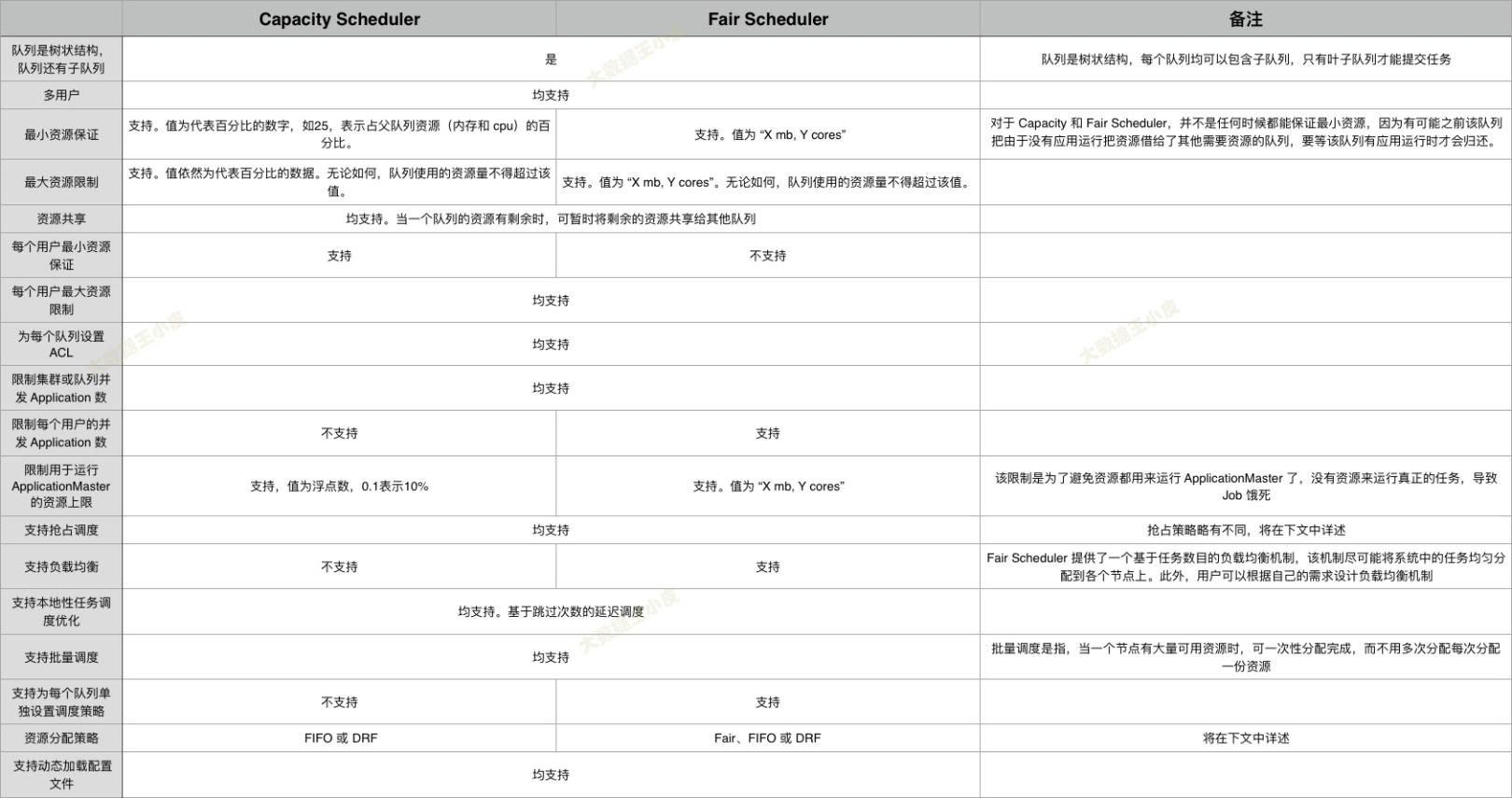
【深入浅出 Yarn 架构与实现】5-1 Yarn 资源调度器基本框架
资源调度器是 YARN 中最核心的组件之一,它是 ResourceManager 中的一个插拔式服务组件,负责整个集群资源的管理和分配。
Yarn 默认提供了三种可用资源调度器,分别是FIFO (First In First Out )、 Yahoo! 的 Capacity Scheduler 和 Facebook 的 Fair Scheduler。
本节会重点介绍资源调度器的基本框架,在之后文章中详细介绍 Capacity Scheduler 和 Fair Scheduler。
一、基本架构
资源调度器是最核心的组件之一,并且在 Yarn 中是可插拔的,Yarn 中定义了一套接口规范,以方便用户实现自己的调度器,同时 Yarn 中自带了FIFO,CapacitySheduler, FairScheduler三种常用资源调度器。

一)资源调度模型
Yarn 采用了双层资源调度模型。
- 第一层中,RM 中的资源调度器将资源分配给各个 AM(Scheduler 处理的部分)
- 第二层中,AM 再进一步将资源分配给它的内部任务(不是本节关注的内容)
Yarn 的资源分配过程是异步的,资源调度器将资源分配给一个应用程序后,它不会立刻 push 给对应的 AM,而是暂时放到一个缓冲区中,等待 AM 通过周期性的心跳主动来取(pull-based通信模型)
- NM 通过周期心跳汇报节点信息
- RM 为 NM 返回一个心跳应答,包括需要释放的 container 列表等信息
- RM 收到的 NM 信息触发一个NODE_UPDATED事件,之后会按照一定策略将该节点上的资源分配到各个应用,并将分配结果放到一个内存数据结构中
- AM 向 RM 发送心跳,获得最新分配的 container 资源
- AM 将收到的新 container 分配给内部任务
二)资源表示模型
NM 启动时会向 RM 注册,注册信息中包含该节点可分配的 CPU 和内存总量,这两个值均可通过配置选项设置,具体如下:
