大数据基础---流式计算简介
1.流式计算是什么?
流式计算是相对于批处理来说的,我们以前学的Mapreduce就是批处理,它属于离线计算,计算的数据都是过去某个时间点的,还有我们开发的软件管理系统,查询的也是过去某个时刻录入的数据。那么流式计算呢,它是在输入录入的时候就开始计算了,而且计算的速度还很快,可以达到毫秒级,计算完成后就能实时反馈了,或者存储起来。这样的计算一般针对的是交通啊,电商啊,天气啊等要求实时推送的场景。
2.都有哪些流式计算
常见流式框架包括Storm,Spark Streaming,Samza,Flink。
| 名称 | 公司 | 适用场景 | 类型 |
|---|---|---|---|
| Storm | 流处理 | 流式计算 | |
| Spark Streaming | Apache | 适合离线计算和实时计算同时需要的。 | 混合计算 |
| Samza | 结合Kafka和Spark的流处理 | 流式计算 | |
| Flink | Apache | 快速的处理 | 混合计算 |
| Hadoop(这个不包括) | Apache | 离线计算 |
3.几种流式计算的结构差异
Storm架构
 211
211
Spark Streaming架构

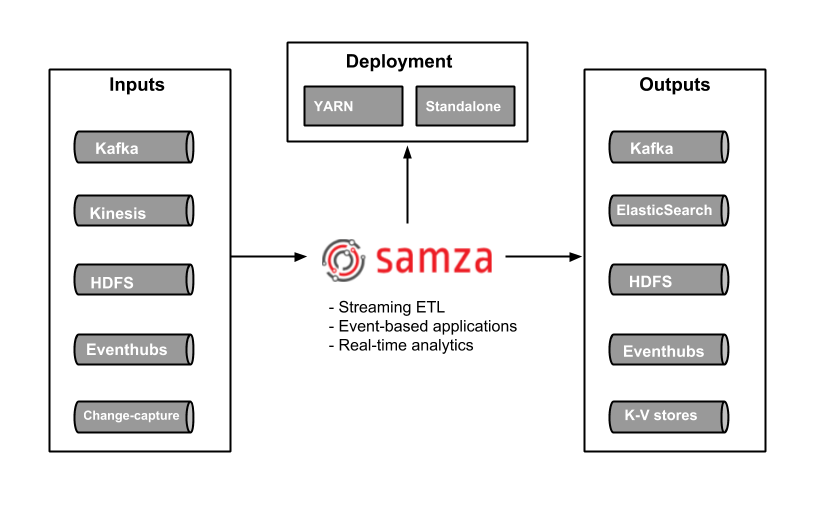
Samza架构
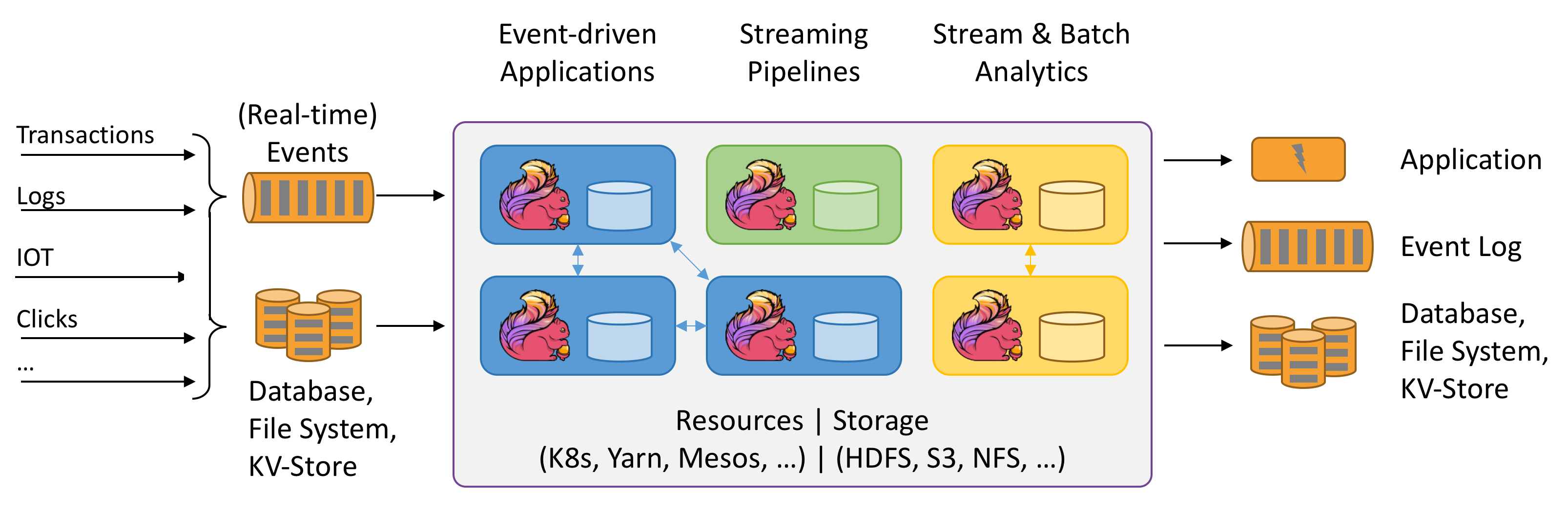
Flink架构
本文来自博客园,作者:数据驱动,转载请注明原文链接:https://www.cnblogs.com/shun7man/p/12392736.html

