1, \ldots, T, i=1,...,N\right\}\),第\(t\)帧的第\(i\)个节点的特征向量\(F\left(v_{t i}\right)\)由该节点的坐标向量和估计置信度组成。
图结构由两个部分组成:
- 根据人体结构,将每一帧的节点连接成边,这些边形成spatial edges \(E_{S}=\left\{v_{t i} v_{t j} |(i, j) \in H\right\}\) H是一组自然连接的人体关节
- 将连续两帧中相同的节点连接成边,这些边形成temporal edges \(E_{F}=\left\{v_{t i} v_{(t+1) i}\right\}\)
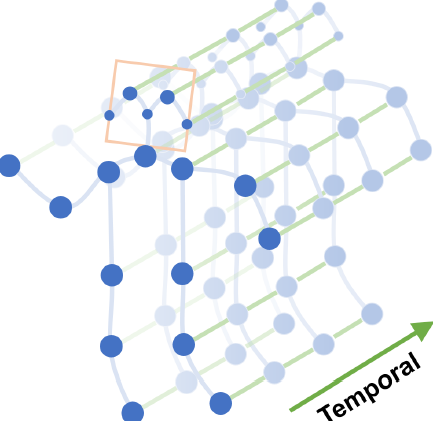
3. 空间图卷积网络
在这里只针对某一帧讨论图卷积模型操作
以常见的图像的二维卷积为例,针对某一位置\(\mathbf{x}\)的卷积输出可以写成如下形式
输入通道数为\(c\)的特征图\(f_{in}\),卷积核大小\(K*K\),sampling function采样函数\(\mathbf{p}(\mathbf{x}, h, w)=\mathbf{x}+\mathbf{p}^{\prime}(h, w)\),weight function通道数为\(c\)的权重函数。
(1)sampling function
在图像中,采样函数\(\mathbf{p}(h,w)\)指的是以\(x\)像素为中心的周围邻居像素,在图中,邻居像素集合被定义为:\(B\left(v_{t i}\right)=\left\{v_{t j} | d\left(v_{t j}, v_{t i}\right) \leq D\right\}\),\(d(v_{tj},v_{ti})\)指的是从\(v_{tj}\)到\(v_{ti}\)的最短距离,因此采样函数可以写成\(\mathbf{p}\left(v_{t i}, v_{t j}\right)=v_{t j}\),这里的\(\mathbf{p}\left(v_{t i}, v_{t j}\right)=v_{t j}\)。
(2)weight function
在2D卷积中,邻居像素规则地排列在中心像素周围,因此可以根据空间顺序用规则的卷积核对其进行卷积操作。类比2D卷积,在图中,将sampling function得到的邻居像素划分成不同的子集,每一个子集有一个数字标签,因此有\(l_{t i} : B\left(v_{t i}\right) \rightarrow\{0, \ldots, K-1\}\)将一个邻居节点映射到对应的子集标签,权重方程为\(\mathbf{w}\left(v_{t i}, v_{t j}\right)=\mathbf{w}^{\prime}\left(l_{t i}\left(v_{t j}\right)\right)\)
(3)空间图卷积
