[阅读笔记] 《深入理解计算机系统》程序的机器级表示
程序的机器级表示
时隔一年把 CS:APP 再看一遍,尤其针对栈的运行机制加深理解。
访问信息
16个通用寄存器
一个 x86-64 CPU 包含一组16个存储64位值的通用目的寄存器。虽然是通用寄存器,但也有一些约定成俗的用法。r8 r9 ... 为80386之后扩展的8个寄存器
- rax, 返回值
- rbx, 被调用者保存
- rcx, 第4个参数
- rdx, 第3个参数
- rsi, 第2个参数
- rdi, 第1个参数
- rbp, 被调用者保存
- rsp, 栈指针。最为特殊, 用来指明栈的结束位置(栈顶)
- r8, 第5个参数
- r9, 第6个参数
- r10, 调用者保存
- r11, 调用者保存
- r12, 被调用者保存
- r13, 被调用者保存
- r14, 被调用者保存
- r15, 被调用者保存
操作数指令符
大多数指令有一个或多个操作数(operand)指示出执行一个操作中要使用的源操作数,以及放置结果的目的操作数。根据源数据和目的位置的取值可分为三种类型
- 立即数(
immediate), 用来表示常数值 - 寄存器(
register), 表示某个寄存器的内容 - 内存引用, 根据计算出来的地址访问某个内存位置
多种寻址模式
- 在 ATT 格式的汇编代码中,立即数的写法为 $ 后跟一个标准 C 表示法的整数
- 用符号 ra 来表示任意寄存器 a, 用引用 R[ra] 来表示它的值, 这里将寄存器集合看成一个数组,用寄存器标识符作为索引
- 将内存看作一个很大的字节数组,用符号 Mb[Addr] 表示对存储在内存中可以地址 Addr 开始的 b 个字节值的引用, 下表省略下标 b
| 类型 | 格式 | 操作数值 | 名称 |
|---|---|---|---|
| 立即数 | $$Imm $ | Imm | 立即数寻址 |
| 寄存器 | ra | R[ra] | 寄存器寻址 |
| 存储器 | Imm | M[Imm] | 绝对寻址 |
| 存储器 | (ra) | M[R[ra]] | 间接寻址 |
| 存储器 | Imm(rb) | M[Imm+R[ra]] | (基址 + 偏移值)寻址 |
| 存储器 | (rb,ri) | M[R[rb]+R[ri]] | 变址寻址 |
| 存储器 | Imm(rb,ri) | M[Imm+R[rb]+R[ri]] | 变址寻址 |
| 存储器 | (,ri,s) | M[R[ri]⋅s] | 比例变址寻址 |
| 存储器 | Imm(,ri,s) | M[Imm+R[ri]⋅s] | 比例变址寻址 |
| 存储器 | (rb,ri,s) | M[R[rb]+R[ri]⋅s] | 比例变址寻址 |
| 存储器 | Imm(rb,ri,s) | M[Imm+R[rb]+R[ri]⋅s] | 比例变址寻址 |
数据传输指令
| 指令 | 效果 | 描述 |
|---|---|---|
| MOVS,D | D←S | 传送 |
| movabsqI,R | R←I | 传送绝对的四字 |
| MOVZS,R | R←零扩展(S) | 以零进行扩展进行转送 |
| MOVSS,R | R←符号扩展(S) | 转送符号扩展的字节 |
| movsbwS,R | 将符号扩展的字节传送到字 | |
| ctlq | %rax←符号扩展(%eax) | 把 %eax 符号扩展到 %rax |
算术和逻辑操作指令
| 指令 | 效果 | 描述 |
|---|---|---|
| leaqS,D | D←&S | 加载有效地址 |
| INCD | D←D+1 | 加 1 |
| DECD | D←D−1 | 减 1 |
| NEGD | D←−D | 取负 |
| NOTD | D←∼D | 取反 |
| ADDS,D | D←D+S | 加 |
| SUBS,D | D←D−S | 减 |
| IMULS,D | D←D∗S | 乘 |
| XORS,D | D←D ^ S | 异或 |
| ORS,D | D←D∣S | 或 |
| ANDS,D | D←D&S | 与 |
| SALk,D | D←D<<k | 左移 |
| SHLk,D | D←D<<k | 左移, 等同于 SAL |
| SARk,D | D←D>>Ak | 算术左移(考虑符号) |
| SHRk,D | D←D>>Lk | 逻辑 |
特殊的算术操作
支持两个 64 位数字的全 128(8字, oct word) 位乘积以及整数除法的指令, 可以看到除法是分步对高低64位操作的
| 指令 | 效果 | 描述 |
|---|---|---|
| imulqS | R[%rdx]:R[%rax]←S×R[%rax] | 有符号全乘法 |
| mulqS | R[%rdx]:R[%rax]←S×R[%rax] | 无符号全乘法 |
| cltoS | R[%rdx]:R[%rax]←符号扩展R[%rax] | 转换为8字 |
| idivqS | R[%rdx]←R[%rdx]:R[%rax]modSR[%rdx]←R[%rdx]:R[%rax]÷S | 有符号除法法 |
| divqS | R[%rdx]←R[%rdx]:R[%rax]modSR[%rdx]←R[%rdx]:R[%rax]÷S | 无符号除法法 |
控制
条件码
- CF: 进位标志。最近的操作使最高位产生了进位。可用来检查无符号操作的溢出。
- ZF: 零标志。最近的操作得出的结果为 0.
