
最近在学习一些利用selenium 做爬虫的知识 这里面来总结一下函数的清单
1. wd = webdriver.Chrome(r'd:\webdrivers\chromedriver.exe') 这里面是启动chrome控制器
2. wd.get('https://www.baidu.com') 里面放网址,chrome可以转到百度这个网站
3. element = wd.find_element_by_id('kw') 利用id号码去找到内容,返回一个element的对象
4. # 通过该 WebElement对象,就可以对页面元素进行操作了 # 比如输入字符串到 这个 输入框里 element.send_keys('白月黑羽\n')
5. wd.find_elements_by_class_name('animal') 可以返回一个列表这个列表里面有所有关于animal的类
from selenium import webdriver # 创建 WebDriver 实例对象,指明使用chrome浏览器驱动 wd = webdriver.Chrome(r'd:\webdrivers\chromedriver.exe') # WebDriver 实例对象的get方法 可以让浏览器打开指定网址 wd.get('http://cdn1.python3.vip/files/selenium/sample1.html') # 根据 class name 选择元素,返回的是 一个列表 # 里面 都是class 属性值为 animal的元素对应的 WebElement对象 elements = wd.find_elements_by_class_name('animal') # 取出列表中的每个 WebElement对象,打印出其text属性的值 # text属性就是该 WebElement对象对应的元素在网页中的文本内容 for element in elements: print(element.text)
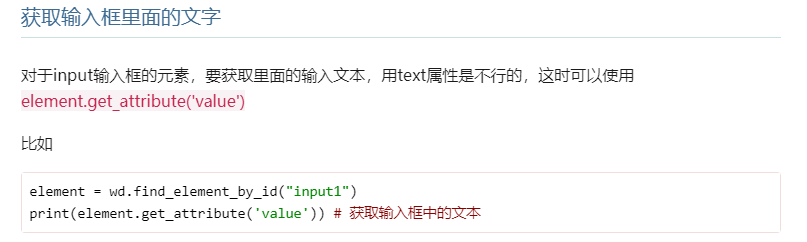
6. element = wd.find_element_by_id("input1") 根据id查找内容
7. element.get_attribute('class') 从class类里面得到元素的属性
8.wd.quit() 关闭浏览器
9.
10. find_element_by_css_selector(CSS Selector参数) 选取单个内容
11 .find_elements_by_css_selector(CSS Selector参数)选取所有的内容
12. element = wd.find_element_by_css_selector('#searchtext') 根据ID的值选取内容
13.elements = wd.find_elements_by_css_selector('.animal') 根据animal类选取内容
14.element = wd.find_element_by_css_selector('[href="http://www.miitbeian.gov.cn"]') 根据里面的链接选择
15.span:nth-child(2) span 类型,所有第二个子节点
16. 父节点倒数第几个元素 :nth-last-child(1)
17.
上面的例子里面,我们要选择 唐诗 和宋词 的第一个 作者
还有一种思考方法,就是选择 h3 后面紧跟着的兄弟节点 span。
这就是一种 相邻兄弟 关系,可以这样写 h3 + span
表示元素 紧跟关系的 是 加号
18 如果要选择是 选择 h3 后面所有的兄弟节点 span,可以这样写 h3 ~ span
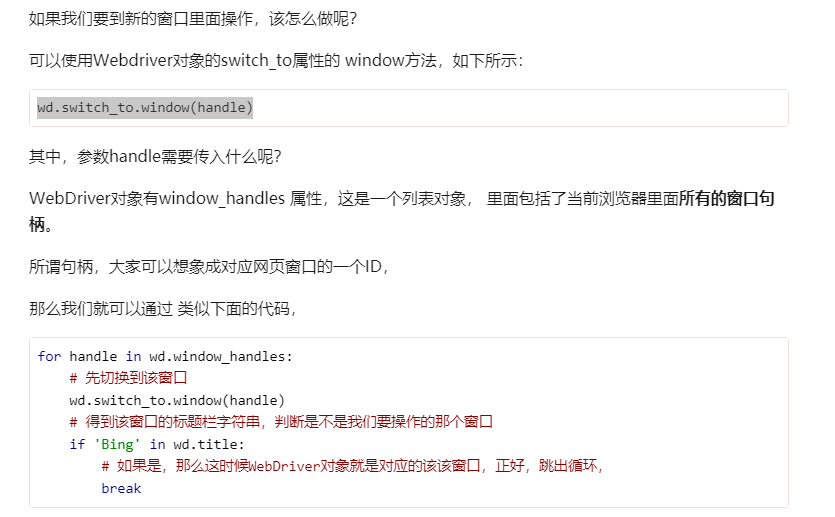
19. wd.switch_to.frame(frame_reference) 切换到其他的frame frame_reference可以是frame的名字或者是ID号码
20. wd.switch_to.default_content() 返回外部的frame
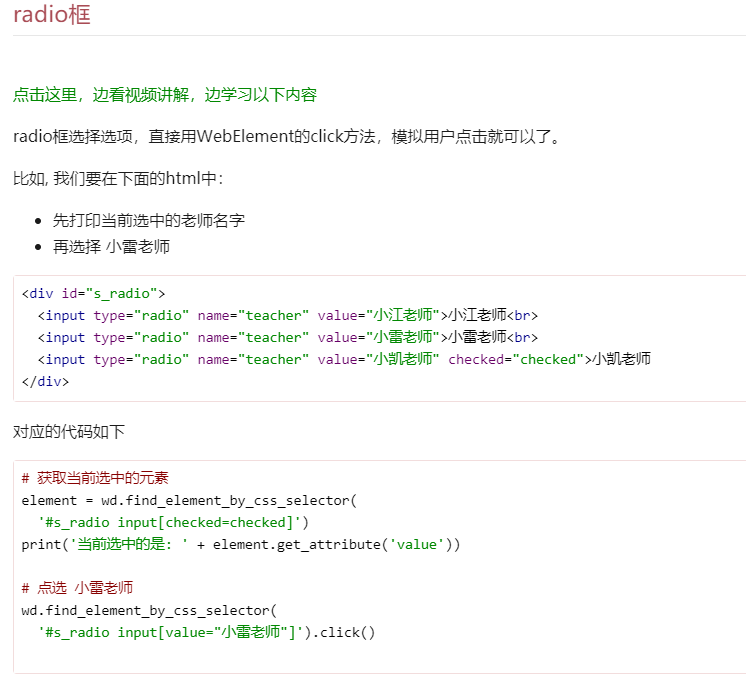
radio 窗:
checkbox

冻结窗口:
xPath 今天没心情 下次再说
