论文阅读: Siam FC
一、研究动机##
- 一方面传统算法设计的跟踪模型过于简单,另一方面深度学习方法很难达到实时效果然而现实场景中的应用对速度要求较高。
- “shallow method”(HCFT)没有很好地利用神经网络端到端的思想,在线更新模型不能达到实时效果。
- 作者提出了一种全连接孪生网络,实现了端到端的训练,它用第一帧的信息训练一个普适的相似性学习模型用,然后用训练好的孪生网络从一个大的搜索图片中选择模板图像(目标),速度超过了实时效果。另外,Siamese的网络结构都是全连接层,并且用稠和有效的滑动窗口技术计算两个特征(搜索区域和模板特征)的相关性。值得注意的是,作者用ImageNet Video中的视频数据训练模型,用OTB/VOT对算法进行测试,避免了训练和测试数据来自同一个域。
二、算法原理##
基本思路:
将第一帧图像目标作为模板图像\(z\) ,将后续个帧图像作为搜索图像\(x\),通过一个学习好的相似性对比函数\(f(z,x)\)在\(x\)上找到和\(z\)最为相像的备选区域作为预测的目标位置。相似度对比函数\(f\)将会用一个标记好的数据集进行训练。作者用深度网络作为相似度对比函数\(f\),将网络作为一种变换\(\varphi\),首先将这种变换分别应用到模板和搜索图像上,产生模板和搜索区域的特征\(\varphi(z), \varphi(x)\),然后用另外一个相似度测量函数\(g\)将他们结合起来\(f(z,x)=g(\varphi(z), \varphi(x))\)。
网络结构:
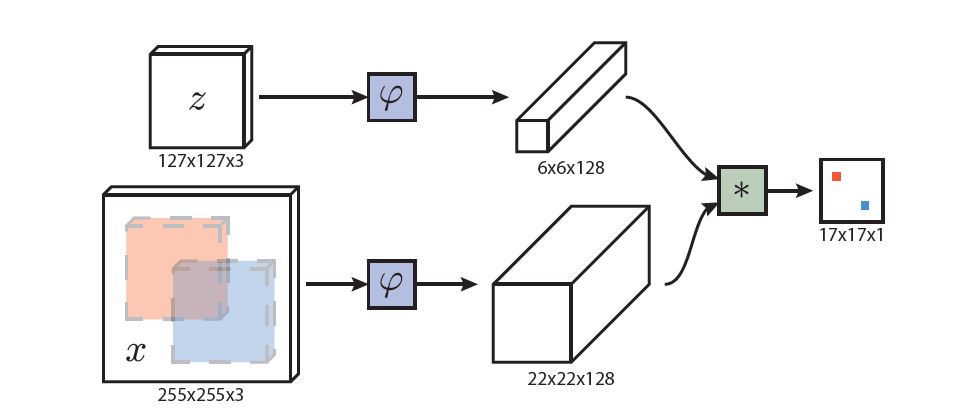

为了给出更精确的定义,给定\(L_{\tau}\)是一种转换操作\(\left(L_{\tau} x\right)[u]=x[u-\tau]\),函数\(h\)作为全卷积网络变换函数,\(k\)是全卷积网络变换的比例因子,则\(h\left(L_{k \tau} x\right)=L_{\tau} h(x)\),表示的含义是:先对\(x\)进行有比例因子的转换操作再进行全卷积操作等同于先对\(x\)进行全卷积操作再进行转换操作。