yarn.nodemanager.resource.memory-mb:可分配的物理内存总量,默认是8Gyarn.nodemanager.vmem-pmem-ratio:任务使用单位物理内存量对应最多可使用的虚拟内存,默认值是2.1,表示使用1M的物理内存,最多可以使用2.1MB的虚拟内存总量yarn.nodemanager.resource.cpu-vcores:可分配的虚拟CPU个数,默认是8。为了更细粒度地划分CPU资源和考虑到CPU性能差异,YARN允许管理员根据实际需要和CPU性能将每个物理CPU划分成若干个虚拟CPU,而管理员可为每个节点单独配置可用的虚拟CPU个数,且用户提交应用程序时,也可指定每个任务需要的虚拟CPU数
Yarn 支持的调度语义:
- 请求某个节点上的特定资源量
- 请求某个特定机架上的特定资源量
- 将某些节点加入(或移除)黑名单,不再为自己分配这些节点上的资源
- 请求归还某些资源
Yarn 不支持的调度语义(随着 Yarn 的不断迭代,可能会在未来实现):
- 请求任意节点上的特定资源量
- 请求任意机架上的特定资源量
- 请求一组或几组符合某种特质的资源
- 超细粒度资源。比如CPU性能要求、绑定CPU等
- 动态调整Container资源,允许根据需要动态调整Container资源量
三)资源保证机制
当单个节点的闲置资源无法满足应用的一个 container 时,有两种策略:
- 放弃当前节点等待下一个节点;
- 在当前节点上预留一个 container 申请,等到节点有资源时优先满足预留。
YARN 采用了第二种增量资源分配机制(当应用程序申请的资源暂时无法保证时,为应用程序预留一个节点上的资源直到累计释放的空闲资源满足应用程序需求),这种机制会造成浪费,但不会出现饿死现象
四)层级队列管理
Yarn 的队列是层级关系,每个队列可以包含子队列,用户只能将任务提交到叶子队列。管理员可以配置每个叶子队列对应的操作系统用户和用户组,也可以配置每个队列的管理员。管理员可以杀死队列中的任何应用程序,改变任何应用的优先级等。
队列的命名用 . 来连接,比如 root.A1、root.A1.B1。
二、三种调度器
Yarn 的资源调度器是可以配置的,默认实现有三种 FIFO、CapacityScheduler、FairScheduler。
一)FIFO
FIFO 是 Hadoop设计之初提供的一个最简单的调度机制:先来先服务。
