Jmeter之response乱码
问题:
使用Jmeter过程中需要查看结果树,但是发现里面的response数据有乱码:
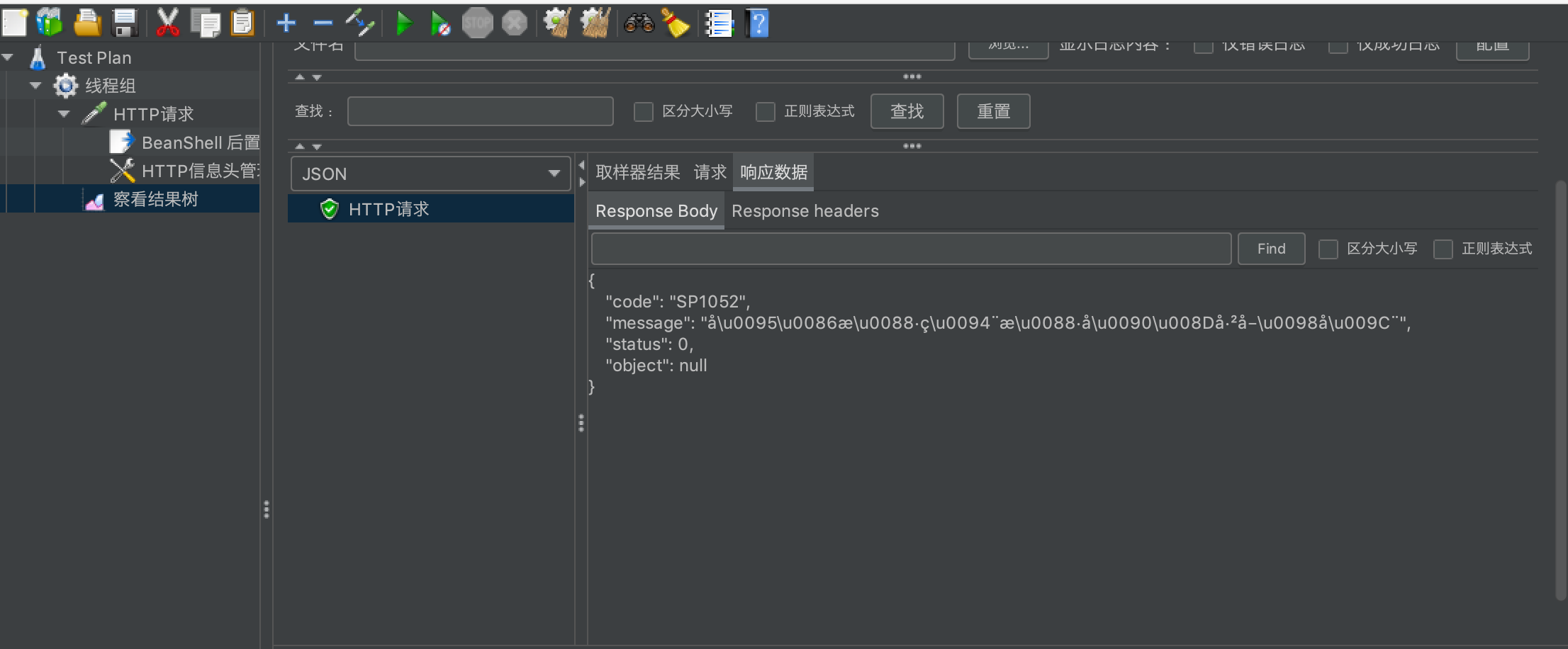
分析:
Jmeter的结果处理编码与被测试对象的编码不一致;
1 Jmeter的sampler请求结果的默认编码方式为:ISO-8859-1(不支持中文);
2 被测对象的结果编码可能是gbk、UTF-8;
处理:
1 使用后置控制器"BeanShell PostProcessor"来动态修改结果处理编码,使之与被测对象保持一致;
优点:灵活,随时修改;
缺点:要根据不同的对象设置不同的编码,
适用范围:测试不同的公司项目,有些公司喜欢GBK,有些事UTF-8;
2 修改Jmeter的默认编码;
优点:一次修改,长久使用;
缺点:如果要测试不同的公司项目,需要多次修改,较麻烦;
使用范围:测试本公司的项目,毕竟同一个公司的项目基本上都是使用同一个编码的;
那么就很明确了,大家可以根据自己的需要来设置
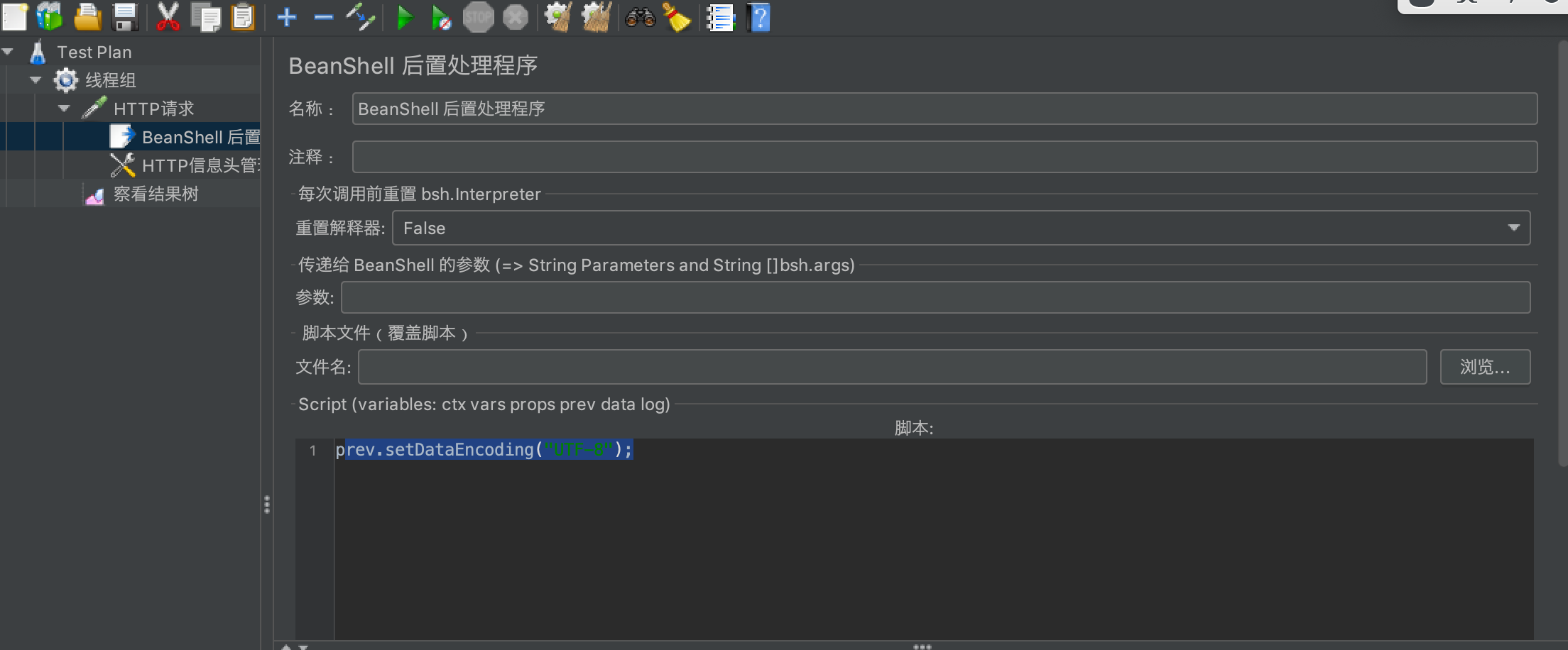
1、使用后置控制器"BeanShell PostProcessor":在请求下添加BeanShell PostProcessor,在“Script”中增加“prev.setDataEncoding("UTF-8");”
1.1 通过查看网页的源文件或者开发可知 编码格式;
1.2 prev.setDataEncoding("UTF-8");
