SparkStreaming基础案例
WordCount案例
案例一:
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc,Seconds(5));
val lines = ssc.textFileStream("file:///home/software/stream");
//val lines = ssc.textFileStream("hdfs://hadoop01:9000/wordcount");
val words = lines.flatMap(_.split(" "));
val wordCounts = words.map((_,1)).reduceByKey(_+_);
wordCounts.print();
ssc.start();
基本概念
1. StreamingContext
StreamingContext是Spark Streaming编程的最基本环境对象,就像Spark编程中的SparkContext一样。StreamingContext提供最基本的功能入口,包括从各途径创建最基本的对象DStream(就像Spark编程中的RDD)。
创建StreamingContext的方法很简单,生成一个SparkConf实例,设置程序名,指定运行周期(示例中是5秒),这样就可以了:
val conf = new SparkConf().setAppName("SparkStreamingWordCount")
val sc=new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(5))
运行周期为5秒,表示流式计算每间隔5秒执行一次。这个时间的设置需要综合考虑程序的延时需求和集群的工作负
载,应该大于每次的运行时间。
StreamingContext还可以从一个现存的org.apache.spark.SparkContext创建而来,并保持关联,比如上面示例中的创建方法:
val ssc = new StreamingContext(sc, Seconds(5))
StreamingContext创建好之后,还需要下面这几步来实现一个完整的Spark流式计算:
(1)创建一个输入DStream,用于接收数据;
(2)使用作用于DStream上的Transformation和Output操作来定义流式计算(Spark程序是使用Transformation和Action操作);
(3)启动计算,使用streamingContext.start();
(4)等待计算结束(人为或错误),使用streamingContext.awaitTermination();
(5)也可以手工结束计算,使用streamingContext.stop()。
2. DStream抽象
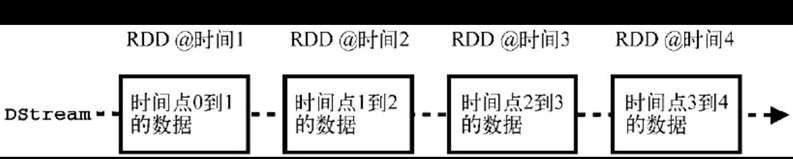
DStream(discretized stream)是Spark Streaming的核心抽象,类似于RDD在Spark编程中的地位。DStream表示连续的数据流,要么是从数据源接收到的输入数据流,要求是经过计算产生的新数据流。DStream的内部是一个RDD序列,每个RDD对应一个计算周期。比如,在上面的WordCount示例中,每5秒一个周期,那么每5秒的数据都分别对应一个RDD,如图所示,图中的时间点1、2、3、4代表连续的时间周期。
所有应用在DStream上的操作,都会被映射为对DStream内部的RDD上的操作,比如上面的WordCount示例中对lines DStream的flatMap操作,如下图
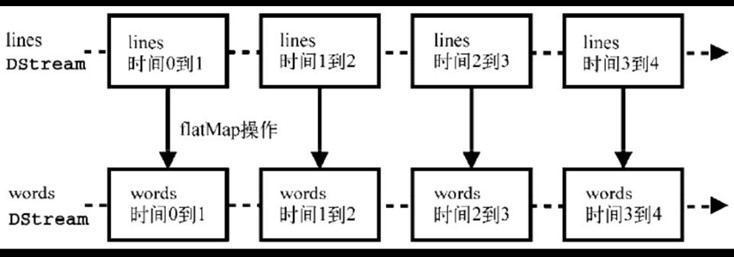
RDD操作将由Spark核心来调度执行,但DStream屏蔽了这些细节,给开发者更简洁的编程体验。当然,我们也可以直接对DStream内部的RDD进行操作(后面会讲到)。
案例二:
经过测试,案例一代码确实可以监控指定的文件夹处理其中产生的新的文件
但数据在每个新的周期到来后,都会重新进行计算
而如果需要对历史数据进行累计处理 该怎么做呢?
SparkStreaming提供了checkPoint机制,首先需要设置一个检查点目录,在这个目录,存储了历史周期数据。通过在临时文件中存储中间数据 为历史数据累计处理提供了可能性
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc,Seconds(5));
ssc.checkpoint("file:///home/software/chk");
val lines = ssc.textFileStream("file:///home/software/stream");
val result= lines.flatMap(_.split(" ")).map((_,1)).updateStateByKey{(seq, op:Option[Int]) =>
{ Some(seq.sum +op.getOrElse(0)) }}
result.print();
ssc.start();
updateStateByKey 方法说明:
1.seq:是一个序列,存的是某个key的历史数据
2.op:是一个值,是某个key当前的值
比如: (hello,1)
①seq里是空的,Some(1)=>Some(返回的是历史值的和+当前值)
②(hello,2),seq(1) op=2 Some(1+2)
③(hello,1) , seq(1,2) op=1 Some(3+1)
案例三:
但是这上面的例子里所有的数据不停的累计 一直累计下去
很多的时候我们要的也不是这样的效果 我们希望能够每隔一段时间重新统计下一段时间的数据,并且能够对设置的批时间进行更细粒度的控制,这样的功能可以通过滑动窗口的方式来实现。
在DStream中提供了如下的和滑动窗口相关的方法:
window(windowLength, slideInterval)
windowLength:窗口长度
slideInterval:滑动区间

countByWindow(windowLength, slideInterval)
reduceByWindow(func, windowLength, slideInterval)
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
countByValueAndWindow(windowLength, slideInterval, [numTasks])
可以通过以上机制改造案例
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc,Seconds(1));
ssc.checkpoint("file:///home/software/chk");
val lines = ssc.textFileStream("file:///home/software/stream");
val result = lines.flatMap(_.split(" ")).map((_,1)).reduceByKeyAndWindow((x:Int,y:Int)=>x+y, Seconds(5), Seconds(5) ).print()
ssc.start();
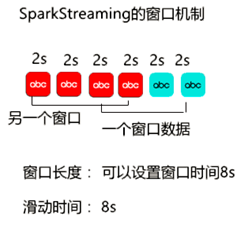
注意:窗口长度和滑动长度必须是batch size的整数倍
此外,使用窗口机制,必须要设定检查点目录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号