所有任务被统一提交到一个队里中,Hadoop按照提交顺序依次运行这些作业。只有等先来的应用程序资源满足后,再开始为下一个应用程序进行调度运行和分配资源。
优点:
- 原理是和实现简单。也不需要任何单独的配置
缺点:
- 无法提供 QoS,只能对所有的任务按照同一优先级处理。
- 无法适应多租户资源管理。先来的大应用程序把集群资源占满,导致其他用户的程序无法得到及时执行。
- 应用程序并发运行程度低。
二)Capacity Scheduler
Capacity Scheduler 容量调度是 Yahoo! 开发的多用户调度器,以队列为单位划分资源。
每个队列可设定一定比例的资源最低保证和使用上限。每个用户也可设置一定的资源使用上限,以防资源滥用。并支持资源共享,将队列剩余资源共享给其他队列使用。配置文件名称为 capacity-scheduler.xml。
主要特点:
- 容量保证:可为每个队列设置资源最低保证(capacity)和资源使用上限(maximum-capacity,默认100%),而所有提交到该队列的应用程序可以共享这个队列中的资源。
- 弹性调度:如果队列中的资源有剩余或者空闲,可以暂时共享给那些需要资源的队列,一旦该队列有新的应用程序需要资源运行,则其他队列释放的资源会归还给该队列,从而实现弹性灵活分配调度资源,提高系统资源利用率。
- 多租户管理:支持多用户共享集群资源和多应用程序同时运行。且可对每个用户可使用资源量(user-limit-factor)设置上限。
- 安全隔离:每个队列设置严格的ACL列表(acl_submit_applications),用以限制可以用户或者用户组可以在该队列提交应用程序。
三)Fair Scheduler
Fair Scheduler 是 Facebook 开发的多用户调度器。设计目标是为所有的应用分配「公平」的资源(对公平的定义可以通过参数来设置)。公平不仅可以在队列中的应用体现,也可以在多个队列之间工作。
在 Fair 调度器中,我们不需要预先占用一定的系统资源,Fair 调度器会为所有运行的 job 动态的调整系统资源。如下图所示,当第一个大 job 提交时,只有这一个 job 在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair 调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