- SF: 符号标志。最近的操作得到的结果为负数
- OF: 溢出标志。最近的操作导致一个补码溢出(正溢出或者负溢出)
条件码会发生改变的操作
比较和测试指令
这两个系列指令不修改任何寄存器的值,只设置条件码
| 指令 | 效果 | 描述 |
|---|---|---|
| CMPS1,S2 | S2−S1 | 比较 |
| TESTS1,S2 | S1&S2 | 测试 |
访问条件码
| 指令 | 同义名 | 效果 | 描述 |
|---|---|---|---|
| seteD | setz | D←ZF | 相等/零 |
| setneD | setnz | D←∼ZF | 不等/非零 |
| setsD | D←SF | 负数 | |
| setnsD | D←∼SF | 负数 | |
| setgD | setnle | D←∼(SF∧OF)&∼ZF | 大于(有符号>) |
| setgeD | setnl | D←∼(SF∧OF) | 大于等于(有符号 >=) |
| setlD | setnge | D←SF∧OF | 小于(有符号<) |
| setleD | setng | D←∼(SF∧OF)∣ZF | 小于等于(有符号 <=) |
| setaD | setnbe | D←∼CF&∼ZF | 大于(无符号>) |
| setaeD | setnb | D←∼CF | 大于等于(无符号>=) |
| setbD | setnae | D←CF | 小于(无符号<) |
| setbeD | setna | D←CF∣ZF | 小于等于(无符号<=) |
跳转指令
访问条件码
| 指令 | 同义名 | 跳转条件 | 描述 |
|---|---|---|---|
| jmpLabel | 1 | 直接跳转 | |
| jmp∗Operand | 1 | 间接跳转 | |
| jeLabel | jz | ZF | 相等/零 |
| jneLabel | jnz | ∼ZF | 不相等/非零 |
| jsLabel | SF | 负数 | |
| jnsLabel | ∼SF | 非负数 | |
| jgD | jnle | D←∼(SF∧OF)&∼ZF | 大于(有符号>) |
| jgeD | jnl | D←∼(SF∧OF) | 大于等于(有符号 >=) |
| jlD | jnge | D←SF∧OF | 小于(有符号<) |
| jleD | jng | D←∼(SF∧OF)∣ZF | 小于等于(有符号 <=) |
| jaD | jnbe | D←∼CF&∼ZF | 大于(无符号>) |
| jaeD | jnb | D←∼CF | 大于等于(无符号>=) |
| jbD | jnae | D←CF | 小于(无符号<) |
| jbeD | jna | D←CF∣ZF | 小于等于(无符号<=) |
跳转指令一般将目标指令的地址与紧跟在跳转指令后面那条指令之间的差作为编码
有下C代码
int foo() {
for (int i = 0; i < 3; i++)
if (i == 1)
return 1;
return 0;
}
反汇编二进制代码
think@pc$ gcc -O0 -c foo.c
think@pc$ objdump -S foo.o
foo.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <foo>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
b: eb 11 jmp 1e <foo+0x1e>
d: 83 7d fc 01 cmpl $0x1,-0x4(%rbp)
