大数据基础---HDFS-API
第一步:创建一个新的项目 并导入需要的jar包
公共核心包
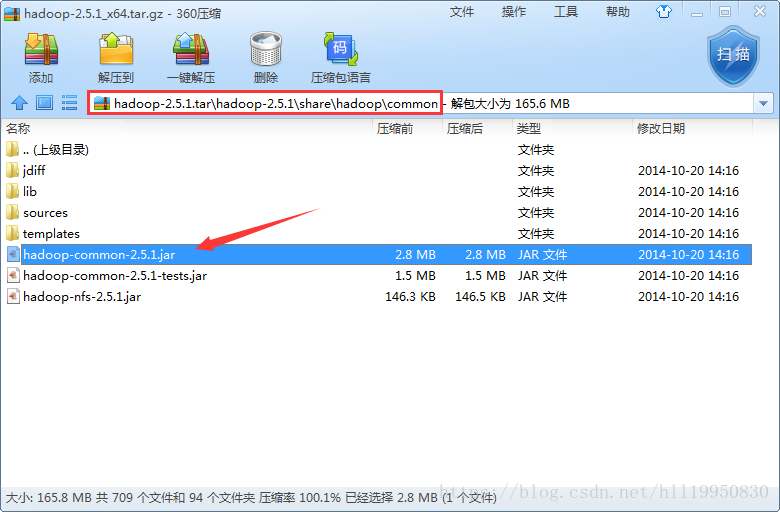
公共依赖包

hdfs核心包

hdfs依赖包
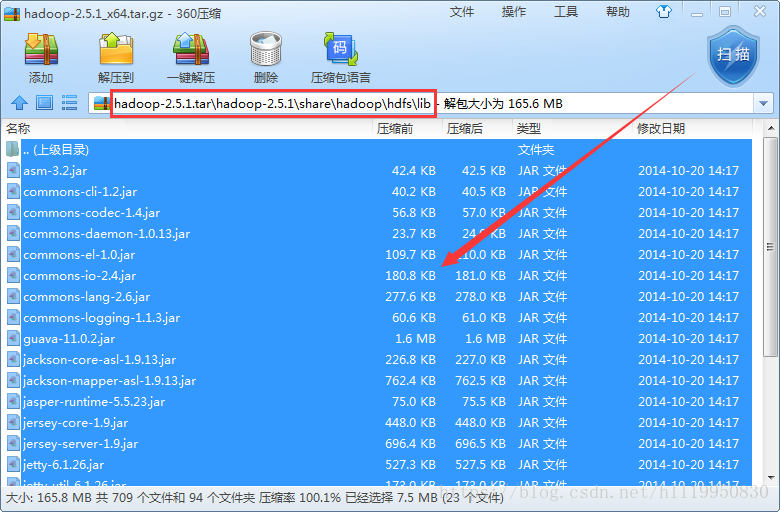
第二步:将Linux中hadoop的配置文件拷贝到项目的src目录下