其中归一化项\(Z_{t i}\left(v_{t j}\right)=\left|\left\{v_{t k} | l_{t i}\left(v_{t k}\right)=l_{t i}\left(v_{t j}\right)\right\}\right|\),等价于对应子集的基。将上述公式带入上式得到:
(4)时空模型
将空间域的模型扩展到时间域中,得到的sampling function为\(B\left(v_{t i}\right)=\left\{v_{q j}\left|d\left(v_{t j}, v_{t i}\right) \leq K,\right| q-t | \leq\lfloor\Gamma / 2\rfloor\right\}\),\(\Gamma\)控制时间域的卷积核大小,weight function为\(l_{S T}\left(v_{q j}\right)=l_{t i}\left(v_{t j}\right)+(q-t+\lfloor\Gamma / 2\rfloor) \times K\),看不懂
4. 划分子集的方式
(1)唯一划分 Uni-labeling:将节点的1邻域划分为一个子集
(2)基于距离的划分 Distance partitioning:将节点的1邻域划分为两个子集,节点本身子集与邻节点子集
(3)空间构型划分 Spatial configuration partitioning:将节点的1邻域划分为3个子集,第一个子集连接了空间位置上比根节点更远离整个骨架的邻居节点,第二个子集连接了更靠近中心的邻居节点,第三个子集为根节点本身,分别表示了离心运动、向心运动和静止的运动特征

5. 注意力机制
在运动过程中,不同的躯干重要性是不同的。例如腿的动作可能比脖子重要,通过腿部我们甚至能判断出跑步、走路和跳跃,但是脖子的动作中可能并不包含多少有效信息。
因此,ST-GCN 对不同躯干进行了加权(每个 st-gcn 单元都有自己的权重参数用于训练)
6. TCN
GCN 帮助我们学习了到空间中相邻关节的局部特征。在此基础上,我们需要学习时间中关节变化的局部特征。如何为 Graph 叠加时序特征,是图网络面临的问题之一。这方面的研究主要有两个思路:时间卷积(TCN)和序列模型(LSTM)。
ST-GCN 使用的是 TCN,由于形状固定,我们可以使用传统的卷积层完成时间卷积操作。为了便于理解,可以类比图像的卷积操作。st-gcn 的 feature map 最后三个维度的形状为\((C, V, T)\),与图像 feature map 的形状\((C, W, H)\)相对应。
- 图像的通道数\(C\)对应关节的特征数\(C\)。
- 图像的宽\(W\)对应关键帧数\(V\)。
- 图像的高\(H\)对应关节数\(T\)。
