hadoop环境搭建整合
1.安装虚拟机
1.1 设置主机NAT网络
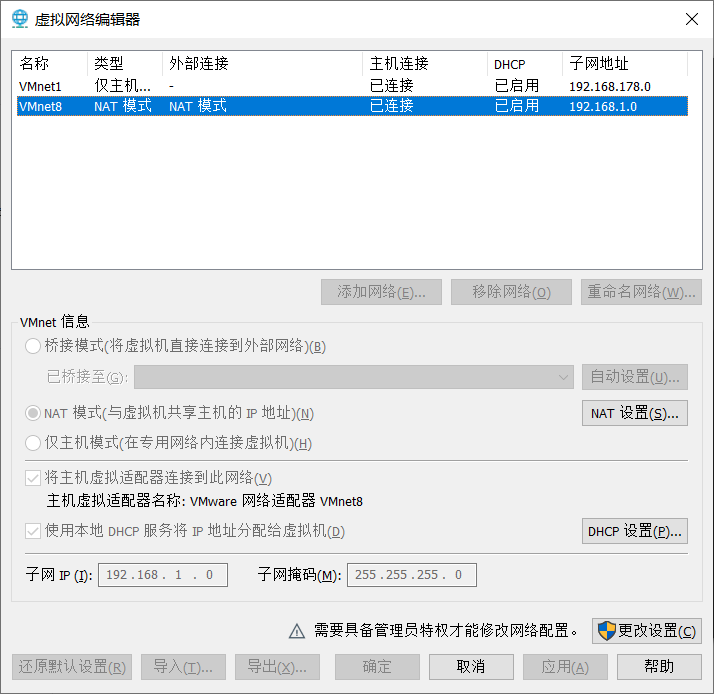


1.2 修改IP地址
vim /etc/sysconfig/network-scripts/ifcfg-eth0
#系统启动的时候网络接口是否有效(yes/no)
ONBOOT=yes
# IP的配置方法[none|static|bootp|dhcp](引导时不使用协议|静态分配IP|BOOTP协议|DHCP协议)
BOOTPROTO=static
#IP地址
IPADDR=192.168.1.101
#网关
GATEWAY=192.168.1.2
#域名解析器
DNS1=192.168.1.2
1.3 执行service network restart
1.4 修改Linux的主机名
vi /etc/sysconfig/network
HOSTNAME= hadoop101
1.5 修改Linux的主机映射文件
vim /etc/hosts
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
1.6 修改Windows主机映射文件
C:\Windows\System32\drivers\etc
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
1.7 查看网络服务状态
service network status
1.8 防火墙操作
#查看防火墙状态
service iptables status
#临时关闭防火墙
service iptables stop
#设置开机时关闭防火墙
chkconfig iptables off
1.9 立刻关机
shutdown -h now
1.10 修改克隆后虚拟机的ip
vim /etc/udev/rules.d/70-persistent-net.rules
#删除eth0该行;将eth1修改为eth0,同时复制物理ip地址
1.11 修改ip
vim /etc/sysconfig/network-scripts/ifcfg-eth0
HWADDR=00:0C:2x:6x:0x:xx #MAC地址
IPADDR=192.168.1.101 #IP地址
1.12添加一个用户
#添加用户名
useradd layman
#设置密码
passwd layman
1.13设置用户权限
vi /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
layman ALL=(ALL) ALL
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
layman ALL=(ALL) NOPASSWD:ALL
1.14 用普通用户在/opt目录下创建两个文件夹
sudo mkdir module
sudo mkdir soft
chown -R layman:layman /opt/soft /opt/module
2.搭建环境(soft:安装包,module:安装路径)
2.1安装jdk
#查询openjdk
rpm -qa | grep java
sudo rpm -e --nodeps xxx
tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
sudo vim /etc/profile
##JAVA_HOME
JAVA_HOME=/opt/module/jdk1.8.0_144
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
#配置立即生效
source /etc/profile
#测试jdk安装
jps|java|javac|java -version
2.2 安装hadoop
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
sudo vi /etc/profile
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#配置立即生效
source /etc/profile
#测试hadoop安装
hadoop version
2.3 配置hadoop
2.3.1 配置:hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
2.3.2 配置:core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
2.3.3 配置:hdfs-site.xml
<configuration>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:50090</value>
</property>
</configuration>
2.3.4 配置:mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
<!--第三方框架使用yarn计算的日志聚集功能 -->
<property> <name>yarn.log.server.url</name> <value>http://hadoop101:19888/jobhistory/logs</value> </property>
</configuration>
2.3.5 配置:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
2.3.6 配置slaves
hadoop101
hadoop102
hadoop103
2.4 配置脚本
chmod 777 xxx 或者chmod u+x xxx
2.4.1 xcall
#!/bin/bash
#验证参数
if(($#==0))
then
echo 请传入要执行的命令!
