当我的浏览器输入域名后,发生了什么?
我们以百度为例子,当我在浏览器的中输入网址www.baidu.com时,发生了什么?

1.域名解析
要知道,数据传输时所识别的数据链路层封装的帧,并不是通过字符串“www.baidu.com”传输的,而是通过对放的MAC地址找到对方的(硬件地址),那么要想获得MAC地址,自然也是通过IP地址并通过ARP协议转换而来的。
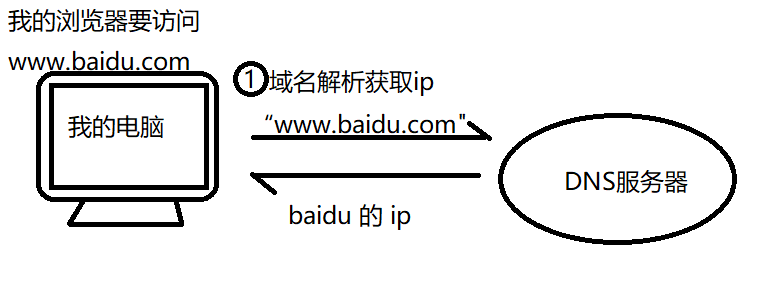
因为应用层只认识IP地址,所以当务之急,要想获取数据,必须先了解“www.baidu.com”域名所对应的IP地址。
想到了什么?DNS服务器——域名解析服务器。
但是我们要知道,我们的网络环境是错综复杂的,所以能自己自立根深解决的问题,尽量不要去麻烦别人,就好比你不确定高速路上堵不堵,你可以在家楼下买到香烟,何必大老远上高速去上海买呢?
a)浏览器会从主机的Hosts文件中查看是否有百度域名和IP地址的映射。
Hosts文件是一个用于存储计算机网络中节点信息的文件,它可以将主机名映射到相应的IP地址,实现DNS的功能,它可以由计算机的用户进行控制。
(PS:所以如果我们修改它,将www.baidu.com的对应IP改为127.0.0.1,看看会发生什么?)
b)如果Hosts文件没有,浏览器会查看自己的缓存。(由上面 PS 中的结果可以得出结论顺序为先 a) 再 b) 还是先 b) 再 a))。