第三步:配置windows本地的hadoop环境变量(HADOOP_HOME:hadoop的安装目录 Path:在后面添加hadoop下的bin目录)
第四步:使用windows下编译好的hadoop替换hadoop的bin目录和lib目录
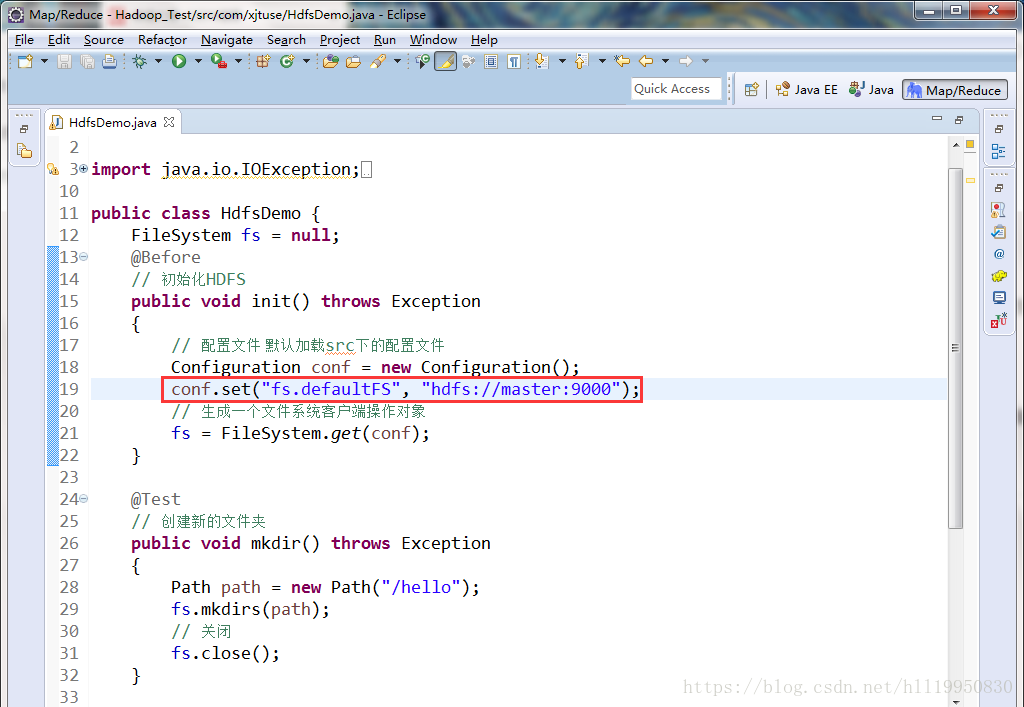
第五步:使用FileSystem对象对hdfs进行操作(注意:FileSystem默认是本地文件系统 因此要通过Configuration对象配置为hdfs系统)
第六步:在运行之前 需要保证本地的用户名和hadoop的用户名一致 在不修改windows用户名的情况下 可以配置Eclipse的参数实现:右击项目->Run As ->Run Configurations
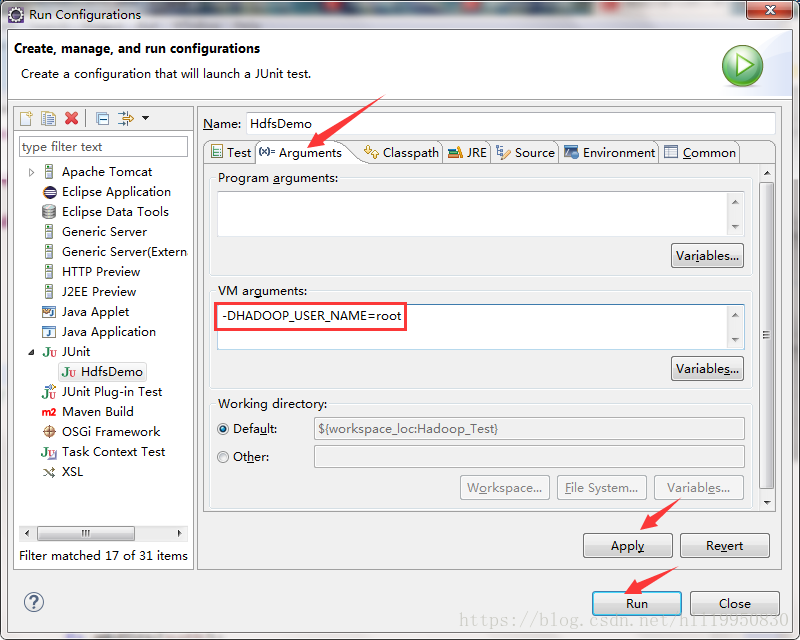
运行即可成功上传本地文件到hdfs
代码如下:
package com.xjtuse;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Before;
import org.junit.Test;
public class HdfsDemo {
FileSystem fs = null;
@Before
// 初始化HDFS
public void init() throws Exception
{
// 配置文件 默认加载src下的配置文件
Configuration conf = new Configuration();
// conf.set("fs.defaultFS", "hdfs://master:9000");
// 生成一个文件系统客户端操作对象
// fs = FileSystem.get(conf);
// 第一个参数是URI指明了是hdfs文件系统 第二个参数是配置文件 第三个参数是指定用户名 需要与hadoop用户名保持一致
fs = FileSystem.get(new URI("hdfs://master:9000"), conf, "root");
}
@Test
// 创建新的文件夹
public void mkdir() throws Exception
{
Path path = new Path("/hello");
fs.mkdirs(path);
// 关闭
fs.close();
}
@Test
// 上传文件
public void upload() throws Exception
{
// 第一个参数是本地windows下的文件路径 第二个参数是hdfs的文件路径
fs.copyFromLocalFile(new Path("F:/Files/data/README.txt"), new Path("/"));
// 关闭
fs.close();
}
}
转自: https://blog.csdn.net/hll19950830/article/details/79824928
补充:最后我们运行可能报如下异常。

这个时候在项目根目录下创建一个文件命名为log4j.properties并填写如下内容,然后重新运行就好了。
hadoop.root.logger=DEBUG, console
log4j.rootLogger = DEBUG, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
有的时候我们新建文件的时候选择File->New没有选择文件这个选项,这个时候不用着急,它给隐藏了,找到Window->Perspective->Customize Perspective 勾选上File即可。
更多内容参阅官方API文档。
本文来自博客园,作者:数据驱动,转载请注明原文链接:https://www.cnblogs.com/shun7man/p/11759363.html

