
Spark架构
概述
为了更好地理解调度,我们先来鸟瞰一下集群模式下的Spark程序运行架构图。
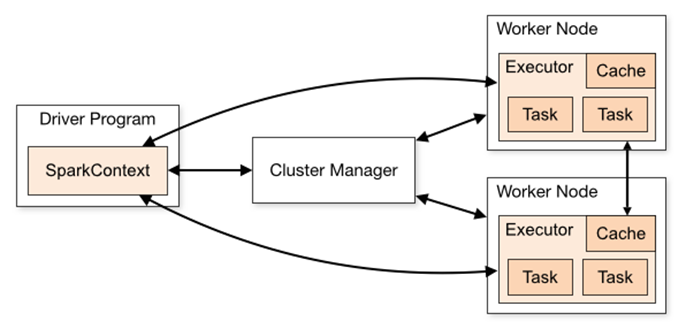
1. Driver Program
用户编写的Spark程序称为Driver Program。每个Driver程序包含一个代表集群环境的SparkContext对象,程序的执行从Driver程序开始,所有操作执行结束后回到Driver程序中,在Driver程序中结束。如果你是用spark shell,那么当你启动 Spark shell的时候,系统后台自启了一个 Spark 驱动器程序,就是在Spark shell 中预加载的一个叫作 sc 的 SparkContext 对象。如果驱动器程序终止,那么Spark 应用也就结束了。
2. SparkContext对象
每个Driver Program里都有一个SparkContext对象,职责如下:
1)SparkContext对象联系 cluster manager(集群管理器),让 cluster manager 为Worker Node分配CPU、内存等资源。此外, cluster manager会在 Worker Node 上启动一个执行器(专属于本驱动程序)。
2)和Executor进程交互,负责任务的调度分配。
3. cluster manager 集群管理器
它对应的是Master进程。集群管理器负责集群的资源调度,比如为Worker Node分配CPU、内存等资源。并实时监控Worker的资源使用情况。一个Worker Node默认情况下分配一个Executor(进程)。
从图中可以看到sc和Executor之间画了一根线条,这表明:程序运行时,sc是直接与Executor进行交互的。
所以,cluster manager 只是负责资源的管理调度,而任务的分配和结果处理它不管。
4.Worker Node
Worker节点。集群上的计算节点,对应一台物理机器
5.Worker进程
它对应Worder进程,用于和Master进程交互,向Master注册和汇报自身节点的资源使用情况,并管理和启动Executor进程
6.Executor
负责运行Task计算任务,并将计算结果回传到Driver中。
7.Task
在执行器上执行的最小单元。比如RDD Transformation操作时对RDD内每个分区的计算都会对应一个Task。

