hadoop学习之路(4)
1.hdfs的文件操作
1.1创建maven项目


<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.zs</groupId> <artifactId>HDFS</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>RELEASE</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.2</version> </dependency> <!-- <dependency>--> <!-- <groupId>jdk.tools</groupId>--> <!-- <artifactId>jdk.tools</artifactId>--> <!-- <version>1.8</version>--> <!-- <scope>system</scope>--> <!-- <systemPath>D:/install/Java/jdk1.8.0_281/lib/tools.jar</systemPath>--> <!-- </dependency>--> </dependencies> </project>
1.2配置core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop101:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property> <!-- 客戶端使用--> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>
1.3添加log4j配置文件
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
1.4添加hdfs测试类
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; /** * @Author: layman * @Date:Create:in 2021/3/7 10:34 * @Description: */ public class TestHDFS { private FileSystem fs; Configuration conf = new Configuration(); @Before public void init() throws IOException, URISyntaxException { fs = FileSystem.get(new URI("hdfs://hadoop101:9000"), conf); } @After public void close() throws IOException { if (fs != null) { fs.close(); } } @Test public void testMkdir() throws IOException, InterruptedException, URISyntaxException { System.out.println(fs.getClass().getName()); fs.mkdirs(new Path("/idea1")); fs.close(); } // 上传文件 @Test public void testUpload() throws IOException { fs.copyFromLocalFile(false, true, new Path("D:\\idea_workplace\\hadoop\\HDFS\\jdk-8u241-linux-x64.tar.gz"), new Path("/")); } @Test public void testDownload() throws IOException { fs.copyToLocalFile(false, new Path("/wcinput"), new Path("D:/idea_workplace/hadoop/HDFS"), true); } @Test public void testDelete() throws IOException { fs.delete(new Path("/idea1"), true); } @Test public void testRename() throws IOException { fs.rename(new Path("/idea"), new Path("/ideaDir")); } @Test public void testIfPathExits() throws IOException { System.out.println(fs.exists(new Path("/ideaDir"))); System.out.println(fs.exists(new Path("/idea"))); } @Test public void testDirorFile() throws IOException { Path path = new Path("/ideaDir"); // System.out.println(fs.isDirectory(path)); // System.out.println(fs.isFile(path)); FileStatus fileStatus = fs.getFileStatus(path); FileStatus[] fileStatuses = fs.listStatus(new Path("/wcoutput")); for (FileStatus status : fileStatuses) { Path path1 = status.getPath(); System.out.println(path1 + "目录:" + fileStatus.isDirectory()); System.out.println(path1 + "文件:" + fileStatus.isFile()); } // System.out.println("目录:"+fileStatus.isDirectory()); // System.out.println("文件:"+fileStatus.isFile()); } @Test public void testGetBlock() throws IOException { Path path = new Path("/jdk-8u241-linux-x64.tar.gz"); RemoteIterator<LocatedFileStatus> status = fs.listLocatedStatus(path); while (status.hasNext()) { LocatedFileStatus locatedFileStatus = status.next(); System.out.println(locatedFileStatus); BlockLocation[] blockLocations = locatedFileStatus.getBlockLocations(); for (BlockLocation blockLocation : blockLocations) { System.out.println(blockLocation); } } } }

为了区分bash和java代码,将用户名设置为本机和layman,设置执行权限
2.MR
1-3不变
2.4编写MR程序
2.4
package com.zs.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * @Author: layman * @Date:Create:in 2021/3/7 16:38 * @Description: */ public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private Text out_key = new Text(); private IntWritable out_value = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { System.out.println("keyin:" + key + "keyout:" + value); String[] words = value.toString().split("\t"); for (String word : words) { out_key.set(word); context.write(out_key, out_value); } } }
package com.zs.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * @Author: layman * @Date:Create:in 2021/3/7 16:56 * @Description: */ public class WCReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable out_value = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } out_value.set(sum); context.write(key, out_value); } }
设置文件测试utf-8,不选utf-8-BOM,否则是按行的效果计算
package com.zs.wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; /** * @Author: layman * @Date:Create:in 2021/3/7 17:03 * @Description: */ public class WCDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException { // Path inputPath = new Path("D:/idea_workplace/hadoop/MapReduce/mrinput"); // Path outputPath = new Path("D:/idea_workplace/hadoop/MapReduce/mroutput"); Path inputPath = new Path("/input/mrinput"); Path outputPath = new Path("/output/mroutput"); Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://hadoop101:9000"); FileSystem fs = FileSystem.get(conf); if (fs.exists(outputPath)) { fs.delete(outputPath, true); } Job job = Job.getInstance(conf); job.setJobName("wordcout"); job.setMapperClass(WCMapper.class); job.setReducerClass(WCReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, inputPath); FileOutputFormat.setOutputPath(job, outputPath); job.waitForCompletion(true); } }