与Capacity Scheduler不同之处:
四)源码继承关系
看下面三个图中调度器的继承关系。这三个 Scheduler 都继承自 AbstractYarnScheduler。这个抽象类又 extends AbstractService implements ResourceScheduler。继承 AbstractService 说明是一个服务,实现 ResourceScheduler 是 scheduler 的主要功能。
三者还有一些区别,FairScheduler 没实现 Configurable 接口,少了 setConf() 方法;FifoScheduler 不支持资源抢占,FairScheduler 支持资源抢占却没实现 PreemptableResourceScheduler 接口。
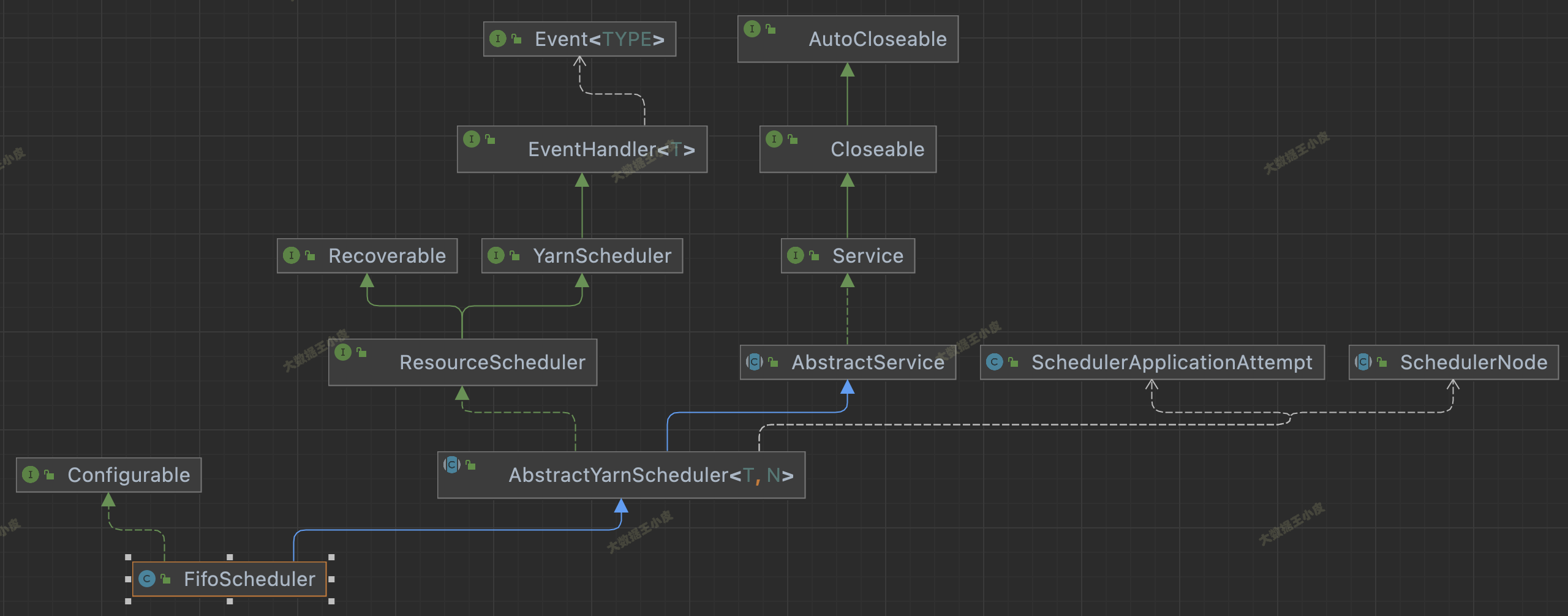
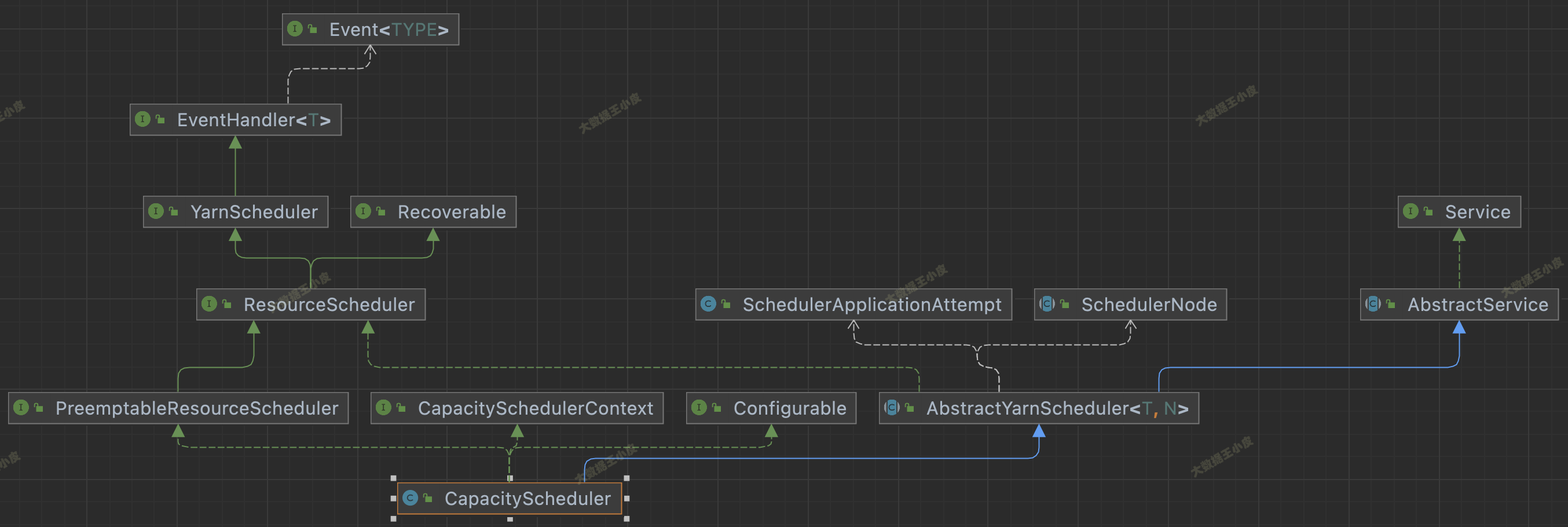
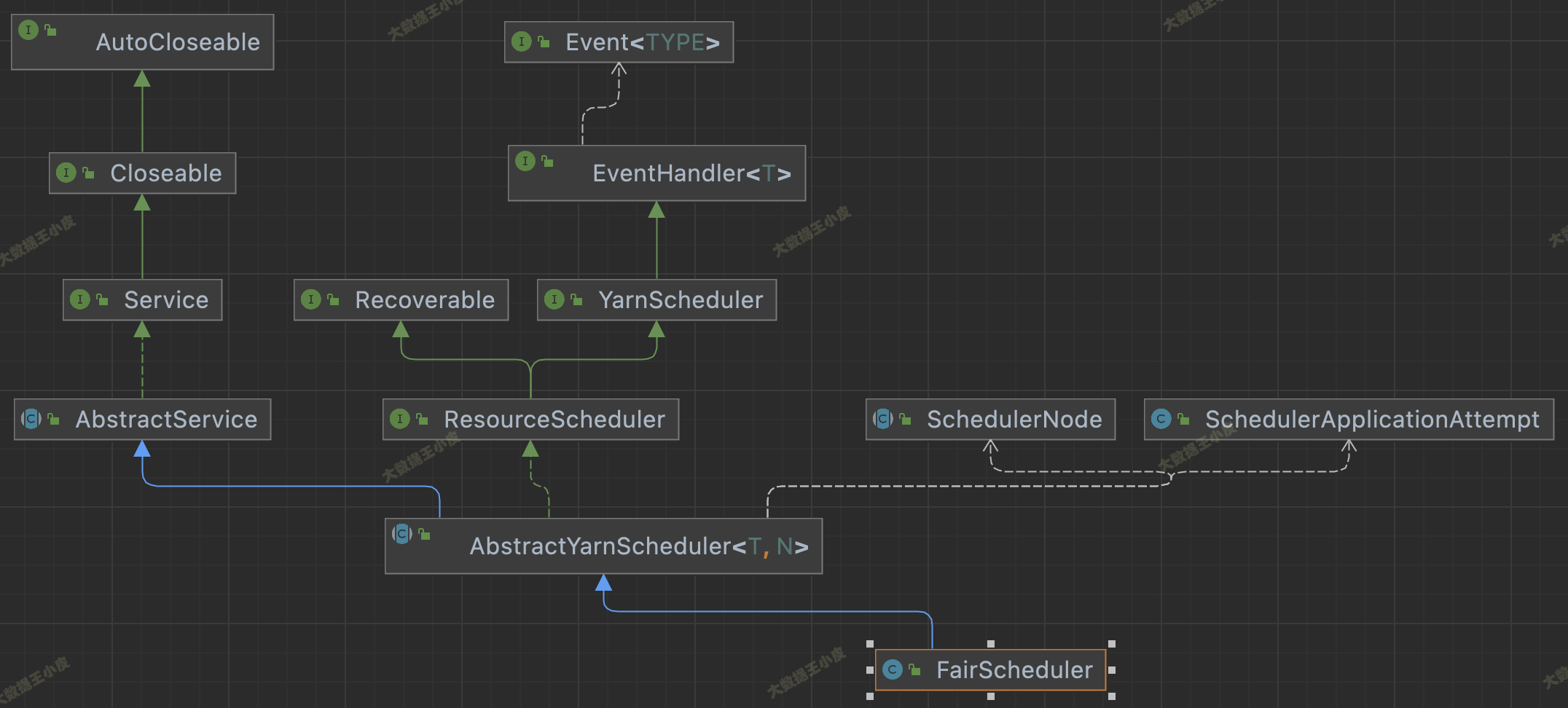
在 YarnScheduler 中,定义了一个资源调度器应该实现的方法。在 AbstractYarnScheduler 中实现了大部分方法,若自己实现调度器可继承该类,将发开重点放在资源分配实现上。
public interface YarnScheduler extends EventHandler<SchedulerEvent> {
// 获得一个队列的基本信息
public QueueInfo getQueueInfo(String queueName, boolean includeChildQueues,
boolean recursive) throws IOException;
// 获取集群资源
public Resource getClusterResource();
/**
* AM 和资源调度器之间最主要的一个方法
* AM 通过该方法更新资源请求、待释放资源列表、黑名单列表增减
*/
@Public
@Stable