给定每个位置的偏置参数\(b \mathbb{1}\),相似度对比函数还可以表示为\(f(z, x)=\varphi(z) * \varphi(x)+b \mathbb{1}\),表示的含义是:模板区域\(z\)和搜索区域\(x\)经过相同的卷积操作\(\varphi()\)后,用\(*\)操作并加上一定的偏置\(b \mathbb{1}\)得到响应图。
在跟踪过程中,搜索图像是以上一帧目标为中心的,响应图由特征图进行互相关操作(等价于响应图的内积)生成,响应图最大的位置乘以网络的比例因子才是目标的最终位置。另外,作者使用不同尺度的图片作为一个mini-batch进行检测。
注意:SiamFC设计的网络结构将原始图像缩小了8倍,即\(k=8\),并且,该网络没有padding。
模型训练过程###
损失函数:作者用logistic loss\(\ell(y, v)=\log (1+\exp (-y v))\)计算损失,其中\(v\)是对一个样本候选区的打分值,\(y\)是此样本候选区的真实标签\(y \in\{+1,-1\}\)。响应图的损失被定义为响应图中每个位置损失的平均值,即
最后,给定\(x\)和\(z\)是样本对,\(\theta\)是参数,\(f\)是对样本对的打分,用SGD最小化如下损失函数来获得最佳的跟踪模型。
训练数据:作者用大规模搜索图像训练模型,训练数据是由样本对组成的,视频中的第一帧图像中的目标和该视频中的其他相差不超过T帧的图像组成了若干样本对(目标图像和后续帧都组成一个样本对)。每个样本对经过孪生网络生成响应图\(v[u]\)后,\(u \in \mathcal{D}\)(u表示响应图中的每个位置),响应图每个位置对应的标签为\(y[u]\),\(y[u]\)的定义遵循如下规定,表示当响应图中某位置\(u\)和响应图中目标位置\(c\)的距离乘以比例因子\(k\)后小于\(R\)则为正样本。
数据处理:模板图像大小是\(127 \times 127\),搜索区域图像是\(255 \times 255\),给定目标尺寸\((w,h)\),目标周围扩增\(p\),其中\(p=(w+h)/4\),对于模板图像\(A=127^2\),利用尺度变换\(s\)使得新的区域面积等于模板图像面积(\(s\)的变换方式是在原有尺寸不变的前提下填充原图RGB各通道均值像素),在预训练之前,将训练数据组织好以便提高训练速度:
