大数据基础---数据存储发展史
一个文明的发展离不开数据,数据包括我们看到的,听到的,只要能存储的东西都称之为数据。
在没有计算机之前,我们只能通过器具,骨头,纸制品来进行存储。这些介质也限制了我们只能存储文字和手工绘画,我们一起来看看古代都有哪些存储介质:
一.古代的存储介质
1.1甲骨文
现存中国最早的文字,大多是书写或契刻在兽骨和龟甲上的刻辞。甲骨文字是从公元前14世纪后期盘庚十四年迁都安阳后,到公元前11世纪中叶帝辛灭亡前这一时期的记录。
1.2金文和陶文
金文通常记载于彝器、乐器、兵器、度量衡、镜、钱币、印章之上,其中以彝器所载文字最长。
较早期的铜器,无论是圆形或方形,三足或四足,铭文大多铸在器物的内部。
金文的字汇不比甲骨文为多。根据容庚的《金文编》和《续编》,周代和周代以前的金文,今日可以通读的越有1800多字,不可通读的约有1200字;秦、汉的金文,可读的将近1000字,不可读的有300余字。
1.3玉石刻辞
秦汉以后,石刻逐渐取代额咯青铜器在记功、追远等方面的用途。
1.4竹简和木牍
竹简和木牍是中国最早的书写材料。在中国传统文化上,简牍制度有其极为重要和深远的影响。不仅中国文字直行书写和自右至左的排列顺序渊源于此,即是在印刷术发明以后,中国书籍的单位、术语,以及版面上的所谓“行格”的形式,也是根源于简牍制度而来。
1.5帛书
到了殷商时代,甲骨卜辞中常见“丝”、“蚕”、“帛”、“桑”等字。在安阳殷墟中发现的丝帛残迹,经过仔细的研究,证明殷人的纺织技术已很进步。在长沙和其它几处楚墓中,新近发现许多丝帛遗物,证明在战国、汉初不仅已有精美的缣帛,而且还有花纹复杂的织锦和刺绣。
1.6纸卷
东汉元兴元年(公元105年),蔡伦将制纸方法奏闻和帝 ,开启了纸质时代。
随着人类文明的进步,迎来了电子时代,我们可以通过键盘录入文字,还可以将视频图片音频上传到网站,另外还有一些信息采集器,比如摄像头,遥感,这些信息都会源源不断的保存到服务器里面,我们仅仅通过一部手机就可以浏览巨量的信息,随着数据的增加,存储的方式也在悄悄改变!
二.现代的存储介质
2.1文件存储
最开始公司个人仅仅通过word,excel,ppt就能记录一些信息。但是随着数据的增多,这样的存储维护起来需要耗费很大的精力,而且不便于查询和搜索。于是产生了关系型数据库。
2.2关系型数据库
关系型数据库包括了SqlSerer,Oracle,MySql。它们通过把现实的物品抽象化,比如记录书籍就抽象成作者,文章标题,文章内容,文章图片等关键属性,这些属性构成一个个结构存储到数据库中。叫关系型数据库的原因是各个物品之前,属性之前都是有关联的,就像人,不可能独立存在。
随着数据的增加,关系型数据库的缺点也渐渐暴露无遗,首先看下它的结构:
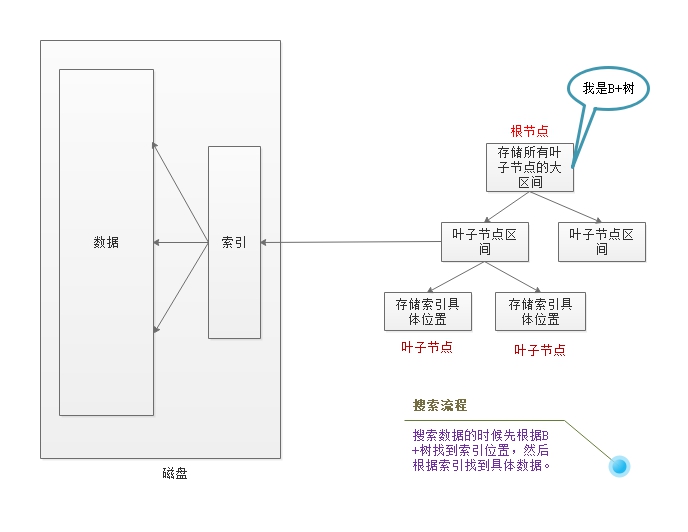
(关系型数据库搜索流程图)
从上图可以看到,关系型数据库为了提高查询速度使用了B+树,大大提高了查询速度,但是这也带来了一个问题就是B+树存储在内存中,索引存储在磁盘中,这样查询就会进行内存和磁盘交互,带来了一定的瓶颈。
再一个随着大数据的到来,这种结构化数据因为耦合性大,不利于扩展分布式部署,查询缓慢,所以催生了非关系型数据库的发展。
关系型数据库中的事物遵循ACID原则:
A代表原子性:比如张三给李四转账,这整个事情要不全部成功,要么全部失败,不能出现张三转过去了,李四没收到。
C代表一致性:这个理解的不深刻,大概意思就是保证结果相同,一般像分布式部署,我们查询的结果要一致。
I代表独立性:事物之间是独立的,也就是事物可以嵌套事物,里面的事物执行成功并提交了,那么这个结果就改变了,无论外面的这个事物是否成功,即使失败也不影响内部事物。
D代表持久性:修改的数据都会存在磁盘里面,这样的数据即使重启也不会像内存似的丢失数据。
2.3非关系型数据库
非关系型数据库顾名思义,它的数据之间是没有直接关系的,这对于数据的压缩,分布式部署提供了便利。同时也提高了查询速度。
数据库分为了键值对数据库,列族数据库,文档型数据库还有图形数据库,如下所示:
| 分类 | 相关产品 | 应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值数据库 | Redis、Riak | 内容缓存,如会话、配置文件、参数等; 频繁读写、拥有简单数据模型的应用 | <key,value> 键值对,通过散列表来实现 | 扩展性好,灵活性好,大量操作时性能高 | 数据无结构化,通常只被当做字符串或者二进制数据,只能通过键来查询值 |
| 列族数据库 | Bigtable、HBase、Cassandra | 分布式数据存储与管理 | 以列族式存储,将同一列数据存在一起 | 可扩展性强,查找速度快,复杂性低 | 功能局限,不支持事务的强一致性 |
| 文档数据库 | MongoDB、CouchDB | Web 应用,存储面向文档或类似半结构化的数据 | <key,value> value 是 JSON 结构的文档 | 数据结构灵活,可以根据 value 构建索引 | 缺乏统一查询语法 |
| 图形数据库 | Neo4j、InfoGrid | 社交网络、推荐系统,专注构建关系图谱 | 图结构 | 支持复杂的图形算法 | 复杂性高,只能支持一定的数据规模 |
非关系型数据库分布式符合CAP原则。
C是一致性:相同的查询语句,在不同的机器上执行,得到的结果相同。
A是可用性:查询的服务器是可用的 ,无论是返回成功也好,失败也好。
P是分区容错性:服务器之间是可以通信的,并且都通讯顺畅。
系列传送门
本文来自博客园,作者:数据驱动,转载请注明原文链接:https://www.cnblogs.com/shun7man/p/12463294.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号