Allocation allocate(ApplicationAttemptId appAttemptId,
List<ResourceRequest> ask, List<ContainerId> release,
List<String> blacklistAdditions, List<String> blacklistRemovals,
List<UpdateContainerRequest> increaseRequests,
List<UpdateContainerRequest> decreaseRequests);
// 获取节点资源使用情况报告
public SchedulerNodeReport getNodeReport(NodeId nodeId);
ResourceScheduler 本质是个事件处理器,主要处理10种事件(CapacityScheduler 还会多处理几种抢占相关的事件),可以到对应 Scheduler 的 handle() 方法中查看这些事件处理逻辑:
NODE_ADDED: 集群中增加一个节点NODE_REMOVED: 集群中移除一个节点NODE_RESOURCE_UPDATE: 集群中有一个节点的资源增加了NODE_LABELS_UPDATE: 更新node labelsNODE_UPDATE: 该事件是 NM 通过心跳和 RM 通信时发送的,会汇报该 node 的资源使用情况,同时触发一次分配操作。APP_ADDED: 增加一个ApplicationAPP_REMOVED: 移除一个applicationAPP_ATTEMPT_ADDED: 增加一个application AttemptAPP_ATTEMPT_REMOVED: 移除一个application attemptCONTAINER_EXPIRED: 回收一个超时的container
三、资源调度维度
目前有两种:DefaultResourceCalculator 和 DominantResourceCalculator。