c)当上面两个方法都行不通时,只能去请求DNS服务器来获取IP地址,这个过程用图片更好理解:
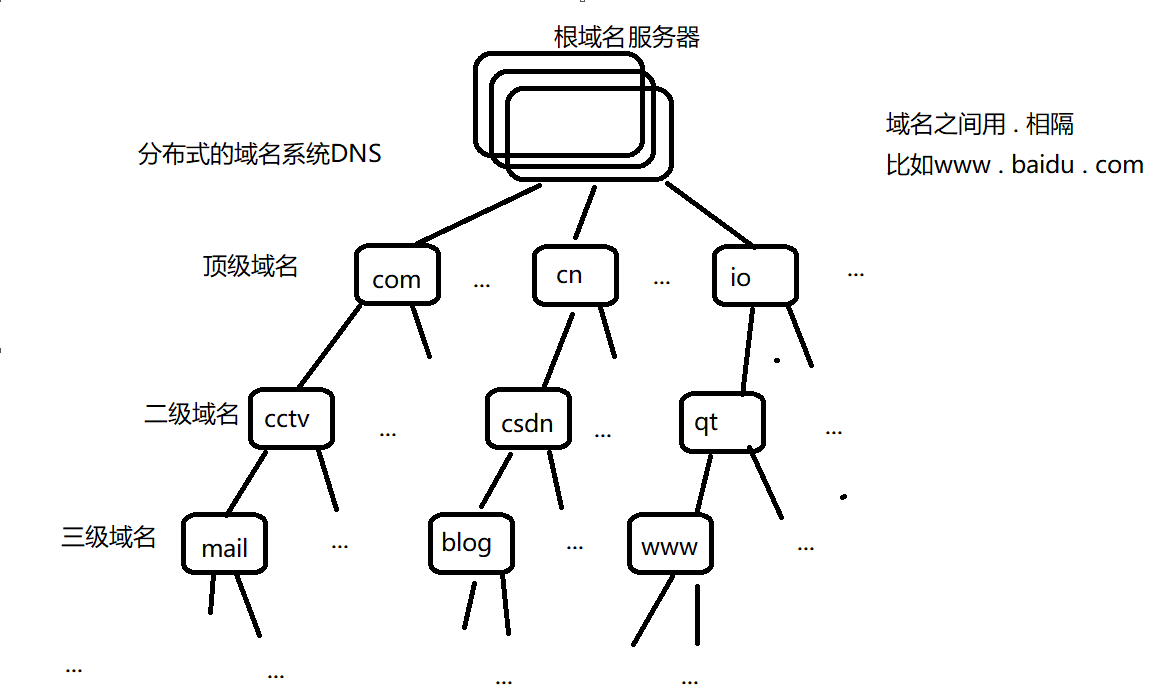
我们先来看一下分布式的域名系统DNS:
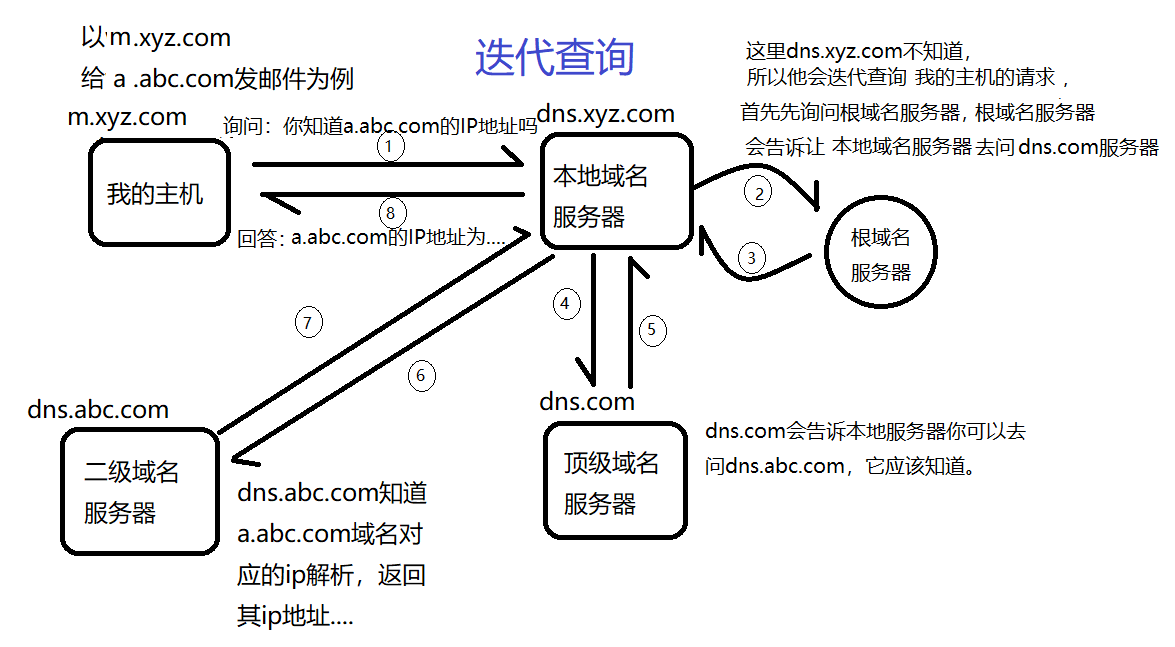
我们以m.xyz.com 向 a.abc.com发送邮件为例,我们m.xyz.com询问对方域名解析的方式分别是迭代查询和递归查询,如图所示:

2.发起连接,构造请求。
获取了对方的IP地址后,我们自然要发送相对的HTTP报文(当然因为百度是https://www.baidu.com/,所以在发送HTTP请求报文前要先发送一个HTTPS报文建立一个安全信道,并且确定网站的真实性。)
a)建立TCP连接,牢记三次握手的过程。
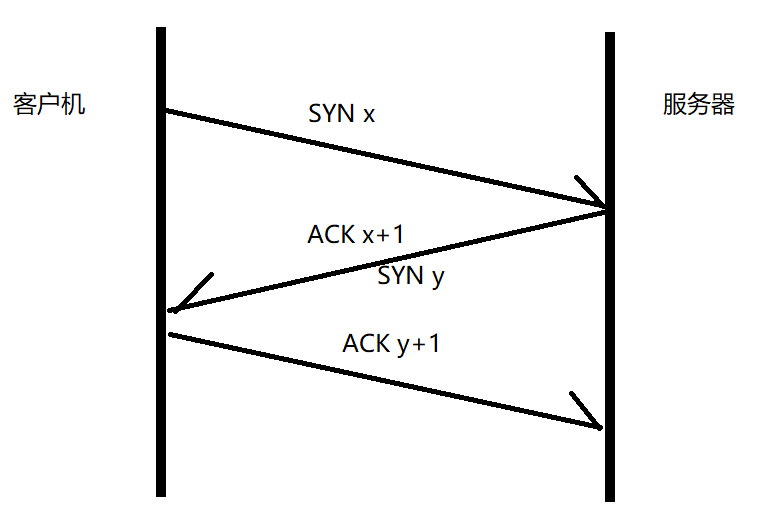
b)确认连接后发送一个HTTP请求报文。
在这里要清楚网络栈模型封装HTTP数据包的过程,先是写入HTTP报文的信息——首行、头部、空行、内容。再是在传输层打包,加上TCP首部,再来到IP层加上IP头部,通过ARP协议知道对方的MAC地址,到数据链路层打包封装成帧,通过路由转发,抵达目的MAC地址,再自下而上拆包,知道抵达对方服务器。之后对方服务器写一个响应报文再用同样的方式传回。