exit;
fi
echo "要执行的命令是:$@"
#批量执行
for((i=102;i<=104;i++))
do
echo -----------------------hadoop$i---------------------
ssh hadoop$i $@
done
2.4.2 xsync
#!/bin/bash
#验证参数
if(($#!=1))
then
echo 请传入要分发的单个文件!
exit;
fi
#获取分发文件的绝对路径
dirpath=$(cd -P `dirname $1`; pwd)
filename=$(basename $1)
echo "要分发的文件路径是:$dirpath/$filename"
#获取当前的用户名
user=$(whoami)
#分发,前提是集群中的机器都有当前分发文件所在的父目录
for((i=102;i<=104;i++))
do
echo -----------------------hadoop$i---------------------
rsync -rvlt $dirpath/$filename $user@hadoop$i:$dirpath
done
2.4.3 配置non-login-shell读取/etc/profile
vim ~/.bashrc
source /etc/profile
##或者依次实现cat /etc/profile >> ~/.bashrc
2.5 配置ssh免密登录
ssh 192.168.1.103
#出现yes/no选项,输入yes,没有则按enter
ssh-keygen -t rsa
#设置免密登录到102,103,104
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
2.6 分发文件
xsync hadoop
2.6.1 格式化namenode
#如果不是第一次使用,删除整个namenode的data文件夹,再执行
#执行之前先停止namenode和datanode进程
hdfs namenode -format
start-dfs.sh
start-yarn.sh
2.7 配置hadoop群起
hd
#!/bin/bash
#hadoop集群的一键启动脚本
if(($#!=1))
then
echo '请输入start|stop参数!'
exit;
fi
#只允许传入start和stop参数
if [ $1 = start ] || [ $1 = stop ]
then
$1-dfs.sh
$1-yarn.sh
ssh hadoop102 mr-jobhistory-daemon.sh $1 historyserver
else
echo '请输入start|stop参数!'
fi
2.8 使用yum 安装文件时候出现的小问题(centos6.8)
Error: Cannot find a valid baseurl for repo: base
PYCURL ERROR 22 - "The requested URL returned error: 404 Not Found"
解决方案
sed -i "s|enabled=1|enabled=0|g" /etc/yum/pluginconf.d/fastestmirror.conf
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
curl -o /etc/yum.repos.d/CentOS-Base.repo https://www.xmpan.com/Centos-6-Vault-Aliyun.repo
yum clean all
yum install xxx
3.安装zookeeper
tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
##ZK的日志配置
##客户端
bin/zkEnv.sh 60行 ZOO_LOG4J_PROP="ERROR,CONSOLE"
##服务端
bin/zkEnv.sh 脚本前定义 ZOO_LOG_DIR=/opt/module/zookeeper-3.4.10/logs
3.1 配置zoo.cfg文件
mv zoo_sample.cfg zoo.cfg
#在ZOOKEEPER_HOME目录下创建日志和原数据文件夹
mkdir logs datas
vim zoo.cfg
dataDir=/opt/module/zookeeper-3.4.10/datas
server.102=hadoop102:2888:3888
server.103=hadoop103:2888:3888
server.104=hadoop104:2888:3888
#datas文件夹下创建myid,此处的myid为上面server的id号
102
xsync zoo.cfg#注意配置每个server的myid
3.2 配置zk群起
zk
#!/bin/bash
if(($#!=1))
then
echo 请输入start或stop或status!