11: 75 07 jne 1a <foo+0x1a>
13: b8 01 00 00 00 mov $0x1,%eax
18: eb 0f jmp 29 <foo+0x29>
1a: 83 45 fc 01 addl $0x1,-0x4(%rbp)
1e: 83 7d fc 02 cmpl $0x2,-0x4(%rbp)
22: 7e e9 jle d <foo+0xd>
24: b8 00 00 00 00 mov $0x0,%eax
29: 5d pop %rbp
2a: c3 retq
看第一个跳转指令在地址 b, 跳转的地址为 1e, 其值为 11 + d, 这里比较特殊的是
- 地址是无符号类型
- 相对地址为有符号类型
看内存地址为 0x22 的那条 jle 指令, 其跳转地址为 d = 0x24(unsigned) + 0xe9(-0x17,signed), 或者用两个地址相加取未溢出的部分。与 PC计数器 指向下一条执行的指令的现象相符合,这样就可以比较轻易的完成链接操作。
过程
对于我们一般的认识就是过程可以理解为函数调用。
过程的机器级支持需要处理多种属性
- 传递控制。在程序进入过程Q时PC必须设置为Q的代码起始地址,返回时要把PC设置为P中调用Q后面的那条指令的地址。
- 传递参数。P必须能够向Q提供一个或者多个参数,Q必须能够向P返回一个值。
- 分配和释放内存。在开始时,Q可能需要为局部变量分配空间,而在返回前,又必须释放这些分配的内存。
栈的弹出和压入指令
| 指令 | 效果 | 描述 |
|---|---|---|
| pushqS | R[%rsp]←R[%rsp]−8M[R[%rsp]]←S | 四字入栈 |
| popqD | D←M[R[%rsp]]R[%rsp]←R[%rsp]+8 | 四字出栈 |
一个简单的示例代码
// c 代码
long three_n_sum(long a1, long a2, long a3) { return a1 + a2 + a3; }
long sum(long a1, long a2, long a3, long a4, long a5, long a6, long a7, long a8) {
long b1 = three_n_sum(a1, a2, a3);
long b2 = three_n_sum(a4, a5, a6);
long b3 = three_n_sum(a7, a8, 0);
long b = b1 + b2 + b3;
return b;
}
int main() { long s = sum(1, 2, 3, 4, 5, 6, 7, 8); }
// 反汇编的二进制代码
0000000000001125 <three_n_sum>:
1125: 55 push %rbp
1126: 48 89 e5 mov %rsp,%rbp
1129: 48 89 7d f8 mov %rdi,-0x8(%rbp)
112d: 48 89 75 f0 mov %rsi,-0x10(%rbp)
1131: 48 89 55 e8 mov %rdx,-0x18(%rbp)
1135: 48 8b 55 f8 mov -0x8(%rbp),%rdx
1139: 48 8b 45 f0 mov -0x10(%rbp),%rax
113d: 48 01 c2 add %rax,%rdx
1140: 48 8b 45 e8 mov -0x18(%rbp),%rax
1144: 48 01 d0 add %rdx,%rax
1147: 5d pop %rbp
1148: c3 retq
0000000000001149 <sum>:
