正则表达式学习整理
什么是正则表达式?
正则表达式是一种文本模式,包括普通字符(例如a到z之间的字母)和特殊符号(称为“元字符”)。
正则表达式使用单个字符串来描述、匹配一系列匹配某个语法规则的字符串。
正则表达式是繁琐的,但它是强大的,学会之后的应用会让你提高效率。
限定符
*:匹配的字符可以不出现,也可以出现一次或多次(大于等于0)
+:匹配的字符至少出现一次(大于等于1)
?:匹配的字符最多只可以出现一次(0或1)
{n}:代表匹配n次
{n,}:代表至少匹配n次,最多无限
{n,m}:代表至少匹配n次,最多匹配m次
定界符
^:匹配输入字符串的开始位置
$:匹配输入字符串的结束位置
\b:匹配一个单词边界,即单词与空格之间的位置(光标所在的位置)
\B:非单词边界匹配
修饰符(跟在定界符//的后面)
g:匹配出所有符合要求的结果,例:/\d+/g 匹配字符串中所有数字组合
i:忽略大小写配匹配,例:/[a-z]/gi 匹配所有字母忽略大小写
m:进行多行匹配,必须配合定位符^和$使用,例: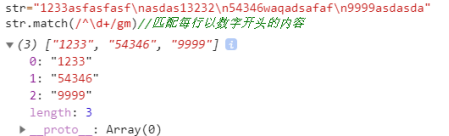
元字符
|
字符 |
描述 |
|
(pattern) |
匹配 pattern 并获取这一匹配。这是一个获取匹配。 |
|
(?:pattern) |
匹配 pattern 但不获取匹配结果,这是一个非获取匹配,不进行存储供以后使用,但是消耗字符匹配。 |
|
(?=pattern) |
正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,不需要获取供以后使用。 |
|
(?!pattern) |
正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,不需要获取供以后使用。 |
|
(?<=pattern) |
反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。 |
|
(?<!pattern) |
反向否定预查,与正向否定预查类似,只是方向相反。 |
|
x|y |
匹配 x 或 y。 |
|
[xyz] |
字符集合。匹配所包含的任意一个字符。 |
|
[^xyz] |
负值字符集合。匹配未包含的任意字符。 |
|
[a-z] |
字符范围。匹配指定范围内的任意字符。 |
|
[^a-z] |
负值字符范围。匹配任何不在指定范围内的任意字符。 |
|
\d |
匹配一个数字字符。等价于 [0-9]。 |
|
\D |
匹配一个非数字字符。等价于 [^0-9]。 |
|
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
|
\S |
匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
|
\f |
匹配一个换页符。等价于 \x0c 和 \cL。 |
|
\n |
匹配一个换行符。等价于 \x0a 和 \cJ。 |
|
\r |
匹配一个回车符。等价于 \x0d 和 \cM。 |
|
\t |
匹配一个制表符。等价于 \x09 和 \cI。 |
|
\v |
匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
|
\w |
匹配字母、数字、下划线。等价于'[A-Za-z0-9_]'。 |
|
\W |
匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'。 |
|
\cx |
匹配由 x 指明的控制字符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
相关注释:
1.
获取匹配和非获取匹配区别?
非获取匹配,pattern为预查字符(匹配成功后不获取匹配成功的内容,且继续匹配时从预查字符开始匹配):
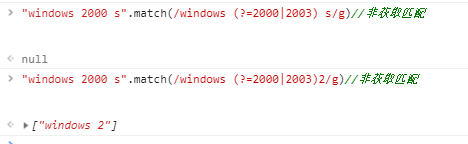
特殊点:(?:pattern)表达式,虽然也是非获取匹配但是他是一个消耗字符的匹配。
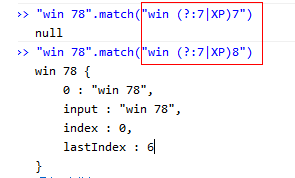
获取匹配:与非获取匹配相反,匹配成功急需匹配时,从预查字符之后开始匹配。
2.
\num具体用法?
有两种情况:
- num范围在1-99,表示匹配到第几个括号的重复字符。
具体用法只有:/(.)\1/ 用来匹配两个连续的字符。其他具体用法不明确 - num是0或者是三位数,表示8进制所对应的ASCII码字符

3.
\c的具体用法
\c匹配control+控制字符,就是说匹配由x指明的控制字符。
比如:\cj匹配control+j,代表\n。
\ca \cb \cc ... 又分别匹配 control+a, control+b,control+c....,具体他们等价于什么,看运行的程序了
百度搜索控制字符可以查看所有a-z的匹配
语法
- [0-9]+匹配多个数字,[0-9]匹配单个数字,+匹配一个或多个。
- {3,15}匹配长度介于3-15字符长度,{2}匹配确定的两次,{1,}至少匹配一次
例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。
例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 - ()标记一个表达式的开始和结束位置。
- .匹配换行符\n之外的任何单字符。
- \将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义字符。
- {}标记限定符表达式的开始和结束
- |指明两项之间的一个选择,一般配合()使用。
常用字符组
[\u4e00-\u9fa5] //匹配常用中文汉字(繁体字可能匹配不到)
[a-z] //匹配所有的小写字母
[A-Z] //匹配所有的大写字母
[a-zA-Z] //匹配所有的字母
[A-z] //匹配所有的字母
[0-9] //匹配所有的数字
[0-9\.\-] //匹配所有的数字,英文句号和减号
[ \f\r\t\n\v] //匹配所有的白字符(空格、换页符、回车符、水平制表符、垂直制表符)
[^a-z] //除了小写字母以外的所有字符
[^\\\/\^] //除了(\)(/)(^)之外的所有字符
[^\"\'] //除了双引号(")和单引号(')之外的所有字符
^[a-zA-Z0-9_]{1,}$ // 所有包含一个以上的字母、数字或下划线组成的字符串
^[1-9][0-9]{0,}$ // 所有的正整数
^\-{0,1}[0-9]{1,}$ // 所有的整数
/^[-]?(0{1}|[1-9][0-9]*)(\.[0-9]+)?$/ // 所有的浮点数
/^\w+@\w+\.\w+$/ //邮箱验证
实例
由于章节编号在大的输入文档中会很可能超过九,所以您需要一种方式来处理两位或三位章节编号。下面的正则表达式匹配编号为任何位数的章节标题
/Chapter [1-9][0-9]*/
含义:匹配Chapter 加上一个大于零的数字,[1-9]匹配1到9任何一个数字,[0-9]匹配0-9任何一个数字,*表示前面的表达式[0-9]匹配次数大于等于0。之所以不用+,是因为编号不一定需要两位数或者更多位数,之所以不用?,是因为它会让编号限制在两位数。
下面的正则表达式匹配一个章节标题,该标题只包含两个尾随数字,并且出现在行首:
/^Chapter [1-9][0-9]{0,1}/
真正的章节标题不仅出现行的开始处,而且它还是该行中仅有的文本。它即出现在行首又出现在同一行的结尾。下面的表达式能确保指定的匹配只匹配章节而不匹配交叉引用。通过创建只匹配一行文本的开始和结尾的正则表达式,就可做到这一点。
/^Chapter [1-9][0-9]{0,1}$/
简单表达式
/a/匹配字母a
/7/匹配数字7
/a.c/匹配以a开头,c结尾,中间除了\n以外的换行符。(.可以匹配字符串中打印或非打印字符,除了\n)
/index\.html/匹配index.html(.前面加反斜杠代表就是.)
请注意,没有串联运算符。只须在一个字符后面键入另一个字符。(通俗讲,两个子表达式或者匹配符之间不需要连接符)
中括号表达式
括在中括号表达式中的字符只匹配处于正则表达式中该位置的单个字符
/text [12345]/可以匹配到text 1、text 2、text 3、text 4、text 5。
也可以写成 /text [1-5]/ 但是开始值必须小于结束值
如果在中括号中使用连字符-,请用以下三种方法:
(1) [/-]反斜杠转义
(2) [-a-z]或[a-z-]将连字符放在中括号的开始或者结尾
(3) [!--]或[!-~]创建一个范围开始值小于连字符,结束值大于等于连字符
5.
/text [^1-5]/中括号内以^开头表示匹配除了中括号内以外的任何数字和字符
6.
替换和分组:
替换使用 | 字符来允许在两个或多个替换选项之间进行选择。
/^Chapter|Section [1-9][0-9]{0,1}$/
上面的正则表达式要么匹配行首的单词 Chapter,要么匹配行尾的单词 Section 及跟在其后的任何数字。
/^(Chapter|Section) [1-9][0-9]{0,1}$/
在上面的正则表达式的适当位置添加括号,就可以使该正则表达式匹配 Chapter 1 或 Section 3
7.
Js中的match()可以查找一个或多个正则表达式可以匹配的字符串,当正则为全局匹配时,返回所有匹配成功的值组成的数组。
当正则为非全局匹配时,返回第一个匹配成功的相关内 容。如果没有匹配到则返回null。