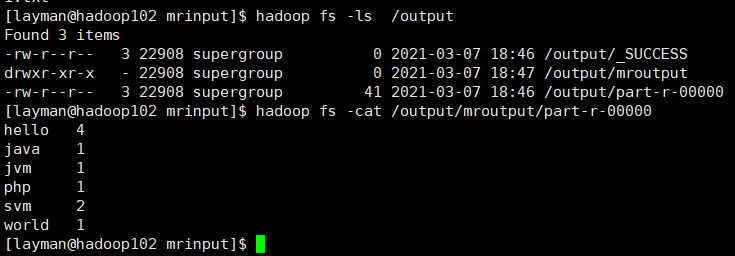

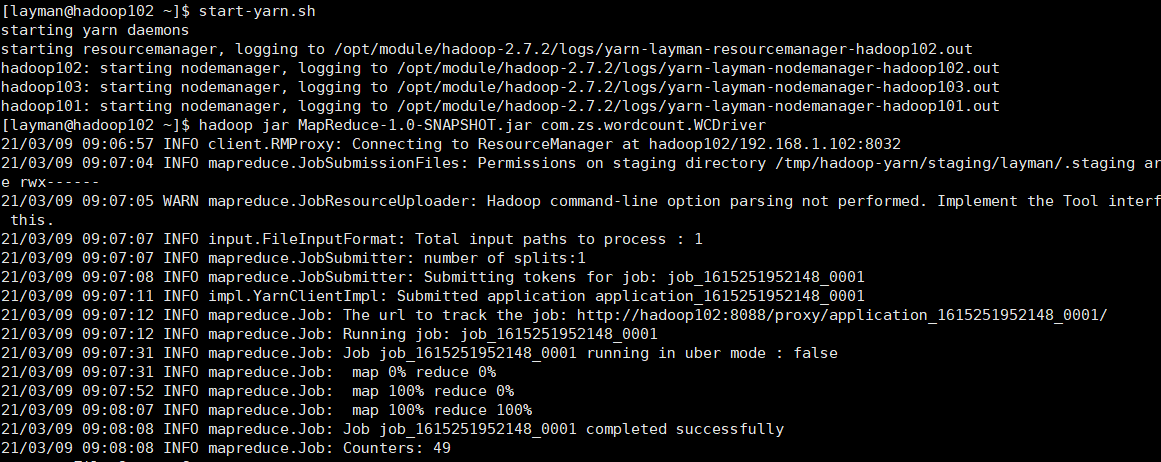
2.5使用yarn
package com.zs.wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; /** * @Author: layman * @Date:Create:in 2021/3/7 17:03 * @Description: */ public class WCDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException { // Path inputPath = new Path("D:/idea_workplace/hadoop/MapReduce/mrinput"); // Path outputPath = new Path("D:/idea_workplace/hadoop/MapReduce/mroutput"); // 配置hdfs分布式计算 Path inputPath = new Path("/input/mrinput"); Path outputPath = new Path("/output/mroutput"); Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://hadoop101:9000"); // 配置yarn conf.set("mapreduce.framework.name","yarn"); conf.set("yarn.resourcemanager.hostname","hadoop102"); FileSystem fs = FileSystem.get(conf); if (fs.exists(outputPath)) { fs.delete(outputPath, true); } Job job = Job.getInstance(conf); // job.setJar("MapReduce-1.0-SNAPSHOT.jar"); job.setJarByClass(WCDriver.class); job.setJobName("wordcout"); job.setMapperClass(WCMapper.class); job.setReducerClass(WCReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, inputPath); FileOutputFormat.setOutputPath(job, outputPath); job.waitForCompletion(true); } }
由于Windows中不存在/bin/bash文件夹,无法执行当前代码,因此需要打包jar并指定主类名,使用hadoop命令时需要指定job的jar位置


 浙公网安备 33010602011771号
浙公网安备 33010602011771号