1149: 55 push %rbp
114a: 48 89 e5 mov %rsp,%rbp
114d: 48 83 ec 50 sub $0x50,%rsp
1151: 48 89 7d d8 mov %rdi,-0x28(%rbp)
1155: 48 89 75 d0 mov %rsi,-0x30(%rbp)
1159: 48 89 55 c8 mov %rdx,-0x38(%rbp)
115d: 48 89 4d c0 mov %rcx,-0x40(%rbp)
1161: 4c 89 45 b8 mov %r8,-0x48(%rbp)
1165: 4c 89 4d b0 mov %r9,-0x50(%rbp)
1169: 48 8b 55 c8 mov -0x38(%rbp),%rdx
116d: 48 8b 4d d0 mov -0x30(%rbp),%rcx
1171: 48 8b 45 d8 mov -0x28(%rbp),%rax
1175: 48 89 ce mov %rcx,%rsi
1178: 48 89 c7 mov %rax,%rdi
117b: e8 a5 ff ff ff callq 1125 <three_n_sum>
1180: 48 89 45 f8 mov %rax,-0x8(%rbp)
1184: 48 8b 55 b0 mov -0x50(%rbp),%rdx
1188: 48 8b 4d b8 mov -0x48(%rbp),%rcx
118c: 48 8b 45 c0 mov -0x40(%rbp),%rax
1190: 48 89 ce mov %rcx,%rsi
1193: 48 89 c7 mov %rax,%rdi
1196: e8 8a ff ff ff callq 1125 <three_n_sum>
119b: 48 89 45 f0 mov %rax,-0x10(%rbp)
119f: 48 8b 45 18 mov 0x18(%rbp),%rax
11a3: ba 00 00 00 00 mov $0x0,%edx
11a8: 48 89 c6 mov %rax,%rsi
11ab: 48 8b 7d 10 mov 0x10(%rbp),%rdi
11af: e8 71 ff ff ff callq 1125 <three_n_sum>
11b4: 48 89 45 e8 mov %rax,-0x18(%rbp)
11b8: 48 8b 55 f8 mov -0x8(%rbp),%rdx
11bc: 48 8b 45 f0 mov -0x10(%rbp),%rax
11c0: 48 01 c2 add %rax,%rdx
11c3: 48 8b 45 e8 mov -0x18(%rbp),%rax
11c7: 48 01 d0 add %rdx,%rax
11ca: 48 89 45 e0 mov %rax,-0x20(%rbp)
11ce: 48 8b 45 e0 mov -0x20(%rbp),%rax
11d2: c9 leaveq
11d3: c3 retq
00000000000011d4 <main>:
11d4: 55 push %rbp
11d5: 48 89 e5 mov %rsp,%rbp
11d8: 48 83 ec 10 sub $0x10,%rsp
11dc: 6a 08 pushq $0x8
11de: 6a 07 pushq $0x7
11e0: 41 b9 06 00 00 00 mov $0x6,%r9d
11e6: 41 b8 05 00 00 00 mov $0x5,%r8d
11ec: b9 04 00 00 00 mov $0x4,%ecx
