
hadoop学习之路(3)
重新系统化学习hadoop
虽然官方对centos6已经停止维护,但还是硬着头皮沿用之前的centos6,并解决了一点小疑惑.
1.修改ip地址的文件
/etc/sysconfig/network-scripts/ifcfg-eth0
2.修改主机名的文件
/etc/sysconfig/network
3.主机映射文件
/etc/hosts
4.防火墙
service iptables status #状态
service iptables stop #关闭防火墙
chkconfig iptables off #防止开机自启
5.复制克隆主机,并保持时间同步ntp,建议ntp1.aliyun.com
centos6的yum安装异常报错
All mirror URLs are not using ftp, http[s] or file.换镜像,此处参考https://www.jianshu.com/p/70e9dcf61ef9已解决sed -i "s|enabled=1|enabled=0|g" /etc/yum/pluginconf.d/fastestmirror.conf mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup curl -o /etc/yum.repos.d/CentOS-Base.repo https://www.xmpan.com/Centos-6-Vault-Aliyun.repo yum clean all yum makecache
6.安装jdk,hadoop,配置JAVA_HOME,HADOOP_HOME,并将它们申明为全局变量,并配置到PATH

7.配置用户bashrc,添加source /etc/profile,添加ssh免密登录
8.配置同步,以及在集群的所有机器上批量执行同一条命令


#!/bin/bash #校验参数是否合法 if(($#==0)) then echo 请输入要分发的文件! exit; fi #获取分发文件的绝对路径 dirpath=$(cd `dirname $1`; pwd -P) filename=`basename $1` echo 要分发的文件的路径是:$dirpath/$filename #循环执行rsync分发文件到集群的每条机器 for((i=101;i<=103;i++)) do echo ---------------------hadoop$i--------------------- rsync -rvlt $dirpath/$filename layman@hadoop$i:$dirpath done
#!/bin/bash #在集群的所有机器上批量执行同一条命令 if(($#==0)) then echo 请输入您要操作的命令! exit fi echo 要执行的命令是$* #循环执行此命令 for((i=101;i<=103;i++)) do echo ---------------------hadoop$i----------------- ssh hadoop$i $* done
并添加以上bash有执行权限,放到用户可执行的目录,如~/bin
9.安装如下配置集群
修改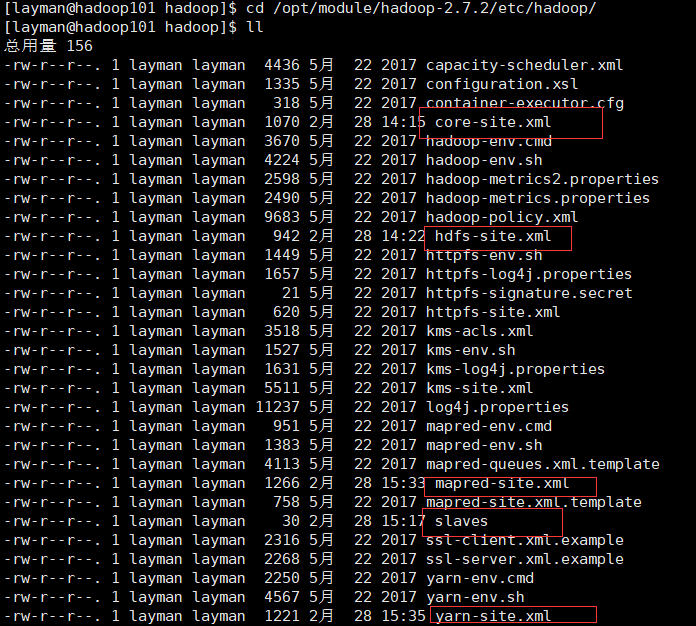 并按照ResourceManager的位置执行批处理的上面自主编写的两个脚本,启动yarn和dfs启动脚本,history
并按照ResourceManager的位置执行批处理的上面自主编写的两个脚本,启动yarn和dfs启动脚本,history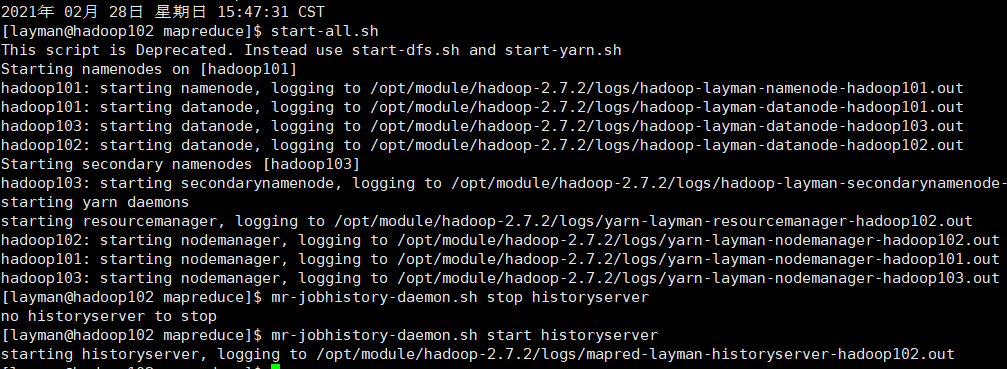
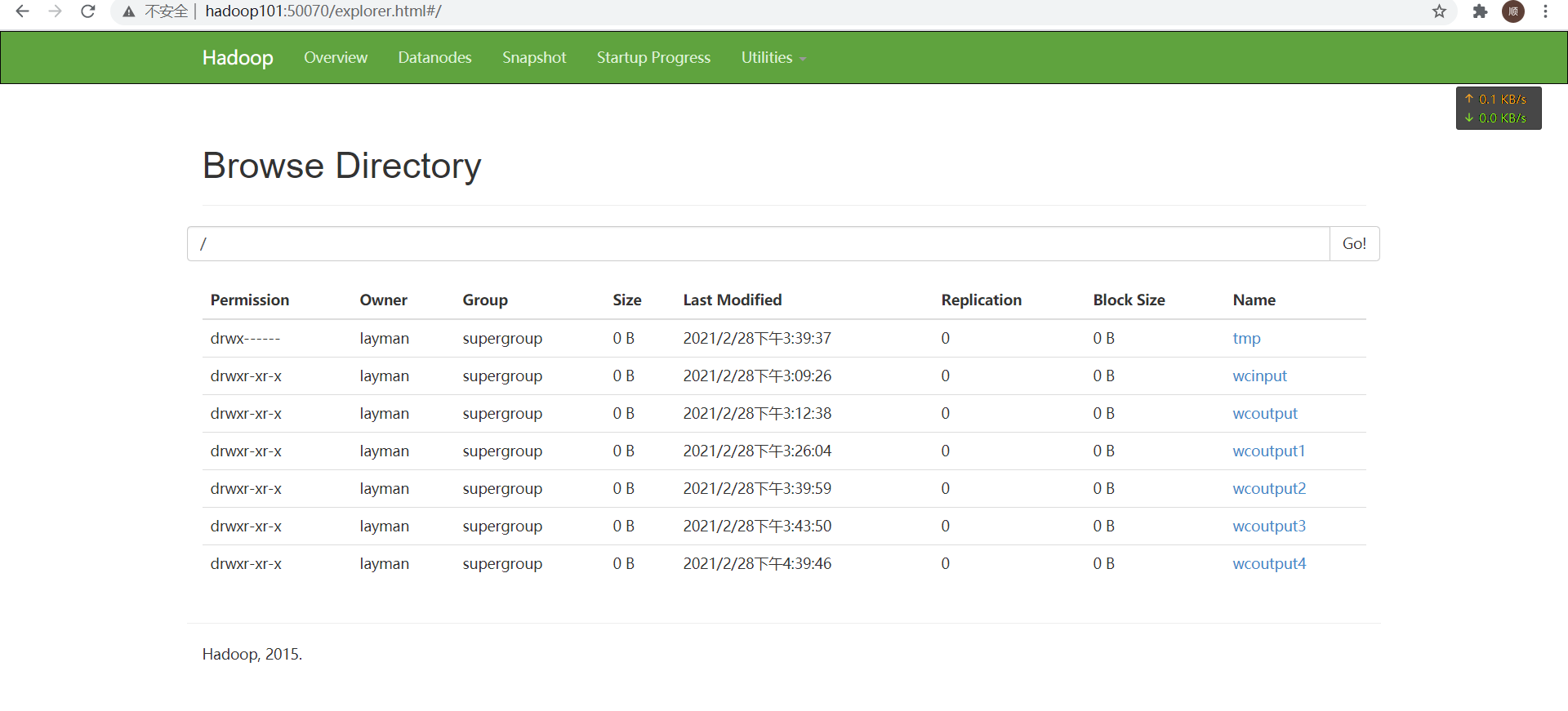
并进行测试工作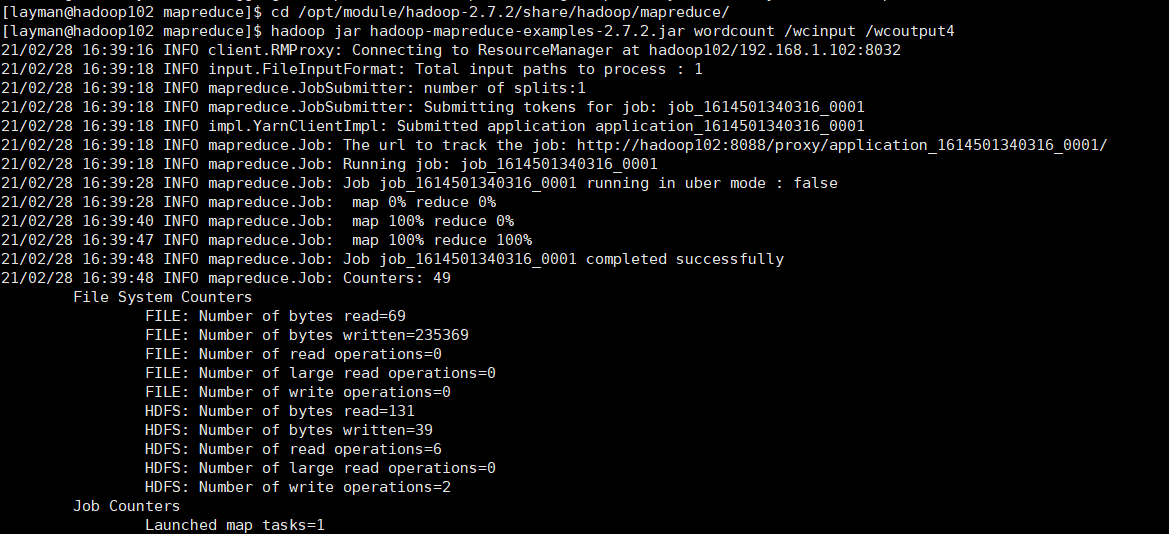

以上皆为学习笔记,仅供个人回忆