HTTP请求报文的格式:

需要注意的是,还有两个很常见的报文方法是 CONNECT 和 GET 。
CONNECT表示要求用隧道协议连接代理,连接https协议下的域名时经常可以抓到这个类型的包。
GET表示获取资源,与POST作用大致相同,最大的不同就是POST有body,而GET没有。
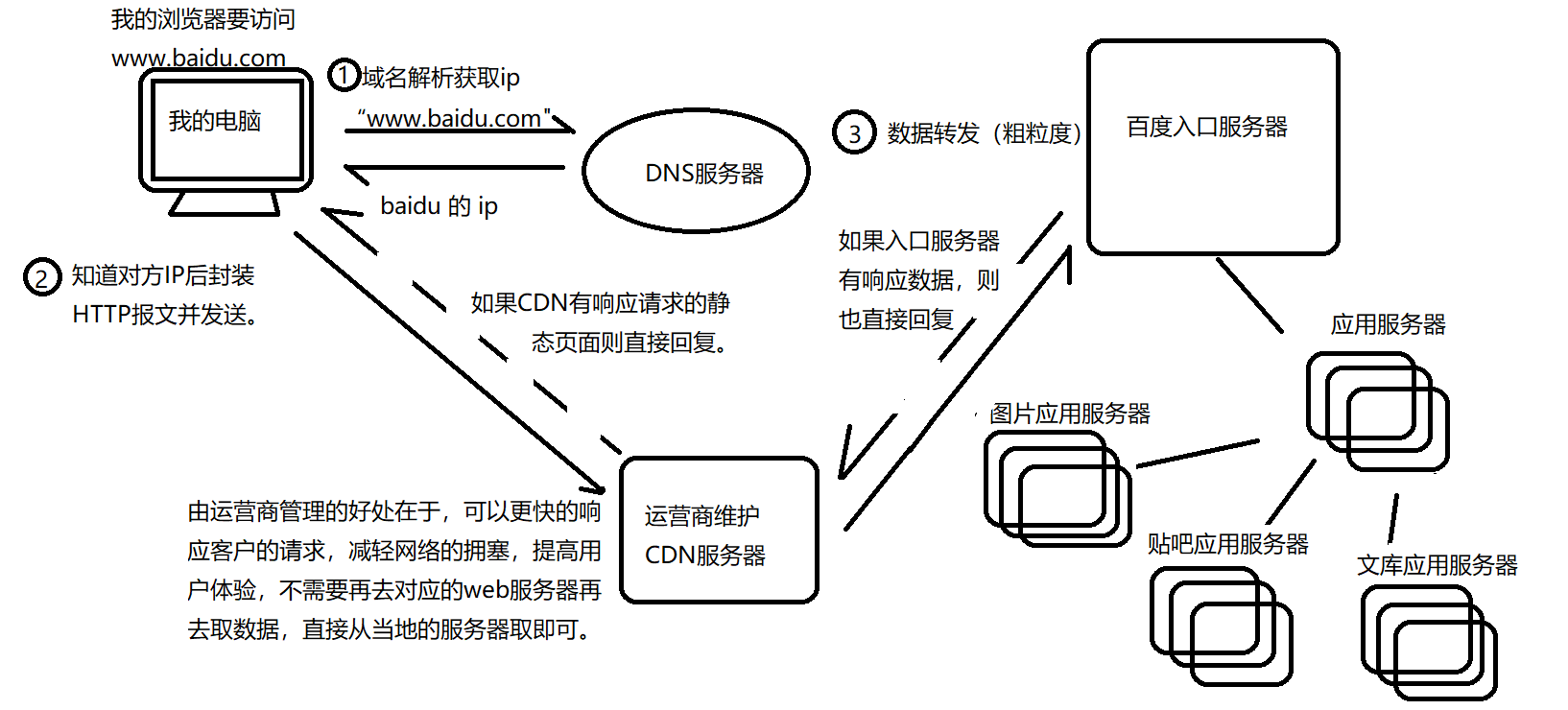
3.数据转发
我们在2中有提及过细粒度上的路由转发。那么在粗粒度上发生了什么?
a)请求抵达运营商维护的CDN服务器,看看是否有该请求对应响应的静态页面。
CDN的一大作用就是贮存一些在它所管理区域会频发用到的响应静态页面,这在很大程度上就很好的减轻了网络压力,用户不用直接去询问网站的总部服务器,可以更快得到响应,增加了用户体验的幸福感,还减轻了网络拥塞,两全其美。
b)如果CDN没有,则先询问百度入口服务器,如果入口服务器有对应请求响应的静态页面,那么可以作为一个反向代理回复请求报文。
入口服务器的作用也是为了提高用户体验的幸福感,入口服务器也会贮存一些常用的静态页面,这也不用再深入其他服务器取数据了。
c)如果入口服务器也没有,则要深入去相关的服务器取得数据。
就比如我要看图片,还有我登录了账号的信息,就会从图片服务器,用户管理服务器去取响应数据。
详情见图: