
点集配准技术(ICP、RPM、KC、CPD)
在计算机视觉和模式识别中,点集配准技术是查找将两个点集对齐的空间变换过程。寻找这种变换的目的主要包括:1、将多个数据集合并为一个全局统一的模型;2、将未知的数据集映射到已知的数据集上以识别其特征或估计其姿态。点集的获取可以是来自于3D扫描仪或测距仪的原始数据,在图像处理和图像配准中,点集也可以是通过从图像中提取获得的一组特征(例如角点检测)。
点集配准研究的问题可以概括如下:假设{M,S}是空间Rd中的两个点集,我们要寻找一种变换T,或者说是一种从Rd 空间到Rd 空间的映射,将其作用于点集M后,可以使得变换后的点集M和点集S之间的差异最小。将变换后的点集M记为T(M),那么转换后的点集T(M)与点集S的差异可以由某种距离函数来定义,一种最简单的方法是对配对点集取欧式距离的平方:

点集配准方法一般分为刚性配准和非刚性配准。
刚性配准:给定两个点集,刚性配准产生一个刚性变换,该变换将一个点集映射到另一个点集。刚性变换定义为不改变任何两点之间距离的变换,一般这种转换只包括平移和旋转。
非刚性配准:给定两个点集,非刚性配准产生一个非刚性变换,该变换将一个点集映射到另一个点集。非刚性变换包括仿射变换,例如缩放和剪切等,也可以涉及其他非线性变换。
下面我们来具体介绍几种点集配准技术。
一. Iterative closest point(ICP)
ICP算法是一种迭代方式的刚性配准算法,它为点集M中每个点mi寻找在点集S中的最近点sj,然后利用最小二乘方式得到变换T,算法伪代码如下:

ICP算法对于待配对点集的初始位置比较敏感,当点集M的初始位置与点集S比较接近时,配准效果会比较好。另外ICP算法在每次计算迭代过程中都会改变最近点对,所以其实很难证明ICP算法能准确收敛到局部最优值,但是由于ICP算法直观易懂且易于实现,因此它目前仍然是最常用的点集配准算法。
在计算变换T时可以使用SVD方式,过程如下:
优化目标:
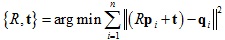
1.将点集去中心化:
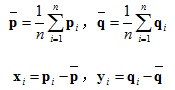
2.计算协方差矩阵并SVD分解:

3.计算旋转矩阵和平移向量:
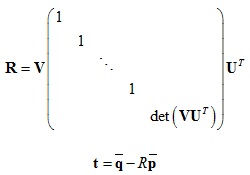
二. Robust point matching(RPM)
RPM算法是一种使用退火和软对应方式的配准算法。ICP算法在迭代计算时利用距离最近原则来产生待配准点对,而RPM算法利用软对应方式为任意点对赋予0到1之间的值,并最终收敛到0或1,如果是1则代表这两个点是配准点对。RPM算法最终计算得到的配准点对是一一映射的,而ICP算法通常不是。
RPM算法定义配准的损失函数如下:

其中:
t是平移向量。
A是变换矩阵,如果是2D情况,矩阵A可以分解成4个变量{a,θ,b,c},分别代表缩放系数,旋转角度,垂直和水平剪切量。
g(A)代表变换矩阵的正则项,其作用是防止变换矩阵中出现较大值。
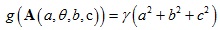
μ是配准矩阵,定义如下:

α项作用是是配准矩阵中有更多的配准点对数量
算法伪代码如下:

三. Kernel correlation(KC)
KC算法是一种相似性测量方法,它将点集配准问题转化为寻找待配准点集之间最大相关性的过程。对于两个点xi和xj,它们之间的核相关性(kernel correlation)定义为:
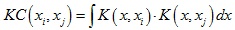
其中K(x, xi)是中心位置为xi的核函数,核函数通常为非负对称函数,常用的核函数有高斯核函数等。
高斯核函数形式如下:
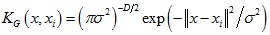
由高斯核函数可以得到的核相关性如下:
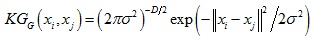
可以看到核相关性是与距离||xi - xj||相关的函数,值得注意的是,由其他核函数得到的核相关性也是距离||xi - xj||的函数。
KC算法定义点集配准的损失函数如下:
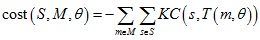
定义核密度估计(kernel density estimates):