2 修改Jmeter的默认编码
2.1 进入%JmeterHome%/bin,找到Jmeter.properties,并打开;
2.2 搜索“sampleresult”,找到sampler的编码设置代码;
2.3 修改编码为“UTF-8”,去掉“#”(注释符号),保存设置,并重启Jmeter;
2.4 验证是否解决,如下图(无BeanShell PostProcessor),已成功处理;
扩展
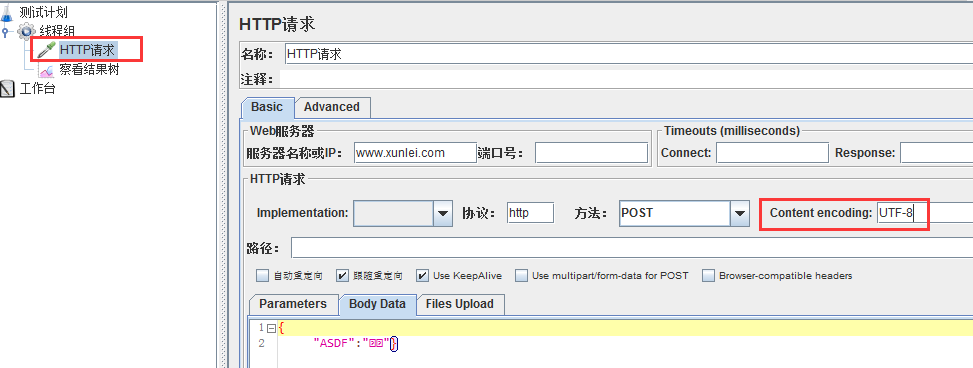
1 向服务器发送的post请求中存在乱码(一般是中文)时,可在请求中设置content-encoding,如UTF-8;
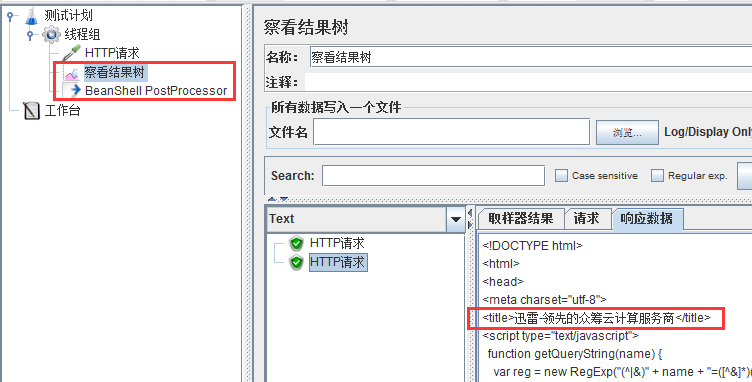
2 “BeanShell PostProcessor”一定要设置在http请求中么?
答:不是,后置处理器在监听器之前处理(如不知道元件的作用域与执行顺序请自行Google,我后面有时间再整理一份),所以只要在作用域内,后置处理器放哪里都是同样的效果;
如下图:
转自:https://www.cnblogs.com/longronglang/p/10218827.html
本文来自博客园,作者:术科术,转载请注明原文链接:https://www.cnblogs.com/shukeshu/p/14696769.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号