Large Sacle Distributed Deep Networks
本文是谷歌发表在NeurIPS 2012上的一篇论文,主要讨论了在几万个CPU节点上训练大规模深度网络的问题,并提出了一个名为DistBelief的软件框架。在该框架下实现了两种大规模分布式训练算法:Downpour SGD和Sandblaster L-BFGS,这两种算法都增加了深度网络训练的规模和速度。
Introduction
最近几年,深度学习在语音识别、图像识别以及自然语言处理等领域大放异彩。就训练样本的数量和模型参数的数量而言,增加深度学习的规模可以极大地提高最终模型的效果。GPU的使用是近年来的一项重大进步,使得适度规模的深度网络的训练变得切实可行。然而,使用GPU进行训练的一大限制是模型必须与GPU的存储器(通常小于6G)相匹配。为了高效地使用GPU,人们通常减小数据或参数的大小以降低数据在CPU与GPU之间进行转换的开销。然而,这种方法在小规模问题(如语音识别)上表现的还不错,但是在大规模任务(如大规模图像分类问题)上并没有多大作用。
本文提出了一种途径来解决上述问题:即使用大规模集群对深度神经网络进行训练与推断。本文提出了一个叫DistBelief的框架,通过对并行、同步和通信的管理,该框架允许我们在单机(多线程)和多机(通过消息传递)进行模型并行。DistBelife还支持数据并行,也就是多个模型优化同一个目标函数。在该框架下,我们提出了两种新的大规模分布式训练算法:Downpour SGD和Sandblaster L-BFGS。Downpur SGD是一种拥有自适应学习率和支持大量模型副本的异步随机梯度下降算法;而Sandblaster L-BFGS则是L-BFGS使用数据并行和模型并行的分布式实现。
Previous work
在我们之前有很多研究者研究并行和分布式机器学习,但是他们主要聚焦于线性的、凸的模型,而分布式梯度下降可以说是开创了先河。在这方面,之前有人在凸优化问题上做过延迟梯度更新相关的研究。与此同时,还有人在做稀疏梯度优化问题。但是本文做的工作更厉害,我们集前人之所长,提出了一些在大规模集群上异步的计算梯度的算法,无论问题是凸的还是稀疏的。
在深度学习中,大多数人都在研究如何在单机上训练一个比较小的模型。如果想要进行大规模的深度学习,那么就要在一堆GPU上训练一堆模型,然后取这些模型输出的均值作为最后的预测值。或者修改原始的标准神经网络,使它们具有更高的并行性。我们的目标是在大规模集群上无任何限制地训练非常大的模型(差不多有几十亿个参数的那种)。在某一层需要大量计算的特殊情况下,一些研究者考虑在一层中分配计算量并在剩余层中复制那些计算。但是大多数情况下,模型的许多层都是计算密集型的,这就需要借鉴文章[22]的模型并行思想。但是,我们坚信,为了最终的成功,模型并行和数据并行必须要结合在一起使用。
我们之前考虑过一些已存的大规模计算工具,如MapReduce和GraphLab,但是它们都不好用。所以,我们自己开发了一个(就是DistBelief)。
Model Parallelism
在DistBelief中,用户定义模型中发生计算的层中的节点,然后消息就会在前向和后向计算中进行传播。对于大的模型,用户可以把模型分到不同的机器上(如Figure 1)所示。这样,不同节点的计算任务就被分配到了不同的机器上。DistBelief框架自动地在所有的机器上进行并行计算,并且在训练和推断阶段对通信、同步和数据在不同机器间的转换进行管理。
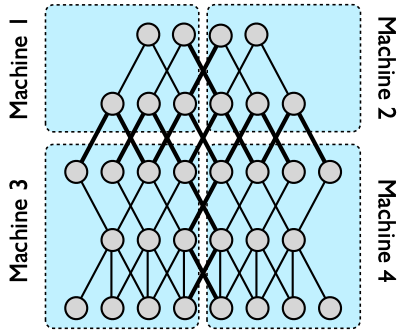
多机的分布式深层网络的性能优势取决于模型的连接结构和计算需求。具有大量参数或较高计算需求的模型通常受益于更多的CPU和内存,一直到通信成本占据主导地位。显然,由于对通信的要求较低,具有局部连接结构的模型往往比全连接的结构更适合分布式训练。有时候这种加速可能不太理想,一个典型原因是不同机器的处理时间有差异,导致许多机器完成计算后需要等待一个最慢的机器。当与下一节中描述的分布式优化算法(使用整个神经网络的多个副本)结合使用时,可以使用数万个CPU来训练单个模型,从而显着减少整体训练时间。
Distributed Optimization Algorithms
使用DistBelief框架,我们可以训练大型的神经网络,但是我们同样需要分布式的优化算法来缩短训练神经网络所需要的时间。在本小节,我们介绍两种分布式优化算法。