损失函数可以表示为两个核密度估计之间的相关性:
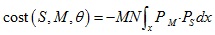
四. Coherent point drift(CPD)
CPD算法将点集配准问题转换为概率密度估计问题,其将点集M的分布表示成混合高斯模型,当点集M与点集S完成配准后,对应的似然函数达到最大。
将点集M中每个点mi作为混合高斯模型中每个成分的中心,并且假设每个成分概率相等,那么其分布模型可以表示为:
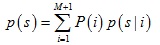
其中:

考虑噪声的影响,在分布模型中又加入了均匀分布函数,其权重为w,这样上式分布模型可以进一步表示为:

混合高斯模型的中心在配准过程中与变换参数θ相关,为了求得模型参数,需要极小化负对数似然函数:
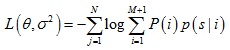
求解θ和σ2过程可以使用期望最大算法,算法包含两步:
E-Step:通过旧的分布模型参数计算后验概率分布Pold(i|sj)
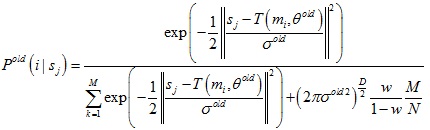
M-Step:极小化损失函数来得到新的模型参数θ和σ2
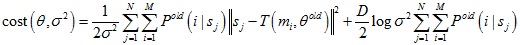
算法伪代码如下:

在M-step中,对于刚性变换和非刚性变换,变换模型参数求解分别如下:


无异常点无噪声情况

有异常点无噪声情况

无异常点有噪声情况

有异常点有噪声情况
本文为原创,转载请注明出处:http://www.cnblogs.com/shushen。
参考文献:
[1] https://en.wikipedia.org/wiki/Point_set_registration
[2] https://igl.ethz.ch/projects/ARAP/svd_rot.pdf
[3] Gold S, Rangarajan A, Lu C, et al. New algorithms for 2D and 3D point matching : Pose estimation and correspondence. Pattern Recognition, 1998, 31(8): 1019-1031.
[4] Chui H, Rangarajan A. A new point matching algorithm for non-rigid registration. Computer Vision and Image Understanding, 2003, 89(2): 114-141.
[5] Tsin Y, Kanade T. A Correlation-Based Approach to Robust Point Set Registration. european conference on computer vision, 2004: 558-569
[6] Myronenko A, Song X B. Point Set Registration: Coherent Point Drift. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(12): 2262-2275.
附录
薄板样条(Thin Plate Spline)
薄板样条可以表示成径向基函数的形式,给定一系列控制点{ci, i = 1, ..., n},径向基函数定义了空间中从位置x到f(x)之间的映射关系:

薄板样条对应的径向基函数核为σ(r) = r2logr。
对于非刚性变换,如果使用薄板样条来表示,那么径向基函数的自变量和应变量可以分别认为是变换前的点坐标x和变换后的点坐标y。
下面具体介绍如何使用薄板样条表示非刚性变换。
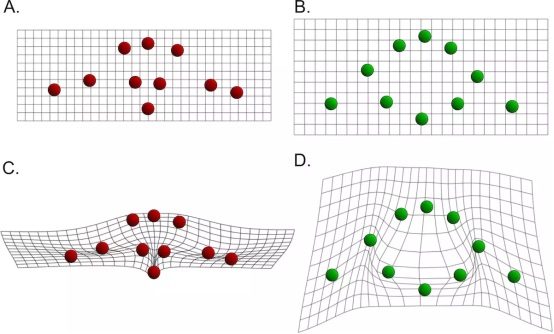
假设自变量是2维空间中的一系列点集x(A图所示),应变量也是2维空间中的一系列点集y(B图所示),我们对应变量的每个维度进行薄板样条插值,插值函数形式如下:
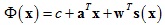
其中:c是标量,a ∈ R2×1,w ∈ Rn×1,s(x)表达式式如下:

插值函数表达式中c + aTx代表仿射变换,wTs(x)代表非仿射变换。
对于变换后每个点的第一个维度,我们可以建立一个约束条件:
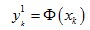
然后额外添加如下约束条件:
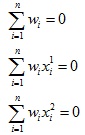
最终根据以上约束条件就可以求得薄板样条插值函数的参数了。
期望最大算法(Expectation Maximization)
期望最大算法是解决含隐变量模型参数的一种方法。给定数据样本X = {x(1), ... , x(n)},每个观察样本x(i)还对应着一个隐变量z(i)。假设样本为独立同分布,为了拟合模型p(x; θ)参数,我们需要极大化对数似然估计函数:
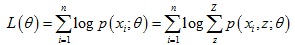
对于每个样本x(i),我们引入隐变量z的某种分布Qi(z),那么上式可以进一步变化:

上式最后一步利用了Jensen 不等式。
于是我们得到似然函数L(θ)的下界函数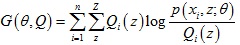 ,那么我们可以不断最大化下界函数G(θ, Q)来使得L(θ)不断提高,算法过程如下:
,那么我们可以不断最大化下界函数G(θ, Q)来使得L(θ)不断提高,算法过程如下:
1.(E-Step)固定θ,调整Q(z),使得似然函数L(θ)与下界函数G(θ, Q)在θ处相等
2.(M-Step)固定Q(z),调整θ,使得下界函数G(θ, Q)达到最大值。
3.迭代上述步骤,直至收敛到局部最优解。
对于第1步,只有当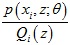 为常数时等号成立,又由于
为常数时等号成立,又由于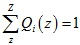 ,所以得到了Q(z)的表达式:
,所以得到了Q(z)的表达式:
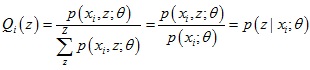
对于第2步,下界函数G(θ, Q)可以继续推导,得到一个更简单的表达形式:
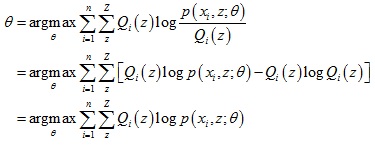
下面具体介绍以期望最大算法来求解混合高斯模型的参数。
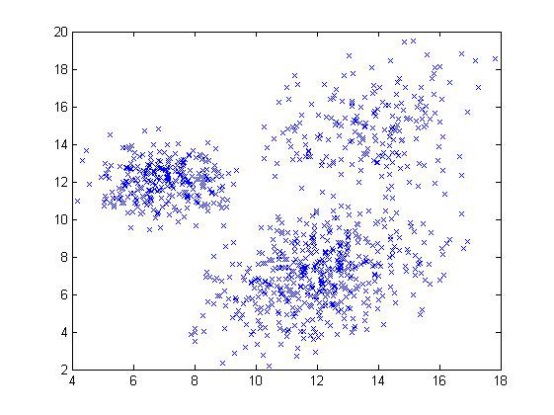
如上图所示,给定一系列二维数据点x,假设这些数据是由3个正态分布函数随机取样得到,这些正态分布函数线性组合在一起就组成了混合高斯模型的概率密度函数:
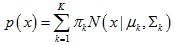
那么得到对数似然估计函数如下:
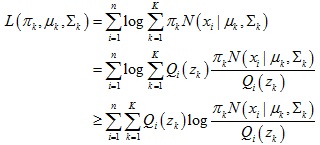
我们为每个数据点xi引入一个隐变量 z,这个隐变量代表这个数据点xi是由混合高斯模型中的哪个正态分布函数生成得到。
根据前面期望最大算法步骤:
1.计算隐变量的分布Qi(zk)
Qi(zk)它代表了数据点xi是由第k个正态分布函数生成的概率:
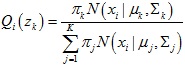
2.计算混合高斯模型参数πk,μk,Σk
下界函数进一步推导:
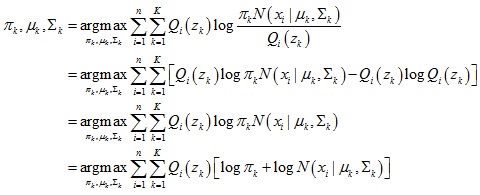
于是可以求出模型参数:
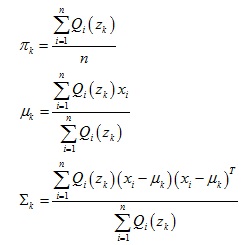



 浙公网安备 33010602011771号
浙公网安备 33010602011771号