exit;
fi
if [ $1 = start ] || [ $1 = stop ] || [ $1 = status ]
then
xcall zkServer.sh $1
else
echo 请输入start或stop或status!
fi
4 安装flume
tar -zxf apache-flume-1.7.0-bin.tar.gz -C /opt/module/
mv apache-flume-1.7.0-bin flume
mv flume-env.sh.template flume-env.sh
vi flume-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
5 Kafka集群安装
tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/module/
mv kafka_2.11-0.11.0.0/ kafka
在KAFKA_HOME目录下创建logs文件夹
mkdir logs
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
vi server.properties
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka/logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181
#分别在hadoop103和hadoop104上修改配置文件/opt/module/kafka/config/server.properties中的broker.id=1、broker.id=2
5.2配置群起
kf
#!/bin/bash
#只接收start和stop参数
if(($#!=1))
then
echo 请输入start或stop!
exit;
fi
if [ $1 = start ]
then
xcall kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
elif [ $1 = stop ]
then xcall kafka-server-stop.sh
else
echo 请输入start或stop!
fi
6 安装Hive
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /opt/module/
mv apache-hive-1.2.1-bin/ hive
mv hive-env.sh.template hive-env.sh
6.1 配置hive-env.sh文件
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export HIVE_CONF_DIR=/opt/module/hive/conf
6.2 配置hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration>
6.3 配置hive-log4j.properties
hive.log.dir=/opt/module/hive/logs
7 安装mysql5.6
7.1 安装MySQL
1.检查本机是否已经安装了mysql的一些软件包,防止冲突
rpm -qa | grep mysql
rpm -qa | grep MySQL
卸载残留的软件包:
sudo rpm -e --nodeps mysql-libs-5.1.73-7.el6.x86_64
2.安装5.6
sudo rpm -ivh MySQL-client-5.6.24-1.el6.x86_64.rpm
sudo rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm
3.配置root用户的密码
查看生成的随机密码: sudo cat /root/.mysql_secret
使用随机密码登录修改新的密码:
启动服务: sudo service mysql start
使用随机密码登录,后修改密码: set password=password('123456');
4.配置root用户可以再任意机器登录的帐号
①查看本机的所有帐号
select host,user,password from mysql.user;
②删除不是locahost的root用户
delete from mysql.user where host <> 'localhost';
③将host=localhost修改为%
update mysql.user set host='%' where user='root';
④刷新用户
flush privileges;
⑤测试root是否可以从localhost主机名登录
mysql -uroot -p123456
⑥测试root是否可以从hadoop103(从外部地址)主机名登录
mysql -h hadoop103 -uroot -p123456
⑦查看当前mysql服务器收到了哪些客户端连接请求
sudo mysqladmin processlist -uroot -p123456
5.mysql自定义配置文件的存放位置
/etc/my.cnf /etc/mysql/my.cnf /usr/etc/my.cnf ~/.my.cnf
7.2 配置mysql双向主从
四、配置互为主从的MySQL
1.到/usr/share/mysql下找mysql服务端配置的模版
sudo cp my-default.cnf /etc/my.cnf
2.编辑my.cnf
在[mysqld]下配置:
server_id = 103
log-bin=mysql-bin
binlog_format=mixed
relay_log=mysql-relay
另外一台,配置也一样,只需要修改servei_id
3.重启mysql服务
sudo service mysql restart
4.在主机上使用root@localhost登录,授权从机可以使用哪个用户登录
GRANT replication slave ON *.* TO 'slave'@'%' IDENTIFIED BY '123456';
5.查看主机binlog文件的最新位置
show master status;
6.在从机上执行以下语句
change master to master_user='slave', master_password='123456',master_host='192.168.6.103',master_log_file='mysql-bin.000001',master_log_pos=311;
7.在从机上开启同步线程
start slave
8.查看同步线程的状态
show slave status \G