11f1: ba 03 00 00 00 mov $0x3,%edx
11f6: be 02 00 00 00 mov $0x2,%esi
11fb: bf 01 00 00 00 mov $0x1,%edi
1200: e8 44 ff ff ff callq 1149 <sum>
1205: 48 83 c4 10 add $0x10,%rsp
1209: 48 89 45 f8 mov %rax,-0x8(%rbp)
120d: b8 00 00 00 00 mov $0x0,%eax
1212: c9 leaveq
1213: c3 retq
1214: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
121b: 00 00 00
121e: 66 90 xchg %ax,%ax
转移控制
将控制从函数P转移到Q只需要简单的把PC设置为Q的代码起始位置。
程序的返回处理器需要记录P的执行的代码位置,这个信息由指令callQ来记录
call指令将地址 A 压入栈中,并将PC设置为Q的起始地址,压入的地址 A 是紧跟在 call 指令后面的那条指令的地址,被称为返回地址。
运行时栈
一个函数调用栈的变化,用函数 sum() 做示例
- 将 %rbx 入栈保存上一个栈基地址,设置新的栈帧的基地址,分配栈内存(sub $0x50,%rsp)
- 将寄存器保存在栈中,设置参数,最多六个参数保存在寄存器中(参考main函数)
- 将 PC 设置为 1149, 压入call之后的指令地址 1205, 跳转
- 调用子例程则重复以上动作
- 返回则执行
leaveq等价于movl %ebp %esppopl %ebp;ret弹出返回地址并且跳转
用一张图来表示栈的变化, 观察汇编代码地址 119f 和 11ab, 在第三次调用 three_n_sum()时参数的取值时存在于 main 函数栈帧中,而参数都存在于栈顶位置也利于子例程取值。
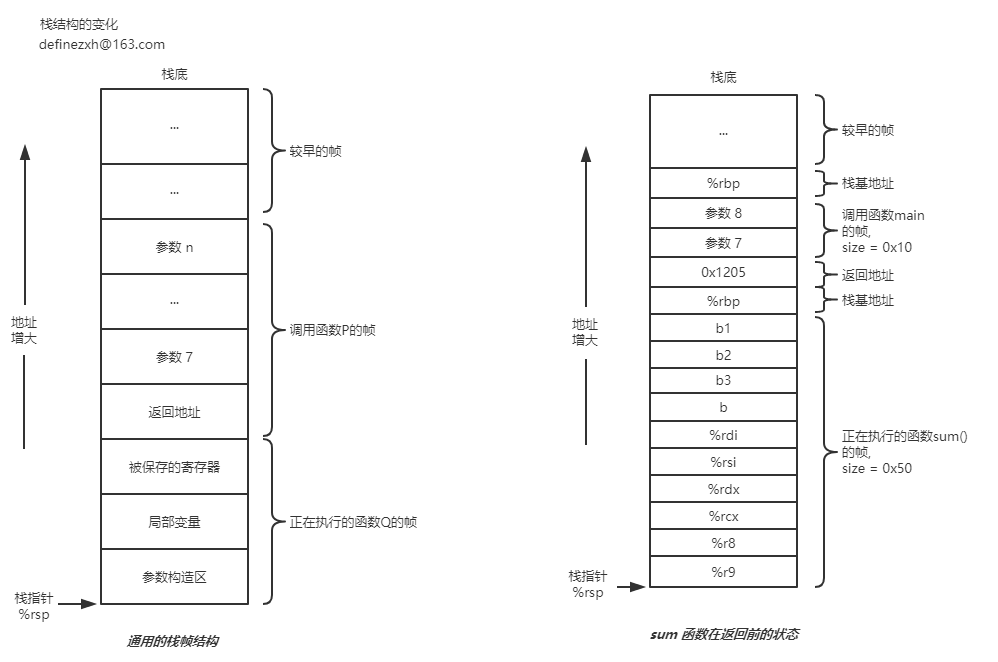
上图是CS:APP中的图,我用processon画的,折腾后面上图2中的栈结构真的是麻烦,书里的图文不符,只能根据这个汇编代码重画一下。
后面又在 15213 的课件中找到一张图,在我自己的图上栈帧的大小表示上又和课件的图有出入,拿 sum() 来看,%ebp 入栈后,栈指针继续分配栈上内存,向地址减小 0x50,课件中的栈帧包含了那个 %ebp,而我自己做的图单独列出了,这样看应该是课件中的图准确点,一个栈帧应该包含当前栈的所有信息(栈上内存 + 栈基地址 + 返回地址),不过processon上的图么有了,这里就插个眼再传个课件的图吧。
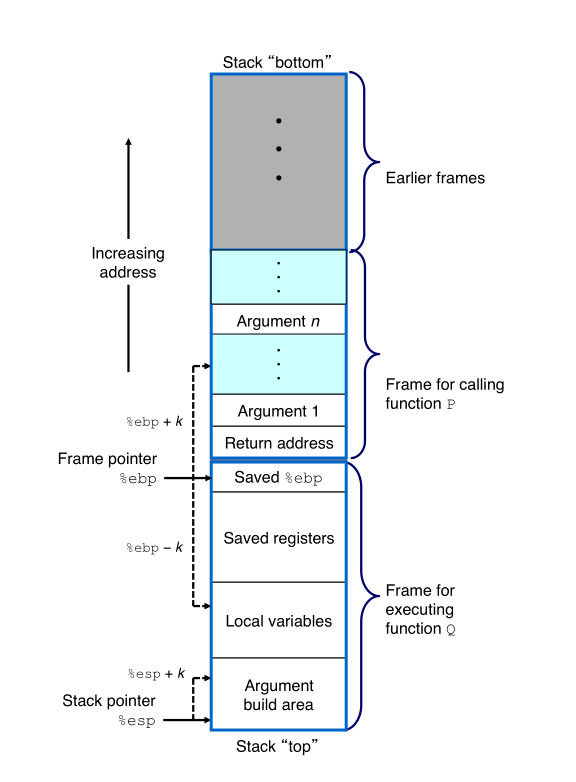
)
参考
- Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1: Basic Architecture, Intel 开发手册
- 15213, 计算机系统导论课程
- CS:APP 3e, 深入理解计算机系统


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· C++代码改造为UTF-8编码问题的总结
· DeepSeek 解答了困扰我五年的技术问题
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 实操Deepseek接入个人知识库
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库