大数据基础---Hive的搭建
本博客主要介绍Hive和MySql的搭建:
学习视频一天就讲完了,我看完了自己搭建MySql遇到了一堆坑,然后花了快两天才解决完,终于把MySql搭建好了。然后又去搭建Hive,又遇到了很多坑,就这样一直解决问题,加上网上搜索和个人排查检查日志。搜索百度,百度不行搜索Bing,看了csdn,看strackflow,最后终于功夫不负有心人,成功把MySql和Hive跑起来了。这里我将还原最初状态,并把遇到的坑一并记录下,同时防止后人采坑。
搭建环境:
Centos7,MySql14.14,Hive2.3.6
搭建MySql:
搭建步骤我参考的菜鸟教程: https://www.runoob.com/mysql/mysql-install.html
参考上述步骤搭建遇到的坑:
坑1:安装完后,给root用户设置密码后,使用账户和密码登陆报了ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)错误,解决方案点击。
搭建Hive:
搭建步骤我参考的: https://www.cnblogs.com/dxxblog/p/8193967.html
参考上述步骤遇到的坑:启动hive抛出Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D异常,解决方案点击。
操作Hive:
先说下环境的坑:
坑1:当我在Hive中执行查询操作没问题,但是当删除表结构的时候会抛出如下异常 :
执行drop table tableName;
Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:For direct MetaStore DB connections, we don't support retries at the client level.)
这句话的意思是不支持此操作,并不是SQL写错了。 这个问题的原因是之前我们在hive的lib中添加的mysql-connection-java.jar(使用JDBC操作MySql的包)版本不对,我之前用的mysql-connection-java-5.1.18.jar,后来改为了mysql-connection-java-5.1.47.jar就好了。
如果您的也不对,请及时替换,包连接
案例1(在Hive中创建内部表):
在Linux系统找个位置创建visits.txt和visits.hive文件:
在visits.txt文件里面加入如下内容,中间是以\t 分割的
一明 18701223481 北京市朝阳区 毒逆天 18498778212 江苏省苏州市 海面贝贝 15099334981 上海市闵行区
在visits.hive加入创建数据库命令
create table people_visits ( user_name string, phone string, address string ) row format delimited fields terminated by '\t';
在hive里面创建people_visits表
hive -f visits.hive
然后在hive中使用show tables; 就能看到这个表了。 但是数据是空的。接下来使用命令将visits.txt文件数据提交到hdfs再查询就能看到数据了。
hadoop fs -put visits.txt /user/hive/warehouse/people_visits

使用web浏览也可以看到上传的文件:

案例2:(在hive中创建外部表)
在Linux本地找个文件夹创建externalHive.txt文件
cd /data/
touch externalHive.txt
编辑文件加入以下内容
vim externalHive.txt
西红柿 11 桃子 22
注意:(上面字符使用tab键分割)
在hdfs里面新建一个hivetest文件夹
hadoop fs -mkdir /user/root/hivetest
将文件上传到hdfs
hadoop fs -put externalHive.txt /user
进入Hive创建一个价格外部表
hive
create external table priceVisits ( name string, price int ) row format delimited fields terminated by '\t' location '/user/root/hivetest'; --指定表所在路径
将数据上传到priceVisits表里面
hive
load data inpath '/user/externalHive.txt' into table priceVisits;
PS:(上面的命令执行完后,user目录下的externalHive.txt就会移动到创建table时指定的目录下面)
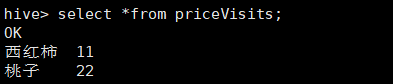
查询priceVisits表就可以看到数据了
select *from priceVisits;
删除priceVisits表:
drop table priceVisits;
可以看到表删除了,但是数据还没删除,这就是外部表的作用


上面的查询并没有用到MapReduce计算,仅仅使用了简单的本地查询,这是因为我们没有写聚合语句,不需要MapReduce。
DDL操作语句参考: https://www.cnblogs.com/shun7man/p/13172313.html
本文来自博客园,作者:数据驱动,转载请注明原文链接:https://www.cnblogs.com/shun7man/p/11821811.html