g可以控制是否查找多个


匹配连续的
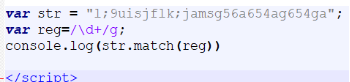

8.
Js中的test()可以验证字符串中有有没有符合要求的字符,如果字符串中有匹配的值返回 true ,否则返回 false。
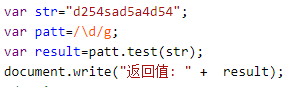 结果:
结果:
9.
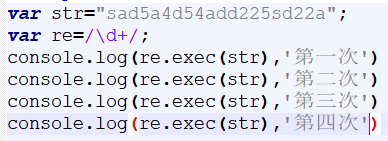
Js中的 exec()可以提取正则中符合要求的值,并且以数组的形式返回。
与match()方法有相似之处(主要是全局匹配时不同,match()会一次性返回所有符合的字符,exec()是一个个返回 )。
不全局匹配的话(不加g):返回一个数组:匹配到的字符、匹配到的字符位置、匹配的整个字符串本身:

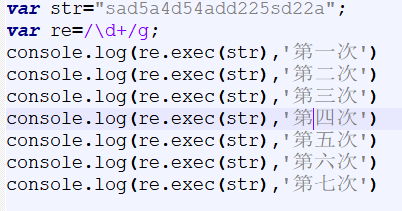
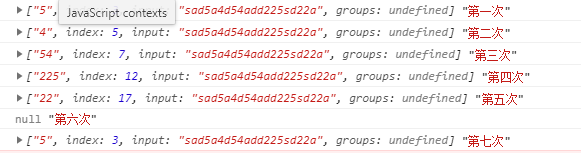
如果全局匹配(加g):
返回一个数组:
匹配到的字符(每次调用指针会向后移一个,匹配到最后一个符合的字符,再次调用会返回null,继续调用,就会从头开始匹配)、匹配到的字符位置、匹配的整个字符串本身
10.
search()与indexOf()方法类似,用来查找指定字符串在字符串中出现的位置。
返回的是第一个符合要求的结果在整个字符串中的位置
如果没有符合正则要求的结果,返回-1
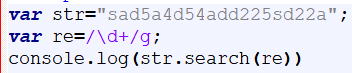
结果:3
11.
replace() 方法用于在字符串中用一些字符替换另一些字符,或替换一个与正则表达式匹配的子串。

结果:sad*a*d*add*sd*a
12.
php preg_replace()函数
函数执行一个正则表达式的搜索和替换语法:mixed preg_replace ( mixed $pattern , mixed $replacement , mixed $subject [, int $limit = -1 [, int &$count ]] )
$pattern:要搜索的模式,可以是字符串或一个字符串数组。(正则表达式)
$replacement:用于替换的字符串或字符串数组。
$subject:要搜索替换的目标字符或字符串数组。
$limit:可选,对于每个模式用于每个subject字符串的最大可替换次数。默认是-1(无限制)。
$count:可选,替换执行的次数
返回值:
如果subject是一个数组,preg_replace()返回一个数组,其他情况返回一个字符串。
如果匹配被查找到,替换后的 subject 被返回,其他情况下 返回没有改变的 subject。如果发生错误,返回 NULL。
<?php
$str = 'runo o b';
$str = preg_replace('/\s+/', '', $str); // 结果将会改变为'runoob'
?>
使用基于数组索引的搜索替换
<?php
$string = 'The quick brown fox jumped over the lazy dog.';
$patterns = array();
$patterns[0] = '/quick/';
$patterns[1] = '/brown/';
$patterns[2] = '/fox/';
$replacements = array();
$replacements[2] = 'bear';
$replacements[1] = 'black';
$replacements[0] = 'slow';
//虽然下标是倒叙,但数组的实际顺序还是210,所以quick对应bear,brown对应black,fox对 应slow
echo preg_replace($patterns, $replacements, $string);
?>
结果:The bear black slow jumped over the lazy dog.
使用其他参数:
<?php
$count = 0;
echo preg_replace(array('/\d/', '/\s/'), '*', 'xp 4 to', -1 , $count);
echo $count; //3
?>
结果: xp***to 3
如果此文章对您有所帮助记得打赏哦,一分也是对我的支持和鼓励,谢谢!
转载文章请务必保留出处和署名,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号