Downpour SGD
SGD是一种比较成功的算法,但是它不适用于大规模的数据。为了处理大规模数据集,我们提出了Downpour SGD,它是一种在单个DistBelief模型上使用多个副本的异步随机梯度下降的变体。主要流程为:我们首先把训练数据分成几个子集,在每个子集上运行一份模型的副本;每个模型都和一个集中式的参数服务器交互然后更新梯度,这个参数服务器通过多机共享保存了当前所有参数的状态。上面这个算法是异步的,体现在以下两个方面:首先,每个模型副本都是独立运行的;其次,参数服务器独立于每个模型而运行。
在最朴素的实现中,处理每个批次的数据之前,模型副本都要请求参数服务器来获取当前模型的参数。因为模型是在多个机器上存储的,所以每台机器都要对参数服务器进行请求。在得到参数服务器发来的参数数据后,每个模型副本都计算梯度,然后将梯度传回参数服务器。
可以看到,上面那种实现的网络通信开销非常大,所以有一些办法来降低网络通信开销。一种可行的办法是:每\(n_{fetch}\)步向参数服务器请求更新参数,每n_push步向参数服务器发送梯度(其中\(n_{fetch}\)和\(n_{push}\)的值可能不相等)。事实上,获取参数、推送梯度和处理训练数据可以在三个弱同步的进程中执行。为了和传统SGD进行比较,在本文后面的实验中,取\(n_{fetch}=n_{push}=1\)。
Downpour SGD比标准的同步SGD对机器故障具有更强的鲁棒性。在同步SGD中,如果一台机器发生故障,那么整个训练过程就会被拖延;对于异步SGD来说,一台机器发生故障并不影响其他机器中的模型。另一方面,Downpour SGD中的多种形式的异步处理在优化过程中引入了大量额外的随机性。最明显的是,模型副本肯定是基于一组略微过时的参数计算的,因为其他一些模型副本可能在此期间更新了参数服务器上的参数。除此之外,还有其他的随机性来源:不能保证在任何给定时刻参数服务器的每个分片上的参数都经历了相同数量的更新,或者以相同的顺序进行了更新。此外,由于允许模型副本在单独的线程中获取参数和推送梯度,因此参数的时间戳可能存在微小的不一致。
另外,使用Adagrad算法更新参数可以增加Downpour SGD算法的鲁棒性。因为这些学习速率仅根据每个参数的梯度的平方和计算,因此Adagrad很容易在每个参数服务器分片中本地实现。
Sandblaster L-BFGS
批处理方法在训练小型神经网络时效果很好,为了在大规模数据上使用批处理方法,我们在DistBelief框架下基于L-BFGS实现了SandBlaster L-BFGS算法。Sandblaster L-BFGS的一个关键思想是分布式参数存储和操作。优化算法的核心(例如L-BFGS)驻留在协调器进程(Figure 2)中,该进程无法直接访问模型参数。相反,协调器发出从一组操作(例如,点积、缩放、系数加法、乘法)中抽取的命令,该命令独立地与每个参数服务器分片一起执行,并将结果存储在同一分片上。附加信息(L-BFGS的历史缓存)也存储在计算它的参数服务器分片上。这就减小了训练大型模型时,将参数和梯度传给中央参数服务器的开销。
在传统的L-BFGS的并行化实现中,数据被分发到许多机器,并且每个机器负责计算特定数据子集的梯度。许多这样的方法都会等待那个最慢的机器,所以这不适合扩展到大规模集群上。为了解决这个问题,我们这样做:协调器为N个模型副本中的每一个都分配一小部分任务(远小于批处理总大小的1/N),并且只要它们空闲就分配新任务。也就是俗称的“能者多劳”策略。为了在批处理结束时进一步管理较慢的模型副本,协调器会调度未完成部分任务的多个副本,并且处理所有已完成的结果。通过将数据的连续部分分配给同一工作节点来预取数据以及支持数据亲和性使得数据访问不再是一个问题。与需要高带宽进行参数同步的Downpour SGD相比,Sandblaster worker仅在每批开始时获取参数,并且每隔几个完成部分仅发送少量梯度。
Experiments
这一小节主要是在介绍实验结果。本文主要在图像识别和语音识别任务上做的实验,对每个任务分别设计了一个神经网络。首先比较的是机器数量对训练加速比的影响。
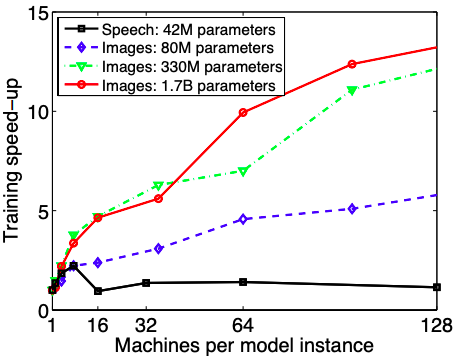
可以看出,对于语音识别的任务,使用8台机器进行分布式训练加速效果最好,大概比单机训练快2.2倍。当机器数大于8时,节点间的通信成为主要开销,这时候对训练的加速效果反而会降低。相反的是,随着机器数量的增多,使用局部连接的图像模型的训练速度会一直加快,但是边际收益会随着机器数量的增多而减小。
下面比较几种不同的优化算法的效果。

可以看到,无论是训练还是测试阶段,Downpour SGD with Adagard的效果最好,Sandblaster L-BFGS的效果其次。以上两种算法都比使用高性能GPU训练模型来的快。图5则展示了在不同机器数与CPU核心数下为了达到16%的准确率各训练算法所需要的时间。可以看到,Downpour SGD with Adagard在较小的集群上能够以较短的时间达到规定的正确率。

本文来自博客园,作者:shuo-ouyang,转载请注明原文链接:https://www.cnblogs.com/shuo-ouyang/p/14145688.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号