训练细节:模型初始化参数用高斯分布初始化,共迭代50次,每次迭代包含50000个样本对,mini-batch为8,学习率每次迭代从\(10^(-2)\)到\(10^(-5)\).
跟踪过程###
作者只在大约四倍于先前大小的区域内搜索对象,并且在得分图中添加一个cos窗口来惩罚较大的位移。通过处理多个缩放版本的搜索图像,可以实现对缩放空间的跟踪。任何规模的变化都将受到惩罚,并对当前规模的更新进行阻尼。
结合时域信息约束;搜索目标在四倍目标区域;余弦窗口加在打分映射惩罚大的偏移。多尺度跟踪,增强尺度估计的准确性。
(we only search for the object within a region of approximately four times its previous size, and a
cosine window is added to the score map to penalize large displacements. Tracking through scale space is achieved by processing several scaled versions of the search image. Any change in scale is penalized and updates of the current scale are damped.)
在跟踪过程中,初始帧目标的特征图只计算一次,然后它用来和后续帧的特征图进行比较,得到的响应图(得分图)。作者利用双三次插值将\(17 \times 17\)的矩阵转换为\(272 \times 272\)的矩阵,从而定位目标区域。另外,针对搜索图像,还用了5种尺度\(1.025^(\{-2,-1,0,1,2\})\),这些尺度采用了以0.35为步长的线性函数作为抑制。
后期看完代码会补充更多跟踪方面的详细信息。
三、实验结果##
