


_T、_TEXT、TEXT、L的使用记录
宽字符与多字节字符
在windows系统中,Windows NT的所有与字符有关的函数都提供两种方式的版本,而Windows 9x只支持ANSI方式。
Windows NT提供的两种方式分别是:Unicode字符集和多字节字符集。
一般我们会选择Unicode字符集,因为这样很方便我们开发,值得一提的是,Unicode字符集也许我们很熟悉,平时所说的宽字节就是Unicode,多字节就是指的ANSI,GB等。
宽字符和多字节字符的说明如下:(引用自网络)
宽字符,wide character,该字符集内每个字符使用相同的位长;
多字节字符,multibyte character,每个字符可以是一到多个字节不等,而某个字节序列的字符值由字符串或流(stream)所在的环境背景决定。
在VS->属性->配置属性->高级->字符集选项中,我们也看到了这两种字符集。一般项目默认选择的是Unicode宽字符集。
当选择Unicode宽字符集时,我们可以看到实际的预处理器定义信息如下:(C/C++->所有选项->预处理器定义)
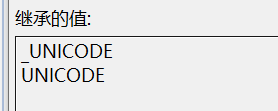
当改为多字节字符集,信息如下:

ANSI多字节编码与UNICODE宽字符编码区别
ANSI中的字符采用8bit,而UNICODE中的字符采用16bit。(对于字符来说ANSI以单字节存放英文字符,以双字节存放中文等字符,而Unicode下,英文和中文的字符都以双字节存放)Unicode码也是一种国际标准编码,采用二个字节编码,与ANSI码不兼容。
目前,在网络、Windows系统和很多大型软件中得到应用。8bit的ANSI编码只能表示256种字符,表示26个英文字母是绰绰有余的,但是表示汉字,韩国语等有着成千上万个字符的非西方字符肯定就不够了,正是如此才引入了UNICODE标准。
MS相关宏定义
L:用来告诉编译器该字符串一律作为Unicode来编译。它用来将ASNI转换为Unicode。
_T():一个宏。其根据编译器实际选择的字符集(宏定义)来进行灵活选择。如果项目使用了Unicode字符集(定义了UNICODE宏),则自动在字符串前面加上L,表示该字符(串)以宽字符表示。如果项目使用了ANSI多字节,则字符(串)就是其本身,用_T来保证兼容性。VC支持ascii和unicode两种字符类型,用_T可以保证从ascii编码类型转换到unicode编码类型的时候,程序不需要修改。
_TEXT():其与_T功能一样。
TEXT():需要在#include<WinNT.h>前加上#include <Windows.h>才能使用TEXT,TEXT是根据UNICODE来确定宏的。当编译环境使用Unicode字符集时,预编译宏包含了_UNICODE和UNICODE(上图中可以看到),所以_T(),_TEXT(),TEXT()三者在Unicode字符集功能是一样的。
具体的MS中宏定义信息如下:
T() ,_TEXT () 定义于tchar.h,在Windows.h下
//tchar.h #define _T(x) __T(x) #define _TEXT(x) __T(x) #ifdef _UNICODE #define __T(x) L ## x //第210行 #else #define __T(x) x //第858行 #endif
TEXT () : 在WinNT.h下
#define TEXT(quote) __TEXT(quote) #ifdef UNICODE #define __TEXT(quote) L##quote #else /* UNICODE */ #define __TEXT(quote) quote #endif /* UNICODE */
LPCTSTR,LPWSTR, PTSTR, LPTSTR,wchar_t区别
参考:https://blog.csdn.net/qq_22642239/article/details/84822485。
总结:
L:用来告诉编译器该字符串一律作为Unicode来编译。它用来将ASNI转换为Unicode。
_T、_TEXT、TEXT 三者功能一样。如果项目使用了Unicode字符集(定义了UNICODE宏),则自动在字符串前面加上L,表示该字符(串)以宽字符表示。如果项目使用了ANSI多字节,则字符(串)就是其本身,用_T来保证兼容性。
tchar.h是运行时的头文件,_T、_TEXT 根据_UNICODE来确定宏
winnt.h是Win的头文件根据,TEXT 根据UNICODE 来确定宏
_UNICODE宏用于C运行期头文件,UNICODE宏则用于Windows头文件.当编译源代码模块时,通常必须同时定义这两个宏。