在图像卷积中,卷积核的大小为『w』\(\times\)『1』,则每次完成 w 行像素,1 列像素的卷积。『stride』为 s,则每次移动 s 像素,完成 1 行后进行下 1 行像素的卷积。
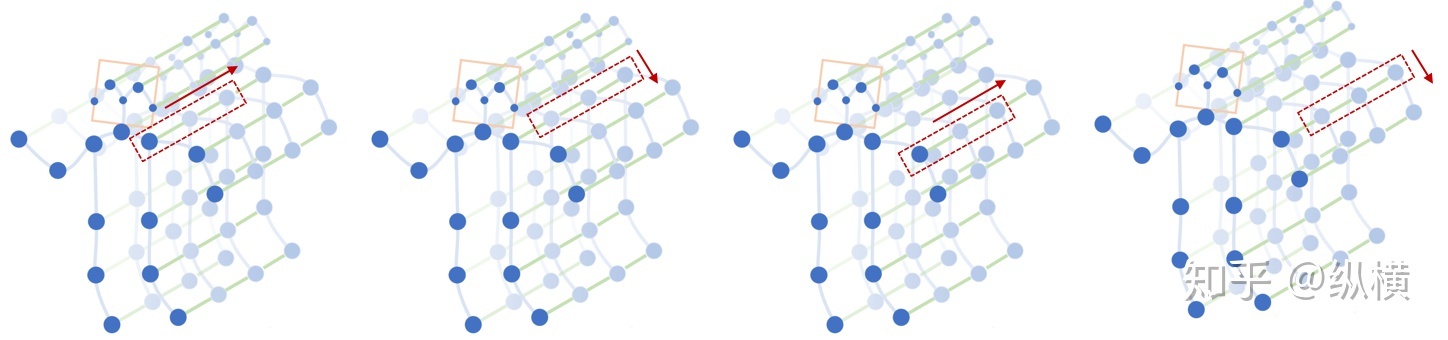
在时间卷积中,卷积核的大小为『temporal_kernel_size』\(\times\) 『1』,则每次完成 1 个节点,temporal_kernel_size 个关键帧的卷积。『stride』为 1,则每次移动 1 帧,完成 1 个节点后进行下 1 个节点的卷积。
7. ST-GCN的实现
实际项目中使用的图卷积公式是
化简:
论文中的公式(不太懂):
其中,\(\Lambda^{i i}=\sum_{j}\left(A^{i j}+I^{i j}\right)\)
当采用第二种和第三种划分策略时,\(A+I=\sum_{j} A_{j}\):
其中,\(\Lambda_{j}^{i i}=\sum_{k}\left(A_{j}^{i k}\right)+\alpha\),\(\alpha=0.001\)
增加注意力机制后,上式中的\(\mathbf{A}_{j}=\mathbf{A}_{j} \otimes \mathbf{M}\),\(\otimes\)表示点积
8. 网络结构与训练

输入的数据首先进行batch normalization,然后在经过9个ST-GCN单元,接着是一个global pooling得到每个序列的256维特征向量,最后用SoftMax函数进行分类,得到最后的标签。每一个ST-GCN采用Resnet的结构,前三层的输出有64个通道,中间三层有128个通道,最后三层有256个通道,在每次经过ST-CGN结构后,以0.5的概率随机将特征dropout,第4和第7个时域卷积层的strides设置为2。用SGD训练,学习率为0.01,每10个epochs学习率下降0.1。
在训练Kinetcis数据集时,采用两种策略代替dropout层:1. random moving:在所有帧的骨架序列上应用随机仿射变换,fixed angle、translation、scaling factors。2. 在训练中随机抽取原始骨架序列的片段,并在测试中使用所有帧不太懂
四、实验
1. 实验数据集:
Kinetics human action dataset 和 NTU-RGB+D
2. 实验环境:
8 TITANX GPUs 和 PyTorch
3. Kinetics:
300,000个视频序列,400类动作,每个视频持续10秒,unconstraint
数据处理流程:resize(340*256)-->30fps-->OpenPose-->18个节点的二维坐标+置信度-->(3,T,18,2)
其中T=300,3表示二维坐标+置信度,18表示节点数目,2表示置信度最高的两个人
测评指标:top-1和top-5
240,000个视频训练,20,000个视频验证