change master to master_user='slave', master_password='123456',master_host='192.168.6.102',master_log_file='mysql-bin.000001',master_log_pos=311;
7.3 配置高可用
五、在hadoop103和hadoop102安装keepalive软件
1.安装
sudo yum install -y keepalived
2.配置
sudo vim /etc/keepalived/keepalived.conf
###! Configuration File for keepalived
global_defs {
router_id MySQL-ha
}
vrrp_instance VI_1 {
state master #初始状态
interface eth0 #网卡
virtual_router_id 51 #虚拟路由id
priority 100 #优先级
advert_int 1 #Keepalived心跳间隔
nopreempt #只在高优先级配置,原master恢复之后不重新上位
authentication {
auth_type PASS #认证相关
auth_pass 1111
}
virtual_ipaddress {
192.168.1.100 #虚拟ip
}
}
#声明虚拟服务器
virtual_server 192.168.1.100 3306 {
delay_loop 6
persistence_timeout 30
protocol TCP
#声明真实服务器
real_server 192.168.1.103 3306 {
notify_down /var/lib/mysql/killkeepalived.sh #真实服务故障后调用脚本
TCP_CHECK {
connect_timeout 3 #超时时间
nb_get_retry 1 #重试次数
delay_before_retry 1 #重试时间间隔
}
}
}
###
3.编辑当前机器keepalived检测到mysql故障时的通知脚本
sudo vim /etc/keepalived/keepalived.conf
加执行权限
sudo chmod +x /var/lib/mysql/killkeepalived.sh
添加如下内容:
#!/bin/bash
#停止当前机器的keepalived进程
sudo service keepalived stop
4.开机自启动keepalived服务
sudo chkconfig keepalived on
5.启动keepalived服务,只需要当前启动,以后都可以开机自启动
sudo service keepalived start
6.查看当前机器是否持有虚拟ip
ip a
补充: mysql和keepalived服务都是开机自启动,keepalived服务一启动就需要向mysql的3306端口发送
心跳,所以需要保证在开机自启动时,keepalived一定要在mysql启动之后再启动!
如何查看一个自启动服务在开机时的启动顺序?
所有自启动的开机服务,都会在/etc/init.d下生成一个启动脚本!
例如mysql的开机自启动脚本就在 /etc/init.d/mysql
chkconfig: 2345(启动级别,-代表全级别) 64(开机的启动的顺序,号小的先启动) 36(关机时服务停止的顺序)
例如keepalived的开机自启动脚本就在 /etc/init.d/keepalived
chkconfig: - 86 14
64<86
7.4 hive配置
六、配置hive
1.配置
保证环境变量中有JAVA_HOME,HADOOP_HOME,HIVE_HOME即可
2.配置hive的元数据存储在mysql中
①拷贝Mysql的驱动到 $HIVE_HOME/lib中
②编辑hive-site.xml文件,配置元数据的存储位置
③metastore的库的编码必须为latin1
8 安装Tez
①解压缩,将tez的tar包上传到hdfs
②在$HIVE_HOME/conf/中,编写tez-site.xml
③编写$HIVE_HOME/conf/hive-site.xml
④编写$HIVE_HOME/conf/hive-env.sh,让hive启动时,加载tez的jar包
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
⑤编写yarn-site.xml,并分发,关闭虚拟内存检查
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
hadoop fs -mkdir /tez
hadoop fs -put /opt/software/apache-tez-0.9.1-bin.tar.gz/ /tez
tar -zxvf apache-tez-0.9.1-bin.tar.gz -C /opt/module
mv apache-tez-0.9.1-bin/ tez-0.9.1
vim tez-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/apache-tez-0.9.1-bin.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.history.logging.service.class</name> <value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value>
</property>
</configuration>
vim hive-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directory
export HADOOP_HOME=/opt/module/hadoop-2.7.2
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/opt/module/hive/conf
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
export TEZ_HOME=/opt/module/tez-0.9.1 #是你的tez的解压目录
export TEZ_JARS=""
for jar in `ls $TEZ_HOME |grep jar`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar
done
for jar in `ls $TEZ_HOME/lib`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar
done
export HIVE_AUX_JARS_PATH=/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar$TEZ_JARS