DefaultResourceCalculator: 仅考虑内存资源DominantResourceCalculator: 同时考虑内存和 CPU 资源(后续更新中支持更多类型资源,FPGA、GPU 等)。该算法扩展了最大最小公平算法(max-min fairness)。- 在 DRF 算法中,将所需份额(资源比例)最大的资源称为主资源,而 DRF 的基本设计思想则是将最大最小公平算法应用于主资源上,进而将多维资源调度问题转化为单资源调度问题,即 DRF 总是最大化所有主资源中最小的
- 感兴趣的话,可到源码中
DominantResourceCalculator#compare探究实现逻辑 - 对应的论文 《Dominant Resource Fairness: Fair Allocation of Multiple Resource Types》
(这里注意!很多文章和书中写的是「YARN 资源调度器默认采用了 DominantResourceCalculator」,实际并不是这样的!)
FifoScheduler默认使用DefaultResourceCalculator且不可更改。CapacityScheduler是在capacity-scheduler.xml中配置yarn.scheduler.capacity.resource-calculator参数决定的。FairScheduler才默认使用DominantResourceCalculator。
四、资源抢占模型
这里仅简要介绍资源抢占模型,在后面的文章中会深入源码分析抢占的流程。
- 在资源调度器中,每个队列可设置一个最小资源量和最大资源量,其中,最小资源量是资源紧缺情况下每个队列需保证的资源量,而最大资源量则是极端情况下队列也不能超过的资源使用量
- 为了提高资源利用率,资源调度器(包括Capacity Scheduler和Fair Scheduler)会将负载较轻的队列的资源暂时分配给负载重的队列,仅当负载较轻队列突然收到新提交的应用程序时,调度器才进一步将本属于该队列的资源分配给它。
五、总结
本文介绍了 Yarn 资源调度器的基本框架,包括基本架构,以及简要介绍三种 YARN 实现的调度器,并对资源调度维度,资源抢占模型等进行了介绍。
后续文章中将会围绕三种 YARN 调度器,深入源码进行探究。看其在源码中是如何一步步实现对应功能的。
参考文章:
《Hadoop 技术内幕:深入解析 YARN 架构设计与实现原理》第六章
深入解析yarn架构设计与技术实现-资源调度器
Yarn源码分析5-资源调度