实验设备是NVIDIA GeForce GTX Titan X显卡和Intel Core i7-4790K 4.0GHz处理器。共做了两种不同的算法版本,一种是5种尺度SiamFC,另一种是3种尺度SiamFC-3s,分别在OTB2013和VOT数据集上进行了测试。
OTB2013###
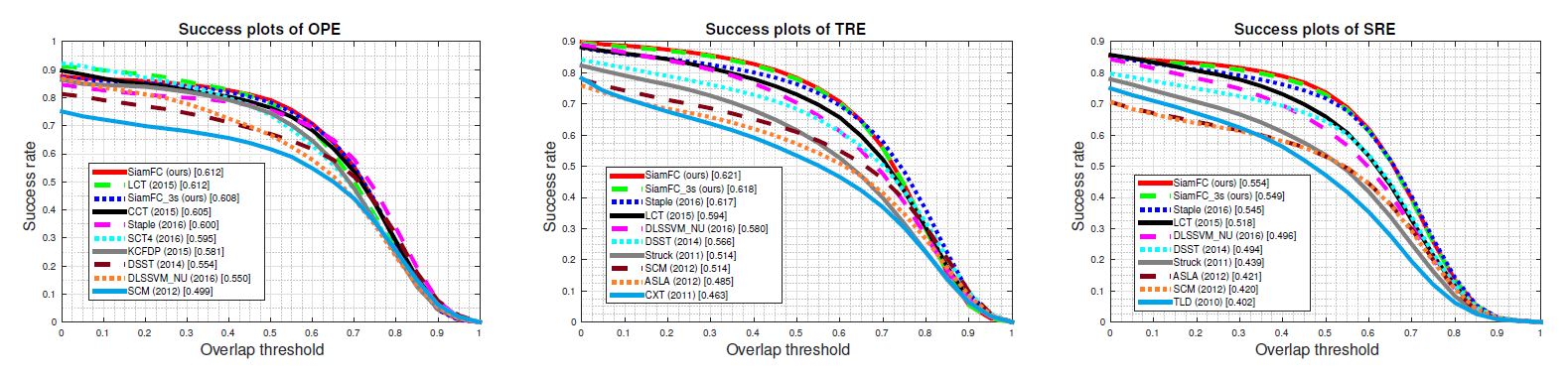
在测试过程中,作者将25%对图像样本转化为灰度图像,其余不变,效果如下。可以看到SiamFC和SiamFC-3s的效果都居于前两名。其中单次成功率OPE可达0.62,时间鲁棒性TRE(将不同帧打乱)可达0.612,而空间鲁棒性SRE(从帧内不同框位置开始)可达0.564。
VOT###
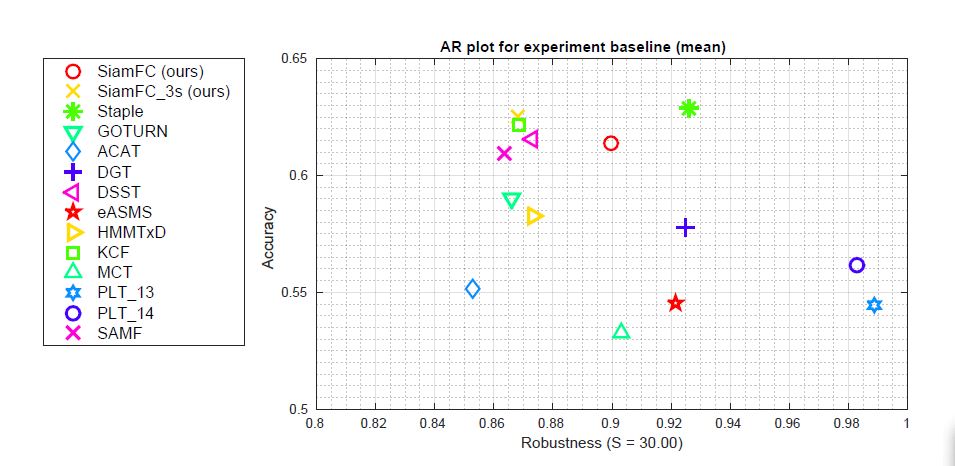
VOT-2014结果:除了和VOT2014的前十名的跟踪算法相比,还另外加入了Staple和GOTURN。算法主要两个评价指标:accuracy和robustness,前者是计算平均IOU,后者是计算总是失败帧数。下图显示了Accuracy-Robustness plot(按照accuracy和robustness分别进行排名,再进行平均)。
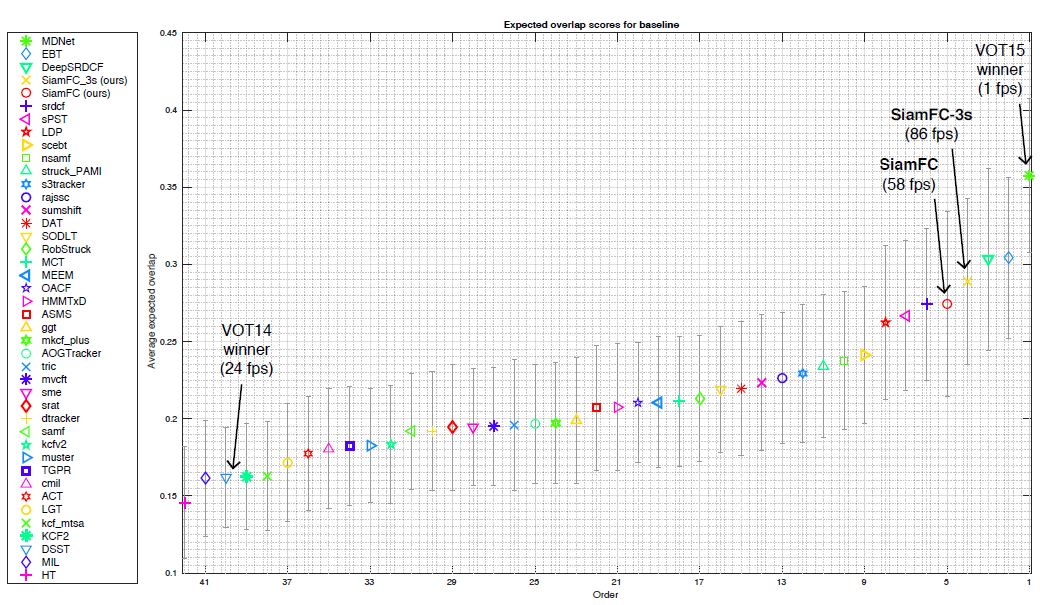
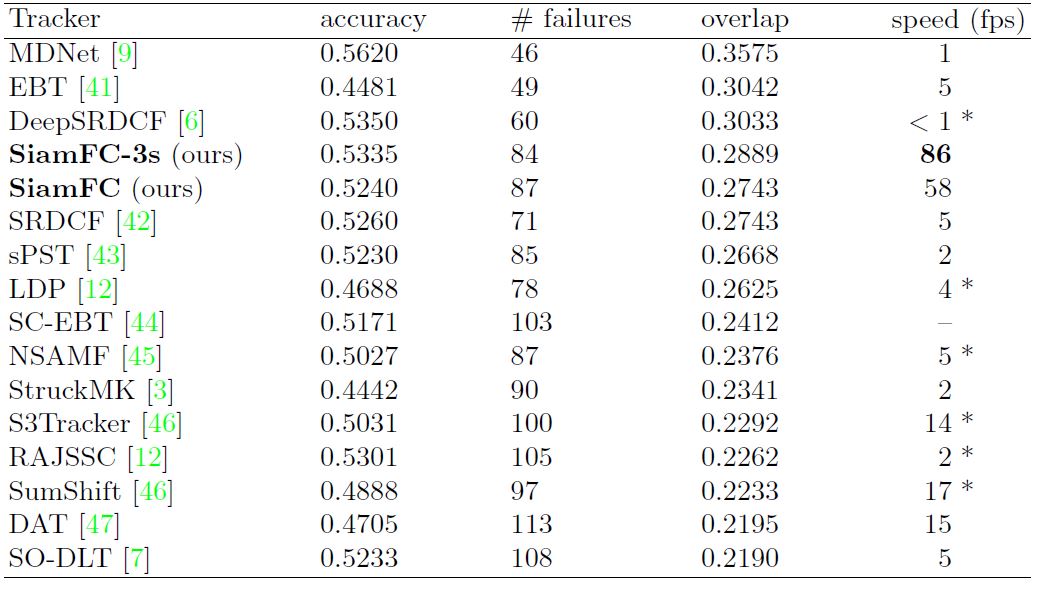
VOT-2015结果:下图显示了VOT-2015排名前41名的跟踪算法,另外还用表格显示出了排名前15的跟踪算法的更加细节的比较(包括速度)
VOT-2016结果:作者在写这篇文章的时候,2016的官方结果还没出,作者自己测试的结果是SiamFc和SiamFc-3s的预测重叠率分别是0.3876和0.4051。
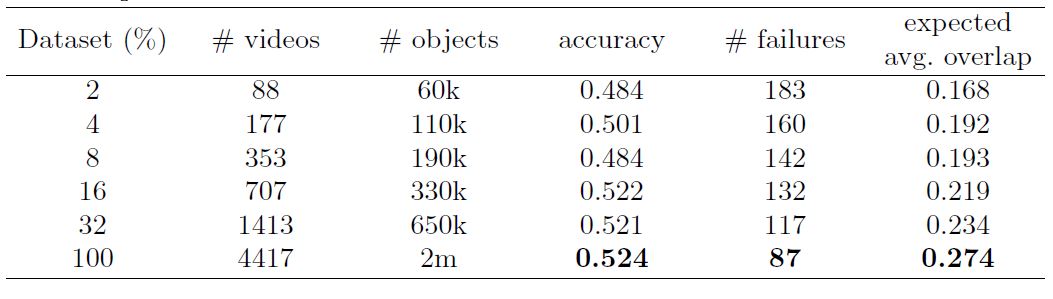
另外, 作者后面还通过不断改变数据集大小来观察测试效果的不同,发现数据集越大,效果越好。
四、相关链接##
原文链接:原文链接
代码链接:代码链接
算法相关链接:Xavier网络参数初始化
版权声明:本文为博主原创文章,未经博主允许不得转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号