4. NTU-RGB+D
56,000个视频,60类动作,由40个志愿者完成,constraint
25个节点,每个节点用三维坐标表示,每个clip最多有2个对象
测评指标:cross-subject 40320训练 16560测试 cross-view 37920训练 18960测试 top-1
5. Ablation Study

Baseline TCN:Interpretable 3d human action analysis with temporal convolutional networks.(等价于没有共享参数的全连接时空图网络,网络图与ST-GCN不一样)
Loacl Convolution:(没有共享参数的ST-GCN,网络图就是ST-GCN)
Distance partitioning*:bind the weights of the two subsets in distance partitioning to be different only by a scaling factor -1, or w0 = -w1.
ST-GCN+Imp:ST-GCN+注意力机制
6. comparison with state of the art
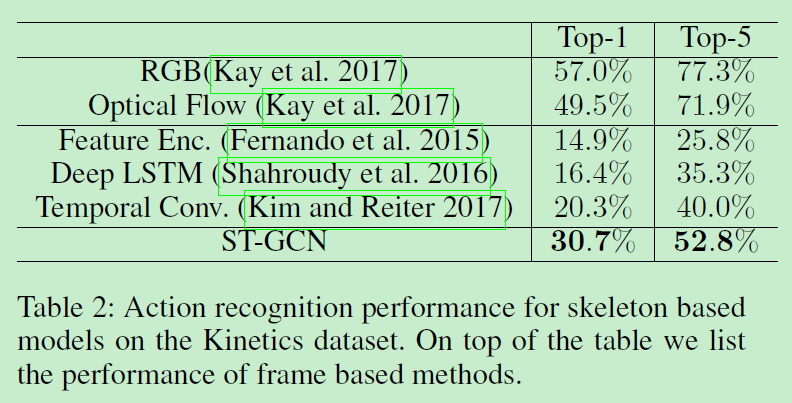
Kinetic:
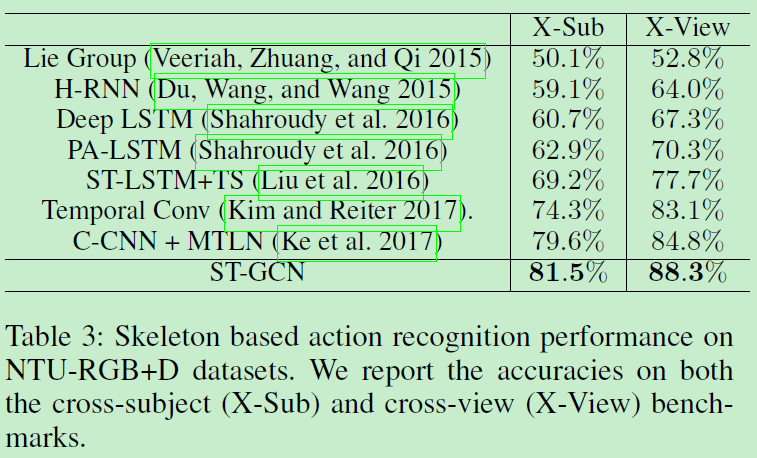
NTU-RGB+D:
7. 讨论
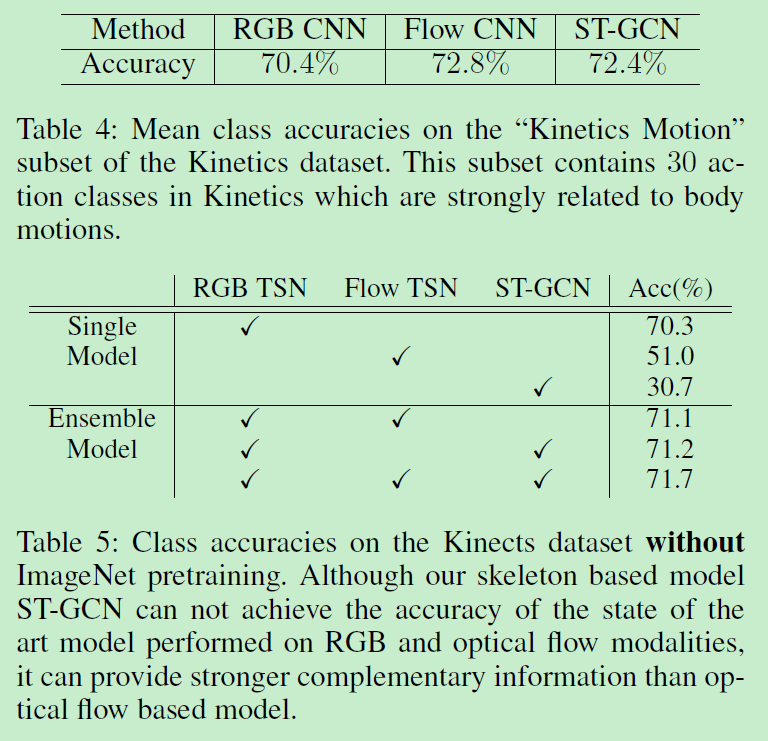
table4:去掉了对象和环境进行交互的视频,留下了人体动作相关的视频进行测试
table5:two-stream style action recognition,不同的输入特征测试
TSN:Temporal segment networks: Towards good practices for deep action recognition.
五、结论
作者提出了一个新颖的基于骨架的动作识别模型ST-GCN,在两个大型数据上的性能都优于现有的基于骨架的算法。作者提出的基于骨架的模型补全了现有的基于RGB模型的不足,ST-GCN模型的灵活性也为未来的工作开辟了许多可能的方向。例如,如何将上下文信息(例如场景、对象和交互)合并到ST-GCN中就成为一个自然的问题。
参考博客:
https://blog.csdn.net/qq_36893052/article/details/79860328
https://www.zhihu.com/question/276101856/answer/385251705
看代码需要理解的问题:图数据的组织形式,卷积核,大小,channel,pad,stride,遍历规则,权重值,正反向传递规则

 浙公网安备 33010602011771号
浙公网安备 33010602011771号